
커리큘럼
- 응용 SW 기초기술 활용 -> Java
- 프로그래밍 언어활용 -> Java
- 데이터베이스 구현 -> DB
- SQL 활용 -> DB
- SQL 응용 -> DB
- 웹 표준 기술 -> FE
- 웹 서버프로그램 구현 ->네트워크, 서블릿, jsp
- 프레임워크 프로그래밍 -> Spring, JUnit, Mokito
- 클라우드 응용 서비스 개발을 위한 AWS 이해 및 응용 -> 배포
- 안드로이드 프로그래밍 ->Kotlin
- Python 프로그래밍 -> Python
- Python 분석 라이브러리 활용 -> Python
- 요구사항 확인
- 애플리케이션 테스트 수행
JDK 설치(Mac OS)

Zulu OpenJDK 다운로드 페이지에 접속합니다. Java Version과 Operating System, Architecture를 선택합니다. MacOS M1은 Architecture에서 ARM 64-bit를 선택하고 MacOS Intel은 x86 64-bit을 선택해 줍니다. 선택을 모두 완료했다면 ‘.dmg’ 버튼을 눌러 다운로드합니다.

설치가 완료되면 위와 같은 창이 나타납니다. 닫기 버튼을 눌러 설치 창을 종료합니다.
터미널 창에 java를 입력해 보세요. 아래와 같은 실행 결과를 확인할 수 있습니다.

IntelliJ 설치(Mac OS)
’IntelliJ’를 검색하여 다운로드 페이지로 이동합니다.

Ultimate 버전은 유료 버전이고, 지원하는 기능이 더 많습니다. 하지만 학습용으로는 Community 버전도 충분하기 때문에 우리는 Community 버전을 사용합니다. MacOS Intel 칩과 M1(Apple Silicon) 칩에 맞게 선택하고 다운로드합니다.

다운로드한 파일을 실행하고, 인텔리제이 아이콘을 애플리케이션 폴더에 드래그해 설치해 줍니다.

Java 개요
왜 자바를 배워야 하나요?
자바는 1996년 1월에 세상에 나온 객체지향 프로그래밍(Object Oriented Programming, OOP) 언어입니다.
운영체제에 독립적으로 실행이 가능하기 때문에, Write Once, Run Anywhere이라는 슬로건을 내세워 빠르게 많은 사용자를 확보했습니다. 다양한 운영체제가 공존하는 웹 환경에 적합한 언어로서, 현재까지도 전 세계에서 많이 쓰이는 인기 있는 언어입니다.

TIOBE의 자료에 따르면, 자바가 오랜 기간 상위권을 유지했음을 확인할 수 있습니다.
특별히 국내에서 자바는 전자정부 프레임워크 등에 사용되면서 백엔드 개발 분야에서 가장 보편적으로 사용되고 있는 언어입니다. 첫 언어로 자바를 선택한다면, 보다 큰 시장에 뛰어드는 것과 같습니다.
자바의 특징
자바의 주요 특징은 다음과 같습니다.
1. 운영체제에 독립적
자바 이전의 언어들은 특정 CPU에서만 작동하거나 특정 OS에 따라 다르게 작성해야 하는(C, C++) 언어들이 대부분이었습니다. 자바는 이 문제를 해결하고자 JRE(Java Runtime Environment: JVM(자바 가상머신) + 표준 클래스 라이브러리)가 설치되어 있는 모든 운영체제에서 실행이 가능하도록 만들어졌습니다.
2. 객체 지향 언어(Object Oriented Programming, OOP)
자바는 객체 지향 프로그래밍 개념을 사용하는 언어입니다. 따라서 모든 기능은 객체로 만들어 사용해야 합니다. 객체는 프로그램이 동작하는 부품이라고 생각하면 됩니다. 여러 부품(객체)들을 만들고 조립하여 하나의 프로그램을 실행하는 개념이 OOP입니다. 객체 지향적으로 설계된 프로그램은 유지보수가 쉽고 확장성이 높습니다. OOP에 대해서는 이후 자바 클래스를 다루면서 보다 세밀하게 살펴보겠습니다.
3. 함수형 프로그래밍 지원
자바 8버전부터 함수형 프로그래밍을 지원하는 문법인 람다식과 스트림이 추가되었습니다. 이를 사용하면 컬렉션의 요소를 필터링, 매핑, 집계 처리하기 쉬워지고 코드가 간결해지는 장점이 있습니다. 람다식, 스트림에 대해서는 심화 유닛에서 자세히 다룹니다. 지금은 용어만 알고 넘어가도 좋습니다.
4. 자동 메모리 관리(Garbage Collection)
자바는 96년에 발표된 언어이고 C++를 개선하는 것 또한 여러 목표 중의 하나였습니다. 그래서 자바는 자동으로 메모리를 관리해 주는 기능을 추가했습니다. C, C++의 경우 메모리의 생성과 소멸을 개발자가 직접 설계해야 했지만, 자바는 가비지 컬렉터(Garbage Collector)를 실행시켜 자동으로 사용하지 않는 메모리를 수거합니다. 이를 통해 개발자는 메모리를 관리하는 수고를 덜고 핵심 코드에 집중할 수 있게 되었습니다.
JVM과 JDK
JVM(Java Virtual Machine)
자바는 컴파일러(Compiler)를 통해 기계어(Machine Language)로 변환되는 언어입니다.
컴파일이란 특정 프로그래밍 언어를 기계가 이해할 수 있는 언어로 옮기는 번역 과정으로, 여기에서는 자바 언어를 JVM(Java Virtual Machine)이 이해할 수 있는 코드(바이트코드, Bytecode)로 변환하는 것을 의미합니다. JVM은 바이트코드를 운영체제에 맞는 기계어로 변환해 줍니다.
