
과제 - 인스타그램 데이터 모델링
1. 엔티티 도출
Member
Post
Comment
Like
Hashtag
Photo
2. 관계 설정
Member - Post -> 1 : N
Post - Comment -> 1 : N
Comment - Member -> N : 1
Post - Like -> 1 : N
Like - Member -> N : 1
Post - Hashtag -> N : M
Post - Photo -> 1 : N
3. 논리적 모델링

데이터베이스 설치
시작하기 - Mac
Getting Started
SQL문을 사용하기 위해 로컬 컴퓨터에 데이터베이스를 설치하고, 사용해 봅니다. 이번 스프린트에서 대표적인 RDBMS 중에서 MySQL을 사용합니다.
Bare minimum requirement
- 로컬 컴퓨터(자신의 컴퓨터)에 MySQL을 설치합니다.
- 터미널을 통해 MySQL에 접속하고, SQL문을 작성하여 원하는 결과를 확인할 수 있습니다.
1. MySQL 설치
로컬 컴퓨터의 운영체제에 맞게 설치를 진행하세요.
설치과정에 어려움이 있거나, 검색을 통해서도 해결되지 않을 때는 Agora States에 적극적으로 질문을 남기세요.
MySQL 설치가 되어있지 않다면, 앞으로의 Sprint와 Project 진행이 불가합니다.
macOS와 Ubuntu(Linux) 두 가지의 OS에 따른 안내사항이 있습니다.
자신의 운영체제와 콘텐츠의 운영체제가 같은지 반드시 확인하세요.
macOS
패키지 매니저 Homebrew를 이용해 MySQL을 설치합니다.
Homebrew를 이용한 설치
brew install mysql
brew info mysql
- Reference: macOS MySQL 설치
Ubuntu(Linux)
패키지 매니저 apt-get을 이용해 MySQL을 설치합니다.
우분투(리눅스) OS에 포함된 패키지 매니저이므로 별도의 설치가 필요하지 않습니다.
apt-get을 이용한 설치
sudo apt-get update
sudo apt-get install mysql-server
- Reference: Ubuntu MySQL 설치
2. MySQL 서비스 시작
MySQL을 설치했다면, MySQL 프로그램을 실행해야 합니다.
그렇지 않으면 MySQL을 사용할 수 없습니다.
macOS
brew services start mysql
- Reference: macOS MySQL 설치
Ubuntu(Linux)
sudo systemctl start mysql
- Reference: Ubuntu MySQL 설치
3. MySQL 접속
다음의 명령어로 MySQL에 접속할 수 있습니다.
오류가 발생하거나, 존재하지 않는 명령어라는 결과가 나온다면, 설치에 문제가 있거나 MySQL이 실행되지 않은 상태입니다.
자신의 운영체제에 맞게 MySQL을 설치했는지 확인하세요.
mysql -u root
MySQL을 처음 설치하면, root의 암호는 비어 있습니다. <kbd>Enter</kbd> 키를 눌러주세요.
비밀번호를 설정하고 나면, 다음의 명령어로 MySQL에 접속해야 합니다.
# -u(계정 접근), -p(비밀번호)
mysql -u root -p
이 단계에서 로그인이 되지 않는 경우, 검색을 통해 문제를 해결해 보세요.
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'yourPassword';
- Reference: MySQL root 계정 비밀번호 세팅
SQL GUI Support Tool
GUI 환경에서도 MySQL과 같은 데이터베이스에 접속할 수 있습니다.
GUI 툴을 이용해 SQL문을 입력하여 실행하거나, 테이블 정보를 볼 수 있습니다.
다음은 대표적인 GUI Support Tool입니다. 다음 중 원하는 툴을 선택하고, 사용해 보세요.
- MySQL Workbench
- Sequel Pro (OSX 전용)
- Table Plus
- DBeaver
- DataGrip
데이터베이스에 접속하기 위한 방법으로 CLI 환경과 GUI 환경을 중 더 나은 선택지는 없습니다.
사용자의 편의에 알맞은 방법을 사용하세요.
단, 두 방식을 모두 사용할 줄 알아야 합니다.
4. Playground MySQL IN YOUR COMPUTER
실습하기에서 학습한 SQL 구문으로 로컬 컴퓨터의 데이터베이스에서 실습해 보세요.
DBeaver 설치
DBeaver는 개발자, 데이터 분석가 및 데이터베이스 관리자를 위한 다기능 데이터베이스 관리 도구입니다. 이 소프트웨어는 여러 데이터베이스 시스템을 지원하고, 오픈 소스이기 때문에 무료로 사용할 수 있습니다. 이 도구는 데이터베이스와의 상호작용을 용이하게 하며, 복잡한 데이터 작업을 단순화시킵니다.
DBeaver의 주요 기능
- 다양한 데이터베이스 지원: DBeaver는 MySQL, PostgreSQL, MariaDB, SQLite, Oracle, DB2, SQL Server 등을 비롯한 주요 데이터베이스 시스템을 지원합니다.
- SQL 편집 및 실행: 사용자는 SQL 쿼리를 작성, 실행 및 최적화할 수 있습니다. SQL 편집기는 구문 강조, 자동 완성 및 SQL 포맷팅 기능을 제공합니다.
- 데이터 시각화: 데이터를 쉽게 이해할 수 있도록 그래픽 차트, 테이블 뷰어 등의 시각화 도구를 제공합니다.
- 데이터베이스 관리: 사용자는 스키마, 테이블, 뷰, 인덱스 등 데이터베이스 객체를 관리할 수 있습니다. 이러한 객체를 생성, 수정, 삭제하는 기능을 포함합니다.
- 데이터베이스 마이그레이션: 다른 데이터베이스 시스템 간의 데이터 이전을 지원하여 데이터베이스 마이그레이션 작업을 간소화합니다.
사용자 인터페이스 및 사용성
DBeaver는 직관적인 사용자 인터페이스를 제공하여 사용자가 쉽게 데이터베이스와 상호작용할 수 있습니다. 메인 윈도우는 데이터베이스 연결, SQL 편집기, 데이터 뷰어 및 로그 등 여러 탭으로 구성됩니다.
커뮤니티 및 지원
DBeaver는 활발한 오픈 소스 커뮤니티를 통해 지속적으로 개선되고 있으며, 사용자 문제 해결을 돕기 위한 광범위한 문서와 포럼이 제공됩니다. 사용자는 이러한 자원을 통해 문제를 해결하고 다른 사용자와 지식을 공유할 수 있습니다.
설치 및 설정
DBeaver를 설치하는 과정은 운영 체제에 따라 다르지만, 일반적으로 공식 웹사이트에서 다운로드하여 설치할 수 있습니다. 설치 후, 데이터베이스에 연결하려면 적절한 데이터베이스 드라이버를 설치하고 연결 정보를 설정해야 합니다.
이 문서를 참고하여 DBeaver를 효과적으로 사용하고, 다양한 데이터베이스 작업을 보다 쉽게 수행할 수 있기를 바랍니다.
Mac 설치
- Google에 DBeaver 를 검색

M1, M2의 경우 Apple silicon을 그 이전의 경우 Intel을 선택

DBMS 연결하기
- 좌측 상단 파일 아래에 + 버튼을 누릅니다.

연결할 DBMS 제품을 선택합니다.

SQL 기본
관계형 데이터베이스 개요
데이터베이스 (Database)
데이터베이스는 관련된 데이터들을 체계적으로 저장하고 관리할 수 있도록 구성된 데이터의 집합입니다. 데이터베이스는 데이터를 중복 최소화, 데이터 무결성 및 일관성 유지, 효율적인 데이터 접근 및 검색을 위한 목적으로 설계됩니다.