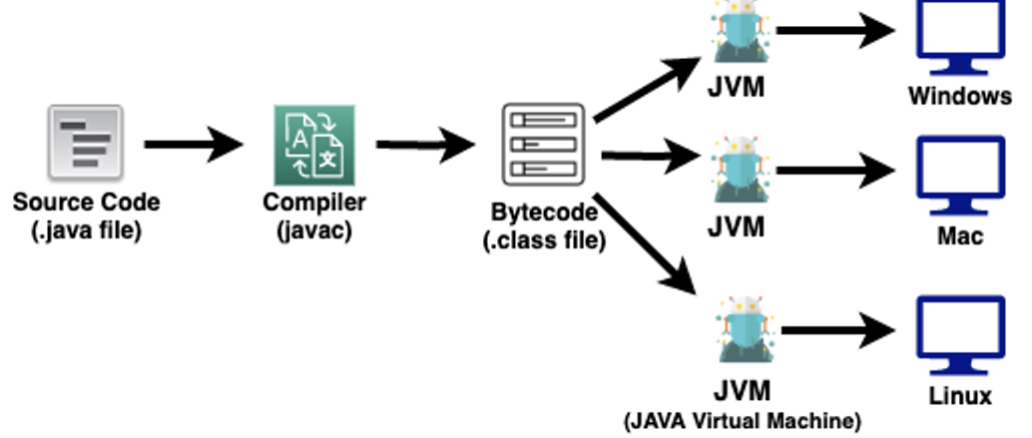
JVM은 자바 프로그램을 실행시키는 도구입니다.
자바가 운영체제에 독립적인 것은 JVM이 있기 때문에 가능합니다. JVM은 자바 코드로 작성한 프로그램을 해석해 실행하는 별도의 프로그램입니다. 즉, 프로그램을 실행하는 프로그램입니다.
프로그램이 제대로 실행되기 위해서는 컴퓨터의 다양한 자원(CPU, RAM, 각종 입출력 장치 등)을 활용해야 합니다. 이런 자원을 관리하는 것은 운영체제이므로, 프로그램은 운영체제가 정한 규칙을 따라야 합니다. 서로 다른 운영체제(Linux, Windows, MacOS 등)에서 프로그램을 실행하기 위해서는 운영체제별 규칙을 따르는 별도의 절차가 필요합니다. JVM은 이 문제를 해결해 줄 수 있습니다.
JVM의 경우 JDK나 JRE를 설치하면 자동으로 설치됩니다. 자바는 JVM을 거치기 때문에 C나 C++에 비해 속도는 느린 편입니다. 하지만 JVM 내부의 최적화된 JIT 컴파일러를 통해 속도를 크게 개선해나가고 있습니다.

JDK(Java Development Kit)
자바 설치와 관련하여, JDK와 JRE의 차이에 대해 먼저 알 필요가 있습니다. JDK와 JRE는 다음의 내용을 포함합니다.
- JRE(Java Runtime Environment) : JVM + 표준 클래스 라이브러리
- "Runtime", 즉 실행과 관련된 무언가입니다.
- JDK(Java Development Kit) : JRE + 개발에 필요한 도구
- "Development", 즉 개발과 관련된 무언가입니다.
만약 자바 프로그램을 실행만 할 것이라면 JRE만 설치해도 상관없습니다. 그러나 우리는 자바 프로그램을 개발할 것이기 때문에 JDK를 설치해야 합니다. JDK는 OracleJDK와 OpenJDK가 있습니다. 이 둘은 여러 차이가 있지만 지금은 OracleJDK는 오라클이라는 회사에서 관리하는 버전이고 OpenJDK는 오픈소스라는 것만 알아두어도 코드를 작성하는 데에는 문제가 없습니다.
JDK 버전별 특징
JDK 8
- 람다식 및 메서드 참조 도입
- 컬렉션에 Stream API 사용 가능
- 인터페이스 내부에 default 메서드 선언 가능
- Optional 클래스 도입 등
JDK 11
- String 클래스에 strip, isBlack, lines 메서드 추가
- Files 메서드에 readString 메서드 추가
- 람다식의 인수 선언 시 var 키워드 사용 가능
- 소스 파일을 javac을 통한 컴파일 없이 스크립트로 실행 가능
- 차세대 가비지 콜렉터 도입 등
JDK 17
- 텍스트 블록 추가
- 의사 난수 생성기 기능 향상
- switch 문 기능 향상
- 봉인 클래스 추가 등
JDK 11을 사용하는 이유
살펴본 것처럼 JDK에는 여러 버전이 존재하는데, 어떤 버전을 사용하는 것이 가장 좋을까요? 컴퓨터, 스마트폰처럼 새로 나온 신상 버전을 사용하는 것이 적절할까요? JDK뿐만 아니라, 개발과 관련된 툴의 버전을 선택할 때 우선적으로 고려해야 하는 가장 중요한 요소는 안정성입니다.
여러분이 취업 후에 개발 또는 유지보수할 웹 서버는 웹 서비스의 백엔드 영역을 담당하는 중요한 구성 요소입니다. 즉, 여러분이 개발한 서버를 통해 여러분이 소속된 회사의 핵심 서비스들이 사용자들에게 전달됩니다.
그런데, 만약에 웹 서버가 안정적으로 동작하지 못한다면 회사가 제공하는 서비스를 사용자들이 이용할 수 없게 됩니다. 또한, 치명적인 에러가 발생하여 데이터가 소실되거나 엉키게 되면 복구하는 데에 많은 시간과 비용이 들어갑니다. 이와 같은 상황은 회사의 수익 감소로 직결되므로, 웹 서버는 반드시 안정적으로 동작할 수 있어야 합니다.
이때, 어떤 개발 도구 버전의 안정성을 판단하는 데에 있어 중요한 고려 사항 중 하나는 다음과 같습니다.
- 해당 도구에 대해 장기적인 유지 및 보수가 보장되는가?
- 해당 도구가 많은 사람에 의해 오랫동안 사용되어 왔는가?