DBMS (데이터베이스 관리 시스템)
DBMS는 데이터베이스를 관리하기 위한 소프트웨어 시스템입니다. DBMS는 사용자와 데이터베이스 간의 인터페이스 역할을 하며, 데이터의 저장, 검색, 수정, 삭제 등을 수행합니다. DBMS의 주요 기능은 다음과 같습니다.
- 데이터 정의: 데이터베이스 스키마를 생성, 수정, 삭제할 수 있습니다.
- 데이터 조작: 데이터를 삽입, 수정, 삭제 및 검색할 수 있습니다.
- 데이터 보안: 데이터 접근 권한을 관리하여 민감한 정보를 보호합니다.
- 데이터 무결성: 데이터베이스 내의 데이터가 정확하고 일관성이 유지되도록 합니다.
- 트랜잭션 관리: 여러 작업이 동시에 수행될 때 데이터의 일관성을 유지하고, 시스템 장애가 발생했을 때 데이터를 복구할 수 있습니다.
SQL (Structured Query Language)
SQL은 관계형 데이터베이스 관리 시스템(RDBMS)에서 데이터를 정의, 조작, 제어하기 위해 사용되는 표준화된 프로그래밍 언어입니다. SQL을 사용하면 사용자가 데이터베이스에 데이터를 저장, 수정, 삭제 및 검색할 수 있습니다.
SQL은 크게 다음과 같은 4가지 종류로 분류됩니다.
- DDL (Data Definition Language): 데이터베이스 스키마를 생성, 변경, 삭제하기 위한 명령어들입니다.
- DML (Data Manipulation Language): 데이터를 검색, 삽입, 수정, 삭제하기 위한 명령어들입니다.
- DCL (Data Control Language): 데이터베이스 사용자의 권한을 관리하기 위한 명령어들입니다.
- TCL (Transaction Control Language): 데이터베이스 트랜잭션을 관리하기 위한 명령어들입니다.
아래 표에서 각 SQL의 종류와 대표적인 명령어를 확인할 수 있습니다.

데이터베이스 테이블의 개념
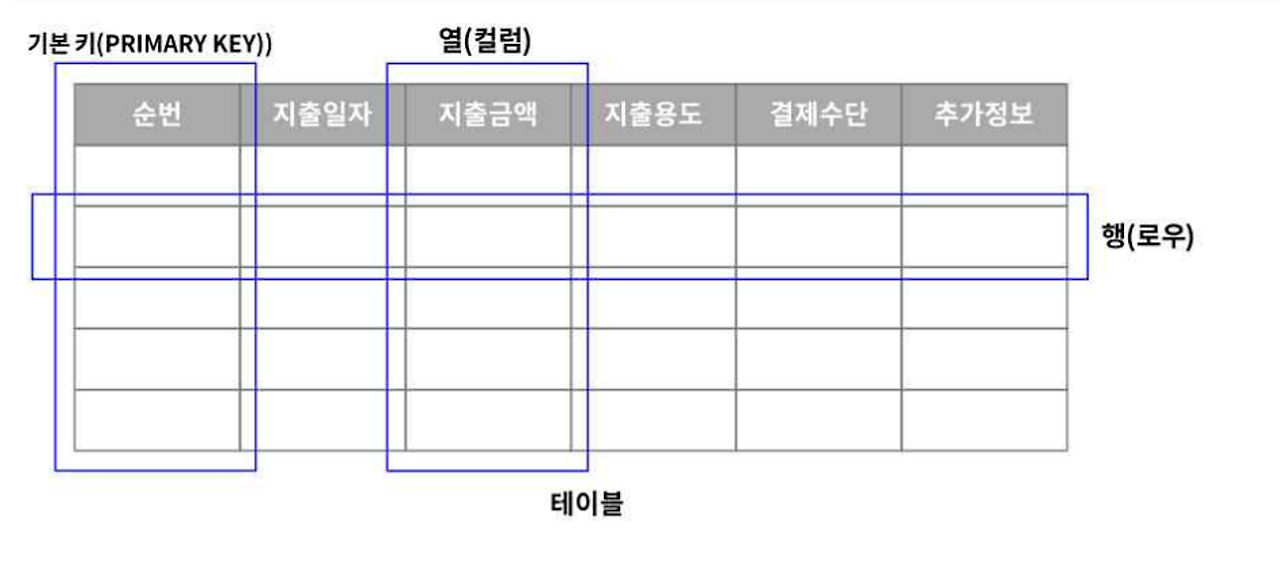
데이터베이스 테이블은 관계형 데이터베이스에서 데이터를 구조화하여 저장하는 기본 단위입니다. 테이블은 행(row)과 열(column)의 2차원 구조로 이루어져 있으며, 각 행은 개별 레코드를 나타내고, 각 열은 레코드의 속성을 나타냅니다.
테이블의 구성 요소
- 행 (Row): 행은 데이터베이스 테이블에서 개별 레코드를 나타냅니다. 한 행은 테이블의 모든 열에 대한 값을 포함하며, 각각의 행은 고유한 식별자(예: 기본 키)를 가질 수 있습니다.
- 열 (Column): 열은 데이터베이스 테이블에서 특정 속성을 나타냅니다. 각 열은 이름과 데이터 타입을 가지며, 제약 조건이나 기본값 등 추가 속성을 설정할 수 있습니다.
- 기본 키 (Primary Key): 기본 키는 테이블에서 각 행을 고유하게 식별하는 열입니다. 기본 키로 설정된 열은 NULL 값을 가질 수 없고, 각 행에 대해 고유한 값을 가져야 합니다.
- 외래 키 (Foreign Key): 외래 키는 다른 테이블의 기본 키를 참조하는 열입니다. 외래 키를 사용하면 서로 다른 테이블 간의 관계를 정의하고, 데이터 무결성을 유지할 수 있습니다.
데이터베이스 테이블은 이러한 구성 요소를 바탕으로 데이터를 체계적으로 저장하고 관리할 수 있습니다. 테이블 간의 관계를 통해 효율적인 데이터 모델링 및 검색이 가능하며, 무결성과 일관성을 유지할 수 있습니다.
ERD (Entity-Relationship Diagram)
ERD(Entity-Relationship Diagram)는 데이터베이스의 구조와 관계를 그래픽적으로 표현한 도표입니다. 데이터베이스 설계 과정에서 ERD를 사용하여 데이터의 구조와 관계를 명확하게 이해하고, 효율적인 데이터 모델을 만들기 위한 청사진을 작성할 수 있습니다. ERD는 주로 엔티티, 속성, 관계 등의 기본 요소로 구성되어 있습니다.
ERD의 주요 구성 요소
- 엔터티 (Entity): 엔터티는 데이터베이스에서 관리하려는 실체나 개체를 나타냅니다. 엔티티는 일반적으로 테이블과 일치하며, ERD에서는 직사각형으로 표현됩니다.
- 속성 (Attribute): 속성은 엔티티의 특징이나 성질을 나타내며, 데이터베이스 테이블의 열(column)에 해당합니다. 속성은 ERD에서 원 또는 타원으로 표현되며, 해당 엔티티와 연결됩니다.
- 관계 (Relationship): 관계는 서로 다른 엔티티 간의 연결을 나타냅니다. 관계는 일대일, 일대다, 다대다 등의 다양한 형태로 존재할 수 있으며, ERD에서는 마름모로 표현되고, 관련된 엔티티와 직선으로 연결됩니다.
ERD 작성 방법
데이터베이스 ERD를 작성하는 과정은 다음과 같습니다.
- 엔티티 식별: 데이터베이스에서 관리하고자 하는 개체나 실체를 파악하고, 엔티티를 정의합니다.
- 속성 결정: 각 엔티티에 대한 속성을 식별하고, 엔티티와 속성을 연결합니다.
- 관계 설정: 서로 다른 엔티티 간의 관계를 파악하고, ERD에 관계를 표현합니다.
- 정규화: 데이터 중복을 최소화하고, 데이터 무결성을 보장하기 위해 정규화 과정을 수행합니다.