먼저, 1번과 관련하여 LTS라는 버전이 있습니다. LTS는 Long Term Support의 약자로, 개발 도구에 대한 장기적인 관리와 지원이 제공된다는 의미입니다. 따라서, 일반적으로 엔터프라이즈용 애플리케이션을 개발할 때는 개발 도구에 LTS라는 표기가 명시된 버전을 주로 사용합니다.
또한, 2번과 관련하여, 해당 개발 도구가 얼마나 많은 사람이 얼마나 오랫동안 사용해 왔는지도 버전 안정성에 대한 중요한 지표로 사용할 수 있습니다. 현재 LTS 버전으로 출시된 JDK 버전은 8, 11, 17 등이 있습니다. 이 중에서 8 버전이 가장 오래되었고, 11버전이 그다음을 따릅니다. 비교적 최근에 출시된 17 버전은 아직 8 버전과 11 버전에 비해 사용자 수가 많지 않습니다.
그렇다면 LTS 버전 중에서 사용자가 가장 많고 오래된 8 버전을 사용하는 것이 좋을까요? 이에 대한 답은 **"정답은 없다"**입니다. 어떤 버전을 사용하는지를 판단하는 데 안정성 외에도 수많은 사항을 고려해야 합니다. 어떤 회사의 서비스에는 8 버전이 적합할 수도, 어떤 회사의 서비스에는 17 버전이 적합할 수도 있습니다.
단, 프로그래밍을 이제 막 배우는 여러분에게 있어서는 11 버전이 적합합니다. 8 버전이 사용자가 가장 많고, 상대적으로 오랜 시간 동안 사용되어 왔기 때문에 셋 중에서 제일 안정적인 버전이라고 할 수 있지만, 11 버전에서 추가된 유용한 기능들을 8 버전에서는 사용할 수 없습니다. 또한, 11 버전도 8 버전 다음으로 사용자가 많은 버전이라 충분히 안정적인 버전으로 볼 수 있기 때문에 8 버전 대신 11 버전을 많이 사용합니다.
Main 메서드
이어지는 콘텐츠에서부터는 인텔리제이를 열고 직접 예제를 따라서 작성해 가며 학습을 진행해야 합니다. 인텔리제이를 사용하여 프로젝트를 생성하면, 기본적으로 아래와 같은 코드가 작성되어 있습니다. 클래스의 이름은 다를 수 있습니다.
public class Main {
public static void main(String[] args) {
}
}
변수
a = 1, b = 2 일 때, a + b는?
쉬운 문제이지만, 이 문제를 푸는 과정에서 여러분들의 머릿속에서는 아래와 같은 사고 과정이 진행됩니다.
- 인지 : “a는 1이고, b는 2다. ”
- 치환 : “따라서 a + b는 1 + 2다. “
- 계산 : “답은 3이다. “
위 문제의 답을 구하려면 먼저, a와 b의 값이 각각 1과 2임을 머릿속에 기억해두어야 하며, 그다음, 기억해 둔 값을 토대로 a + b를 1 + 2로 치환할 수 있습니다. 숫자로 식을 치환한 이후부터 계산을 진행할 수 있게 됩니다.
컴퓨터도 마찬가지입니다. 컴퓨터도 데이터를 다룰 때, 그 데이터를 메모리라는 곳에 임시로 기억해 둡니다.
그러나, 컴퓨터의 기억 과정은 사람의 기억 과정과 다릅니다. 여러분은 a가 1이고, b가 2라는 것을 기억하고자 할 때, 그냥 ‘a는 1이고 b는 2이다’로 자연스럽게 기억할 수 있을 것입니다. 반면, 컴퓨터는 메모리에 어떤 값을 저장할 때 아래의 과정을 통해 값을 저장합니다.
- 기억하고자 하는 값이 얼만큼의 메모리 공간을 필요로 하는지 파악합니다.
- 기억하고자 하는 값이 차지하는 용량만큼의 메모리 공간을 확보합니다.
- 값을 저장한 공간에 이름을 붙입니다.
- 확보한 메모리 공간에 기억하고자 하는 값을 저장합니다.
위 과정에서 1 ~ 3번이 중요합니다.
- 1번 : 어떤 값을 기억하기 위해서는 그 값을 저장하기 위해 필요한 메모리 공간의 크기를 알아야 합니다. 이를 위해 필요한 것이 바로 이제부터 학습할 타입입니다. 타입, 또는 데이터 타입은 데이터의 유형을 의미하며, 데이터의 유형별로 차지하는 메모리 공간의 크기가 각각 다릅니다.
- 2번 & 3번 : 어떤 값을 메모리에 저장한 다음, 해당 값에 접근할 수 있으려면 값을 저장한 곳에 이름이 있어야 합니다. 그래야 그 이름을 통해서 값에 접근할 수 있으니까요. 이처럼, 어떤 값을 저장하고 나서 해당 값에 접근할 수 있도록 값이 저장된 메모리 공간에 사람이 지은 이름을 붙인 것을 변수라고 합니다.
1 ~ 3번의 과정을 프로그래밍에서는 변수를 선언한다고 하며, 4번과 같이 선언한 변수에 값을 저장하는 것을 변수에 값을 할당한다고 합니다.
이번 챕터에서는 데이터의 종류와 크기를 결정하는 타입과, 데이터 저장과 사용을 위한 변수에 대해 학습합니다.
상수
상수(Constant) : 변하지 말아야 할 데이터를 임시로 저장하기 위한 수단
상수는 간단히 말해, 재할당이 금지된 변수입니다. 즉, 변수와 같이 선언하고 할당하여 사용할 수 있지만, 재할당이 금지돼 있습니다. 상수는 final이라는 키워드를 사용해 선언할 수 있으며, 관례로 대문자에 언더바(_)를 넣어 구분하는 SCREAMING_SNAKE_CASE를 사용합니다.
final double CALCULATOR_PI = 3.14;
상수를 사용하는 이유
재할당을 할 수 없는데 상수를 왜 사용하는 것일까요? 상수는 다음과 같은 경우에 사용합니다.