ERD를 작성하면 데이터베이스의 전체 구조와 관계를 한눈에 파악할 수 있어 설계 과정에서 문제점을 사전에 발견하고 수정할 수 있습니다.
또한, ERD를 통해 데이터베이스 설계자와 개발자 간의 의사소통이 원활해지며, 시스템에 대한 전반적인 이해를 높일 수 있습니다. 최종적으로 ERD를 바탕으로 실제 데이터베이스 스키마를 생성할 수 있으며, 이를 통해 효율적인 데이터 모델을 구축할 수 있습니다.
요약하자면, 데이터베이스 ERD는 데이터베이스의 구조와 관계를 시각적으로 표현하는 도구로, 데이터베이스 설계 및 구축 과정에서 필수적인 역할을 수행합니다. 엔티티, 속성, 관계 등의 구성 요소를 통해 데이터베이스의 전반적인 구조를 파악하고, 효율적인 데이터 모델을 만들 수 있습니다.
실습 데이터 모델 ERD
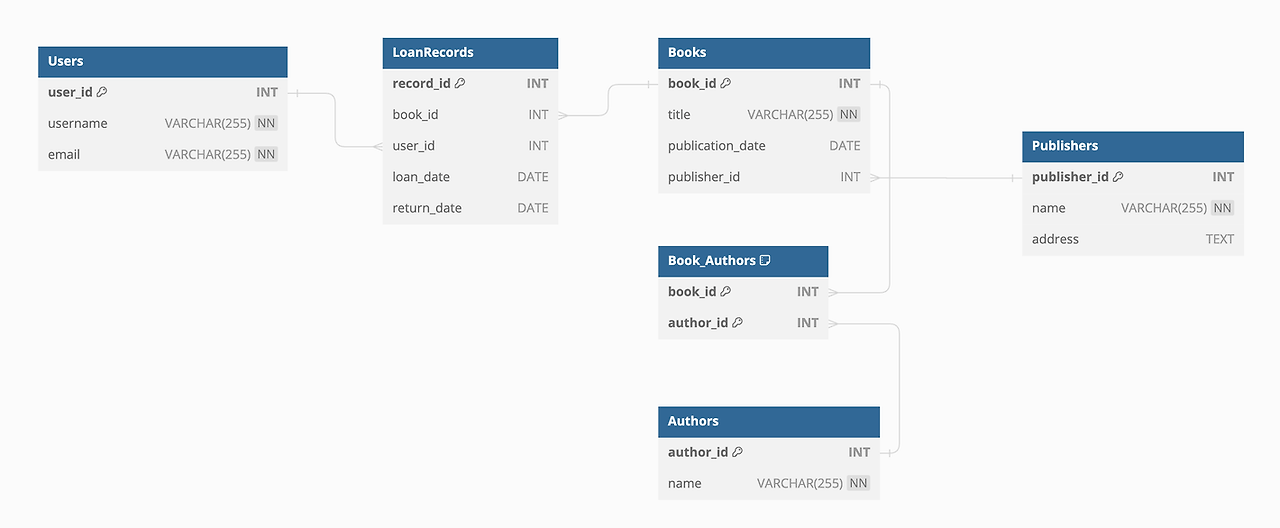
DDL
CREATE TABLE문
- 아래 표는 Database에서 사용하는 주요 데이터 타입에 대한 정보를 제공합니다.