- 프로그램이 실행되면서 값이 변하면 안 되는 경우
- 프로그래머가 실수로 상수에 값을 재할당하고자 하면 에러가 발생하여 실수를 방지할 수 있습니다.
- 코드 가독성을 높이고 싶은 경우
- 상수를 사용하면 값을 저장하고 있는 상수 명으로 값을 사용할 수 있기 때문에 코드 가독성이 향상됩니다.
- 코드 유지관리를 손쉽게 하고자 하는 경우
- 여러분들이 계산기 프로그램을 만들었으며, 소스 코드에서 원주율이 필요한 곳에 모두 숫자 값 3.14를 그대로 사용했다고 가정합시다. 만약, 여러분이 계산의 정밀도를 높이기 위해 원주율을 3.14159로 변경해야 한다면, 기존의 3.14가 사용된 모든 코드를 찾아 일일이 수정해주어야 합니다. 반면, 상수를 사용하면 상수에 할당할 값만 3.14159로 바꾸어주면 됩니다.
// 기존 코드
final double CALCULATOR_PI = 3.14;
// 변경된 코드
final double CALCULATOR_PI = 3.14159;
상수는 선언과 할당을 반드시 동시에 해야합니다.
타입
타입이란?
타입은 어떤 값의 유형 및 종류를 의미하며, 타입에 따라 값이 차지하는 메모리 공간의 크기와, 값이 저장되는 방식이 결정됩니다.
- 값이 차지하는 메모리 공간의 크기
- 예를 들어, 정수형 타입의 데이터는 4byte, 문자형 타입의 데이터는 1byte입니다.
- 값이 저장되는 방식
- 타입은 저장하고자 하는 값을 그대로 저장하는 기본 타입과, 저장하고자 하는 값을 임의의 메모리 공간에 저장한 후, 그 메모리 공간의 주소를 저장하는 참조 타입으로 분류됩니다.
1번에 대해서는 이어지는 콘텐츠를 통해 각 타입을 학습하며 다루게 됩니다. 2번에 대해서는 아래에서 살펴보겠습니다.
기본 타입과 참조 타입
자바의 타입은 실제 값을 의미하는 기본 타입(primitive type)과 어떤 값이 저장된 주소를 값으로 갖는 참조 타입(reference type), 두 가지의 데이터 타입을 가지고 있습니다.
- 기본 타입(primitive type)
- 값을 저장할 때, 데이터의 실제 값이 저장됩니다.
- 정수 타입(byte, short, int, long), 실수 타입(float, double), 문자 타입(char), 논리 타입(boolean)
- 참조 타입(reference type)
- 값을 저장할 때, 데이터가 저장된 곳을 나타내는 주소값이 저장됩니다.
- 객체의 주소를 저장, 8개의 기본형을 제외한 나머지 타입
여러분이 책에서 ‘변수’라는 단어를 찾고 있다고 가정해 봅시다.
이때, 책 어딘가에서 “변수는 ~이다”라고 직접적으로 의미를 알려준다면 기본 타입의 데이터라고 할 수 있습니다. 반면, 색인처럼 “변수는 132페이지에 설명되어 있다”라고 한다면 이는 참조 타입의 데이터라고 할 수 있습니다.
여러분들의 이해를 돕기 위해 의사코드로 기본타입과 참조 타입을 설명해 보겠습니다. 아래 코드는 실제 코드가 아닌, 코드의 의미를 나타낼 수 있는 의사코드로 작성한 예제입니다.
이제 실제 코드를 통해 기본 타입과 참조 타입의 차이를 이해해 봅시다. 위에서 설명한 것과 마찬가지로, 아래 예제의 문법을 지금 시점에서 이해할 필요는 없습니다.
public class Main {
public static void main(String[] args) {
int primitive = 1;
Object reference = new Object();
System.out.println(primitive);
System.out.println(reference);
}
}리터럴이란?
사전적으로 리터럴(Literal)은 ‘문자 그대로의'라는 뜻을 가집니다. 프로그래밍에서 리터럴이란 문자가 가리키는 값 그 자체를 의미합니다.
여러분의 이해를 돕기 위해 변수를 학습하며 사용했던 예제를 그대로 가져와 설명하겠습니다.
class Main {
public static void main(String[] args) {
int num; // 변수 선언
num = 1; // 값 할당
}
}위 예제에서 num에 할당하고 있는 1이 바로 리터럴입니다.
자, 이제 리터럴이라는 용어를 학습했으니 이제부터는 ‘값’이라는 표현 대신에 리터럴이라는 표현을 사용하겠습니다.
개발자는 개발뿐만 아니라 소통에도 능해야 합니다. 정확한 용어를 사용하는 것은 원활한 소통에 있어 중요하기 때문에 여러분들도 어떤 개념을 생각하고, 기록하고, 말할 때 정확한 용어를 사용하는 것을 지금부터 연습해 주시기 바랍니다.
정수 타입
정수 타입은 숫자를 나타내는 타입으로, byte, short, int, long의 총 4개의 타입으로 분류됩니다. 이들은 각각 차지하는 메모리의 크기가 다르며, 그에 따라 나타낼 수 있는 숫자의 범위가 다릅니다.
예전에는 메모리의 용량이 그리 넉넉하지 않아서 필요에 따라 변수의 자료 범위를 변경해야 했습니다. 그래서 적은 메모리를 사용하는 short(2byte), 가장 많은 메모리를 사용하는 long(8byte), 중간 정도의 메모리를 사용하는 int(4byte)로 나누어 사용했습니다.
하지만 근래에는 메모리 용량이 부족한 경우가 거의 없기 때문에 정수형을 사용할 때는 일반적으로 int형을 사용합니다.
타입별로 차지하는 메
모리 공간의 크기와 표현할 수 있는 범위는 다음과 같습니다.

정수형 리터럴은 아래와 같이 정수형 변수에 할당할 수 있습니다. 이때, long 타입 리터럴의 경우에는 리터럴 뒤에 접미사 L 또는 l을 붙여주어야 합니다. 일반적으로, 숫자 1과 혼동을 방지하기 위해 대문자 L을 붙입니다.
// 각 데이터 타입의 표현 범위에 맞는 값을 할당하고 있습니다.
byte byteNum = 123;
short shortNum = 12345;
int intNum = 123456789;
long longNum = 12345678910L;
// 각 데이터 타입의 표현 범위에 벗어난 값을 할당하고 있어 에러가 발생합니다.
byte byteNum = 130;
short shortNum = 123456;
int intNum = 12345678910;
// 숫자가 길면 언더바로 구분할 수 있습니다.
int intNum = 12_345_678_910;
long longNum = 12_345_678_910L;
정수형의 오버플로우와 언더플로우
여러분이 작성한 코드가 실행 중일 때, 어떤 값이 실수로 작성한 코드에 의해 각 타입의 표현 범위를 넘어서는 경우가 발생할 수 있습니다.
예를 들어, byte형 값 120에 10을 더하면 130이 될 수 있겠죠? byte형의 표현 범위는 -128 ~ 127이므로, 130은 byte형의 표현 범위를 넘어서는 값이 됩니다. 이때 오버플로우가 발생합니다.
반대로, byte형 값 -120이 있다고 할 때, -120에서 10을 빼면 그 값은 -130이 됩니다. -130은 byte형의 표현 범위 중 최소값을 넘어서는 값이므로, 언더플로우가 발생합니다.

- 오버플로우
- 자료형이 표현할 수 있는 범위 중 최대값 이상의 값을 표현한 경우 발생합니다.
- 최대값을 넘어가면 해당 데이터 타입의 최소값으로 값이 순환합니다.
- 예 : 어떤 값이 byte형이고, byte형의 최대값인 127을 값으로 가지는 경우, 이 값에 1을 더하면 128이 되는 게 아니라, 최소값인 -128이 됩니다.
- 언더플로우
- 자료형이 표현할 수 있는 범위 중 최소값 이하의 값을 표현한 경우 발생합니다.
- 최소값을 넘어가면 해당 데이터 타입의 최대값으로 값이 순환합니다.
- 예 : 어떤 값이 byte형이고, byte 형의 최소값인 -128을 값으로 가지는 경우, 이 값에 1을 빼면 -129가 되는 게 아니라, 최대값인 127이 됩니다.
데이터 타입의 크기와 표현 범위
데이터 타입의 크기와 정수형의 표현 범위 간에 무슨 관련이 있을까요? byte → short → int → long으로 갈수록 데이터 타입의 크기도 커지고 표현 범위도 커집니다. 즉, 데이터 타입의 크기가 데이터의 표현 범위를 결정합니다.
컴퓨터는 0과 1로 데이터를 표현합니다. 즉 0과 1로 이루어진 이진수로 데이터를 표현합니다. 이진수 한자리로는 0과 1만 표현할 수 있지만, 이진수를 두 자리, 세 자리로 늘리면 더 많은 데이터를 표현할 수 있습니다.
- 이진수 한 자리 : 0, 1 → 21개 → 2개
- 이진수 두 자리 : 00, 01, 10, 11 → 22개 → 4개
- 이진수 세 자리 : 000, 001, 010, 011, 100, 101, 110, 111 → 23개 → 8개
이제 byte형을 예로 들어볼까요?
byte형은 말 그대로 1byte의 크기를 가진 정수형 데이터 타입입니다. 1byte는 8bit이므로 따라서 8자리의 이진수를 표현할 수 있습니다. 즉, 위에서 언급한 대로라면 28 = 256개의 데이터를 표현할 수 있습니다. 부호를 감안하지 않는다면 0부터 255까지의 256개의 숫자를 1byte로 표현할 수 있습니다.
하지만 음수의 범위도 표현할 수 있어야 합니다. 이를 위해 8비트 중의 맨 앞의 비트를 부호 비트로 사용합니다. 즉, 맨 앞의 비트가 0이면 양수, 1이면 음수를 나타내게 됩니다. 이렇게 하나의 비트로 부호를 표현하고 나면 이제 남은 비트는 7비트입니다. 따라서 남은 7비트로는 27 = 128개의 숫자를 표현할 수 있습니다.
결과적으로, byte형은 8bit의 크기 중 1bit는 부호 표현에 사용하며, 7bit는 숫자 표현에 사용하여 -128 ~ 127의 정수 범위를 표현할 수 있게 됩니다. 이와 같은 이유로 데이터 타입의 크기는 데이터의 표현 범위에 영향을 미치게 됩니다.
이 설명을 토대로, 왜 정수형의 범위가 -2,147,483,648(-231) ~ 2,147,483,647(231-1)인지 스스로 생각해 보세요.
실수 타입
실수는 소수점을 가지는 값을 의미하며, float형과 double형으로 분류됩니다.

실수형 리터럴은 아래와 같이 사용할 수 있습니다. 이때, double형 리터럴에는 접미사 d를 붙여도, 붙이지 않아도 되지만, float형 리터럴에는 반드시 접미사 f를 붙여주어야 합니다.
// float형 리터럴을 float형 변수에 할당
float num1 = 3.14f;
// double형 리터럴을 double형 변수에 할당
double num2 = 3.141592d;
double num2 = 3.141592;컴퓨터에서 실수를 저장할 때는 부동소수점 표현 방식으로 저장하는데, 이러한 방식은 효율적이지만 약간의 오차를 갖습니다.
이 오차는 실수를 더 정밀하게 표현할수록 줄어듭니다. 여기서 얼마나 실수를 정밀하게 나타낼 수 있는지를 정밀도라고 하는데, 정밀도는 데이터 타입의 크기가 클수록 높아집니다.