- 예시 테이블 생성 구문:
-- 사용자 테이블
CREATE TABLE Users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);
-- 출판사 테이블
CREATE TABLE Publishers (
publisher_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
address TEXT
);
-- 도서 테이블
CREATE TABLE Books (
book_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
publication_date DATE,
publisher_id INT,
FOREIGN KEY (publisher_id) REFERENCES Publishers(publisher_id)
);
-- 저자 테이블
CREATE TABLE Authors (
author_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
-- 대출 기록 테이블
CREATE TABLE LoanRecords (
record_id INT AUTO_INCREMENT PRIMARY KEY,
book_id INT,
user_id INT,
loan_date DATE,
return_date DATE,
FOREIGN KEY (book_id) REFERENCES Books(book_id),
FOREIGN KEY (user_id) REFERENCES Users(user_id)
);
-- 도서와 저자의 다대다 관계를 위한 테이블
CREATE TABLE Book_Authors (
book_id INT,
author_id INT,
PRIMARY KEY (book_id, author_id),
FOREIGN KEY (book_id) REFERENCES Books(book_id),
FOREIGN KEY (author_id) REFERENCES Authors(author_id)
);
- 오라클 기준
-- 사용자 테이블
CREATE TABLE Users (
user_id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
username VARCHAR2(255) NOT NULL,
email VARCHAR2(255) NOT NULL UNIQUE
);
-- 출판사 테이블
CREATE TABLE Publishers (
publisher_id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
name VARCHAR2(255) NOT NULL,
address CLOB
);
-- 도서 테이블
CREATE TABLE Books (
book_id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
title VARCHAR2(255) NOT NULL,
publication_date DATE,
publisher_id INT,
CONSTRAINT fk_publisher
FOREIGN KEY (publisher_id)
REFERENCES Publishers(publisher_id)
);
-- 저자 테이블
CREATE TABLE Authors (
author_id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
name VARCHAR2(255) NOT NULL
);
-- 대출 기록 테이블
CREATE TABLE LoanRecords (
record_id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
book_id INT,
user_id INT,
loan_date DATE,
return_date DATE,
CONSTRAINT fk_book
FOREIGN KEY (book_id)
REFERENCES Books(book_id),
CONSTRAINT fk_user
FOREIGN KEY (user_id)
REFERENCES Users(user_id)
);
-- 도서와 저자의 다대다 관계를 위한 테이블
CREATE TABLE Book_Authors (
book_id INT,
author_id INT,
PRIMARY KEY (book_id, author_id),
CONSTRAINT fk_book_authors_book
FOREIGN KEY (book_id)
REFERENCES Books(book_id),
CONSTRAINT fk_book_authors_author
FOREIGN KEY (author_id)
REFERENCES Authors(author_id)
);테이블 이름 생성 규칙
- 유효한 문자 사용: 테이블 이름은 알파벳, 숫자, 밑줄(_)로 구성되어야 합니다. 특수 문자나 공백을 사용하지 않는 것이 좋습니다.
- 첫 글자: 테이블 이름은 알파벳 문자로 시작해야 합니다. 숫자나 밑줄로 시작하는 이름은 피하세요.
- 길이 제한: 테이블 이름은 일반적으로 길이 제한이 있습니다. 이 제한은 데이터베이스 시스템마다 다르지만, 일반적으로 30자 이내의 길이로 제한됩니다.
- 의미 있는 이름 사용: 테이블 이름은 데이터를 담고 있는 내용을 명확하게 설명할 수 있도록 의미 있는 이름을 사용하세요. 축약어는 가능한 피하고, 전체 단어를 사용하는 것이 좋습니다.
- 단수/복수형 일관성: 테이블 이름에 단수형 또는 복수형을 사용할 때 일관성을 유지하세요. 팀 내에서 사용하는 규칙을 명확하게 정하고 따르는 것이 좋습니다.
- 예약어 피하기: 데이터베이스 시스템에서 사용하는 예약어를 테이블 이름으로 사용하지 않는 것이 좋습니다. 예약어를 사용하면 SQL 쿼리 작성 시 혼란을 초래할 수 있습니다.
테이블 이름을 만들 때 위의 규칙과 권장 사항을 따르면, 데이터베이스 구조를 명확하게 이해하고 관리하기 쉬워집니다. 다양한 데이터베이스 시스템에서 작동되도록 테이블 이름을 설정하고, 팀 내에서 일관된 명명 규칙을 유지하는 것이 중요합니다.