따라서 double형은 float형보다 정밀도가 더 높습니다.
정리하면, double형은 float형보다
- 더 큰 실수를 저장할 수 있습니다.
- 더 정확하게 저장할 수 있습니다.
실수형의 오버플로우와 언더플로우
실수형에서도 오버플로우와 언더플로우가 발생합니다. 다만, 오버플로우와 언더플로우가 발생했을 때의 결과가 다릅니다.
- 오버플로우
- 값이 음의 최소 범위 또는 양의 최대 범위를 넘어갔을 때 발생하며, 이때 값은 무한대가 됩니다.
- 언더플로우
- 값이 음의 최대 범위 또는 양의 최소 범위를 넘어갔을 때 발생하며, 이때 값은 0이 됩니다.

논리 타입
논리 타입의 종류는 boolean형 한 가지뿐입니다. boolean형은 참 또는 거짓을 저장할 수 있는 데이터 타입으로, 오직 true 혹은 false를 값으로 가집니다.
단순히 참과 거짓을 표현하기 위해서는 1bit만 있으면 되지만, JVM이 다룰 수 있는 데이터의 최소 단위가 1byte이기 때문에 boolean형은 1byte(8bit)의 크기를 가집니다.
boolean형은 많은 경우에 추후 배울 조건문과 함께 사용됩니다. 추후 조건문을 학습하면서 boolean형 사용 방법을 자연스럽게 연습할 수 있습니다.
boolean isRainy = true;
boolean isAdult = false;문자 타입
문자 타입은 2byte 크기의 char형 오직 하나만 있습니다.
문자 타입 변수를 선언하면 해당 변수에 오직 하나의 문자형 리터럴을 저장할 수 있습니다.
문자형 리터럴을 작성할 때는 반드시 큰따옴표(””)가 아닌 작은따옴표(’’)를 사용하여야 합니다. 큰따옴표를 사용한 리터럴은 문자형 리터럴이 아니라 문자열 리터럴로 인식되기 때문입니다.
참고로, 자바에서 문자형과 문자열은 다릅니다. 문자열에 대해서는 이후의 콘텐츠에서 학습합니다.
char letter1 = 'a';
char letter2 = 'ab'; // 에러 : 단 하나의 문자만 할당할 수 있습니다.
char letter3 = "a" // 에러 : 작은따옴표를 사용해야 합니다.그렇다면 문자 타입의 리터럴은 문자 타입 변수에 어떻게 저장되는 것일까요?
자바는 유니코드로 문자를 저장합니다. 유니코드는 전 세계의 모든 문자를 컴퓨터에서 일관되게 다루기 위한 국제 표준으로, 각 문자에 숫자 코드 번호를 부여한 것입니다. 따라서, char letter1 = ‘a’;와 같이 문자형 리터럴을 문자형 변수에 할당하면 letter1에는 영문자 a의 유니코드 숫자값이 저장됩니다.
숫자를 문자형 변수에 할당할 수도 있습니다. 아래 예제처럼 숫자를 문자형 변수에 할당하면, 해당 숫자가 그대로 저장되지만, 나중에 변수를 참조할 때, 즉 변수의 값을 읽어올 때 해당 변수가 저장하고 있는 숫자값을 유니코드로 인식하여 해당 숫자와 일치하는 코드를 가진 문자로 변환해 줍니다.
참고로, System.out.print();는 () 안의 내용을 출력해 주는 메서드입니다. 추후에 학습할 예정이니 지금은 가볍게 참고만 해주세요.
char letter = 65;
System.out.print(letter); // 출력 결과 : A타입 변환
앞서 변수를 선언할 때 타입을 명시해야 한다고 배웠습니다. boolean을 제외한 기본 타입 7개는 서로 타입을 변환할 수 있으며, 자동으로 타입이 변환되는 경우도 있고, 수동으로 변환해주어야만 하는 경우도 있습니다. 먼저, 자동 타입 변환에 대해서 학습해 봅시다.
자동 타입 변환
아래 두 경우에는 타입이 자동으로 변환됩니다.
- 바이트 크기가 작은 타입에서 큰 타입으로 변환할 때 (예 : byte → int)
- 덜 정밀한 타입에서 더 정밀한 타입으로 변환할 때 (예 : 정수 → 실수)
아래 순서도의 화살표는 화살표를 기준으로 좌측의 타입이 우측의 타입으로 자동으로 변환될 수 있음을 의미합니다. 각각의 타입 옆의 소괄호에 타입이 가지는 크기를 적어두었으니, 위의 두 가지 원칙을 기반으로 아래의 순서도를 스스로 이해해 보세요.
원칙을 이해하는 것이 중요합니다. 아래의 내용을 천천히 이해해 보시고, 이해한 내용을 연습문제 또는 추후 실습을 통해 적용하면서 익숙해지시기 바랍니다.
byte(1) -> short(2)/char(2) -> int(4) -> long(8) -> float(4) -> double(8)하나만 짚자면, 위의 순서도에서 float은 4byte인데 int와 long보다 더 뒤쪽에 있습니다. 이는 float이 표현할 수 있는 값이 모든 정수형보다 더 정밀하기 때문입니다.
// float이 long보다 정밀하므로, 자동으로 타입이 변환됩니다.
long longValue = 12345L;
float floatValue = longValue;
System.out.println(floatValue); // 12345.0이 출력됩니다.
수동 타입 변환
차지하는 메모리 용량이 더 큰 타입에서 작은 타입으로는 자동으로 타입이 변환되지 않습니다. 이때 더 큰 데이터 타입을 작은 데이터 타입의 변수에 저장하기 위해서는 수동으로 타입을 변환해 주어야만 합니다. 이를 캐스팅(casting)이라고 합니다.
수동으로 타입을 변환할 때는 캐스팅 연산자 ()를 사용하며, 캐스팅 연산자의 괄호 안에 변환하고자 하는 타입을 적어주면 됩니다.
//int 타입으로 선언된 변수 intValue를 더 작은 단위인 byte로 변환합니다.
int intValue = 128;
byte byteValue = (byte)intValue;
System.out.println(byteValue); // -128위 예제에서 intValue가 저장하고 있는 int형의 값 128을 byte형으로 캐스팅하여 byte형 변수 byteValue에 할당해 주었습니다. byte형의 표현 범위는 -128 ~ 127이므로, 128을 byte형으로 변환하면 표현 범위를 벗어나게 되어 오버플로우가 발생합니다. 따라서 최종적으로 저장되는 값은 -128이 됩니다.
타입 변환은 예전에는 중요한 개념이었지만, 메모리 용량이 넉넉해진 지금은 일반적으로 정수는 int 또는 long, 실수는 double로 사용하기 때문에 예전에 비해 수동 타입 변환의 사용 빈도가 많이 줄었습니다. 따라서 지금은 ‘타입 변환이란 이런 것이구나’ 정도로만 이해해 주시면 됩니다.
String이란?
앞서 우리는 다양한 데이터 타입에 대해서 배웠습니다. 이번 시간에는 자바에서는 문자열을 다루는 방법에 대해 배워보겠습니다.
자바는 String 클래스 타입을 사용해서 문자열을 다룹니다. 다른 타입들과 다르게 왜 문자열만 클래스를 통해 다루는지 의문을 가지실 수 있습니다. 아직 클래스에 대해 배우지 않았기 때문에 명쾌하게 설명하기 어렵지만, 간단하게 설명하자면 클래스는 그 자체로 타입으로 사용될 수 있으며, 연관된 기능들을 묶을 수 있습니다.
다시 말해, String 클래스는 문자열 타입으로 사용되며, 문자열과 관련된 유용한 메서드들을 가지고 있습니다. 여기에서 여러분은 방금 언급한 클래스의 특성에 대해 암기할 필요가 없습니다. “문자열은 String 클래스를 통해 다루어지고, 그 안에 있는 메서드들을 통해 여러 문자열 관련 메서드들을 사용할 수 있구나” 정도로만 이해하시면 됩니다. 클래스에 대해서는 추후 자세하게 배울 예정입니다.
이제 String 클래스를 사용해서 문자열을 다루는 기본적인 방법을 살펴봅시다.
String 타입의 변수 선언과 할당
String 타입의 변수 선언과 할당
기본적으로 String 타입은 큰따옴표("")로 감싸진 문자열을 의미합니다.
String 타입의 변수를 선언하고, 문자열 리터럴을 할당하는 방법은 다음과 같습니다.
// 문자열 리터럴을 String 타입의 변수 name에 할당하는 방법
String name1 = "Kim Coding";
// String 클래스의 인스턴스를 생성하는 방법
String name2 = new String("Kim Coding");아직 여러분은 클래스와 인스턴스에 대해서 학습하지 않았습니다. 클래스와 인스턴스에 대해서는 추후 [객체지향 프로그래밍 기초]에서 자세히 다룹니다.
여기에서는 “클래스는 일종의 거푸집이며, 그 거푸집을 통해서 찍어낸 것이 인스턴스다. 그리고, 클래스로 인스턴스를 찍어내고자 할 때 new 연산자를 사용한다.” 정도로만 이해해 주시기 바랍니다.
그리고, 어떤 클래스를 통해 인스턴스를 생성하면 해당 인스턴스의 타입은 자신을 생성해 낸 클래스를 타입으로 가집니다. 그러므로, String 클래스를 통해 만들어진 인스턴스는 String 타입의 변수에 할당할 수 있습니다.
지금 시점에서 여러분이 이해해 주셔야 할 내용은 다음과 같습니다.
- String 타입의 변수는 String 변수명;으로 선언할 수 있다.
- 선언한 변수에 문자열을 할당하는 방법은 두 가지가 있다.
- 문자열 리터럴을 할당하는 방법 : 변수 = “문자열”;
- String 클래스의 인스턴스를 생성하여 할당하는 방법 : 변수 = new String(”문자열”);
심화 학습
아래부터는 심화 내용입니다. 지금 당장 아래의 모든 내용을 이해하지 않아도 됩니다. 문자열에 대한 기본적인 사용법을 익힌 후에 추가로 학습해 주세요.
a번과 b번 방법은 공통점과 차이점을 가집니다.
먼저, 두 방법의 공통점에 대해서 살펴봅시다. 문자열 리터럴을 직접 할당하는 방식이든, String 클래스의 인스턴스를 생성하여 할당하는 방법이든 공통으로 참조 타입의 변수에 할당됩니다. 즉, 위의 예제에서 name1과 name2는 실제 문자열의 내용을 값으로 가지고 있는 것이 아니라, 문자열이 존재하는 메모리 공간상의 주소값을 저장하고 있습니다.
그러나, 문자열을 출력해 보면 주소값이 아니라 문자열의 내용이 출력됩니다.
String name1 = "Kim Coding";
String name2 = new String("Kim Coding");
System.out.print(name1); // "Kim Coding"
System.out.print(name2); // "Kim Coding"이는 String 타입의 변수를 참조하면 String 클래스의 메서드인 toString()이 자동으로 호출되기 때문입니다. toString()이 자동으로 호출되면 String 타입의 변수가 저장하고 있는 주소값에 위치한 String 인스턴스의 내용을 문자열로 변환해 줍니다.
이제 두 방법 간의 차이점에 대해서 살펴보겠습니다. 아래의 예제를 먼저 살펴봅시다.
String name1 = "Kim Coding";
String name2 = "Kim Coding";
String name3 = new String("Kim Coding");
String name4 = new String("Kim Coding");
boolean comparison1 = name1 == "Kim Coding"; // true
boolean comparison2 = name1 == name2; // true
boolean comparison3 = name1 == name3; // false
boolean comparison4 = name3 == name4; // false
boolean comparison5 = name1.equals("Kim Coding"); // true
boolean comparison6 = name1.equals(name3); // true
boolean comparison7 = name3.equals(name4); // trueString 클래스의 메서드
String 클래스는 문자열을 조작할 수 있는 유용한 메서드들을 가지고 있습니다. 클래스가 메서드를 가지고 있다는 표현이 지금은 이해가 어려우실 수 있습니다. 추후 [객체지향 프로그래밍 기초]를 학습하면서 클래스와 메서드를 배우고 나면 클래스가 메서드를 가진다는 표현을 충분히 이해하실 수 있습니다. 여기에서는 메서드 사용 방법을 중점적으로 학습해 주시기 바랍니다.
length() 메서드
length() 메서드는 문자열의 길이, 즉 철자의 개수를 리턴하는 메서드입니다. 추후 반복문에서 사용할 일이 많으니 용법과 출력 결과를 잘 살펴봐 주세요.
다음 예제는 문자열의 길이를 출력하는 예제입니다.
String str = "java";
System.out.println(str.length()); // 4
charAt() 메서드
charAt() 메서드는 해당 문자열의 특정 인덱스에 해당하는 문자를 반환합니다. 만약 해당 문자열의 길이보다 큰 인덱스나 음수를 전달하면 오류가 발생합니다. 그리고, 문자열의 길이에서 1을 빼면 문자열의 마지막 인덱스와 일치하는 값이 됩니다. 이는 문자열의 길이를 셀 때에는 1부터 세는 반면, 인덱스를 셀 때에는 0부터 세기 때문입니다. 아래 예제를 통해 확인해 보세요.
다음 예제는 문자열의 각 문자를 charAt() 메서드를 이용하여 하나씩 출력하는 예제입니다.
String str = new String("Java");
System.out.println("문자열 : " + str); // "문자열 : Java"
System.out.println(str.charAt(0)); // 'J'
System.out.println(str.charAt(1)); // 'a'
System.out.println(str.charAt(2)); // 'v'
System.out.println(str.charAt(3)); // 'a'
System.out.println(str.length()); // 4
System.out.println("\ncharAt() 메서드 호출 후 문자열 : " + str);
compareTo() 메서드
compareTo() 메서드는 해당 문자열을 인수로 전달된 문자열과 사전 편찬 순으로 비교합니다. 이 메서드는 문자열을 비교할 때 대소문자를 구분하여 비교합니다. 만약 두 문자열이 같다면 0을 반환하며, 해당 문자열이 인수로 전달된 문자열보다 작으면 음수를, 크면 양수를 반환합니다. 만약 문자열을 비교할 때 대소문자를 구분하지 않기를 원한다면, compareToIgnoreCase() 메서드를 사용하면 됩니다.
다음 예제는 compareTo() 메서드와 compareToIgnoreCase() 메서드를 이용하여 두 문자열을 비교하는 예제입니다.
String str = new String("abcd");
System.out.println("문자열 : " + str);
System.out.println(str.compareTo("bcef"));
System.out.println(str.compareTo("abcd") + "\n");
System.out.println(str.compareTo("Abcd"));
System.out.println(str.compareToIgnoreCase("Abcd"));
System.out.println("compareTo() 메서드 호출 후 문자열 : " + str);
concat() 메서드
concat() 메서드는 해당 문자열의 뒤에 인수로 전달된 문자열을 추가한 새로운 문자열을 반환합니다. 참고로, concat은 concatenate의 약자로, 사전적으로 연결한다는 의미를 가집니다. 만약 인수로 전달된 문자열의 길이가 0이면, 해당 문자열을 그대로 반환합니다.
다음 예제는 concat() 메서드를 이용하여 두 문자열을 연결하는 예제입니다.
String str = new String("Java");
System.out.println("문자열 : " + str);
System.out.println(str.concat("수업"));
System.out.println("concat() 메서드 호출 후 문자열 : " + str);
indexOf() 메서드
indexOf() 메서드는 해당 문자열에서 특정 문자나 문자열이 처음으로 등장하는 위치의 인덱스를 반환합니다. 만약 해당 문자열에 전달된 문자나 문자열이 포함되어 있지 않으면 -1을 반환합니다.
다음 예제는 indexOf() 메서드를 이용하여 특정 문자나 문자열이 처음 등장하는 위치의 인덱스를 찾는 예제입니다.
String str = new String("Oracle Java");
System.out.println("문자열 : " + str);
System.out.println(str.indexOf('o'));
System.out.println(str.indexOf('a'));
System.out.println(str.indexOf("Java"));
System.out.println("indexOf() 메서드 호출 후 원본 문자열 : " + str);
trim() 메서드
trim() 메서드는 해당 문자열의 맨 앞과 맨 뒤에 포함된 모든 공백 문자를 제거해 줍니다.
다음 예제는 trim() 메서드를 이용하여 문자열에 포함된 띄어쓰기와 탭 문자를 제거하는 예제입니다.
String str = new String(" Java ");
System.out.println("문자열 : " + str);
System.out.println(str + '|');
System.out.println(str.trim() + '|');
System.out.println("trim() 메서드 호출 후 문자열 : " + str);toLowerCase()와 toUpperCase() 메서드
toLowerCase() 메서드는 해당 문자열의 모든 문자를 소문자로 변환시켜 줍니다. 또한, toUpperCase() 메서드는 해당 문자열의 모든 문자를 대문자로 변환시켜 줍니다.
다음 예제는 toLowerCase() 메서드와 toUpperCase() 메서드를 이용하여 문자열의 대소문자를 변경하는 예제입니다.
String str = new String("Java");
System.out.println("문자열 : " + str);
System.out.println(str.toLowerCase());
System.out.println(str.toUpperCase());
System.out.println("두 메서드 호출 후 문자열 : " + str);