제약조건 (constraints)
- 제약 조건(constraints)은 데이터베이스 테이블의 열에 적용되어 데이터의 무결성을 유지하는데 도움을 줍니다. 제약 조건을 사용하면, 데이터베이스에 저장되는 값들이 특정 규칙에 부합하도록 강제할 수 있습니다.
- 오라클 데이터베이스에서 사용되는 주요 제약 조건에 대한 개념 설명은 다음과 같습니다.

ON DELETE 옵션
On Delete 옵션은 RDBMS에서 외래 키(Foreign Key) 제약 조건에서 사용되며, 참조된 테이블의 레코드가 삭제될 때 어떻게 처리할지를 지정하는 옵션입니다.
다음은 On Delete 옵션의 종류입니다.
1. Cascading
참조된 레코드가 삭제될 때 해당 레코드를 참조하는 다른 레코드도 함께 삭제합니다.
-- 출판사 테이블
CREATE TABLE Publishers (
publisher_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
address TEXT
);
-- 도서 테이블
CREATE TABLE Books (
book_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
publication_date DATE,
publisher_id INT,
FOREIGN KEY (publisher_id) REFERENCES Publishers(publisher_id) ON DELETE CASCADE
);
INSERT INTO Publishers (name, address) VALUES ('Alpha Publishing', '123 Alpha St, New York, NY');
INSERT INTO Publishers (name, address) VALUES ('Beta Books', '234 Beta Rd, San Francisco, CA');
INSERT INTO Publishers (name, address) VALUES ('Gamma Press', '345 Gamma Blvd, Chicago, IL');
INSERT INTO Publishers (name, address) VALUES ('Delta Media', '456 Delta Ave, Los Angeles, CA');
INSERT INTO Publishers (name, address) VALUES ('Epsilon Publications', '567 Epsilon Way, Houston, TX');
INSERT INTO Publishers (name, address) VALUES ('Zeta Publishing House', '678 Zeta St, Phoenix, AZ');
INSERT INTO Publishers (name, address) VALUES ('Eta Publishing Group', '789 Eta Rd, Philadelphia, PA');
INSERT INTO Publishers (name, address) VALUES ('Theta Books', '890 Theta Blvd, San Antonio, TX');
INSERT INTO Publishers (name, address) VALUES ('Iota Press', '901 Iota Ave, San Diego, CA');
INSERT INTO Publishers (name, address) VALUES ('Kappa Media', '101 Kappa Way, Dallas, TX');
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Introduction to AI', '2022-01-15', 1);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Advanced SQL', '2022-02-20', 2);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Learning Python', '2023-03-25', 3);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Web Development', '2021-04-30', 4);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Cloud Computing Basics', '2023-05-05', 5);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Data Structures', '2021-06-10', 6);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Operating Systems', '2022-07-15', 7);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Network Security', '2021-08-20', 8);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Mobile App Development', '2022-09-25', 9);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Machine Learning for Beginners', '2023-10-30', 10);위 예시 코드에서 publisher_id 컬럼은 Publishers 테이블의 publisher_id 컬럼을 참조하는 외래 키(Foreign Key)입니다. ON DELETE CASCADE 옵션이 설정되어 있으므로 Publishers 테이블의 레코드가 삭제될 때 해당 publisher_id를 참조하는 Books 테이블의 레코드도 함께 삭제됩니다.
2. Restrict
참조된 레코드가 삭제될 때 해당 레코드를 참조하는 다른 레코드를 삭제하지 않습니다.
-- 출판사 테이블
CREATE TABLE Publishers (
publisher_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
address TEXT
);
-- 도서 테이블
CREATE TABLE Books (
book_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
publication_date DATE,
publisher_id INT,
FOREIGN KEY (publisher_id) REFERENCES Publishers(publisher_id) ON DELETE RESTRICT
);
INSERT INTO Publishers (name, address) VALUES ('Alpha Publishing', '123 Alpha St, New York, NY');
INSERT INTO Publishers (name, address) VALUES ('Beta Books', '234 Beta Rd, San Francisco, CA');
INSERT INTO Publishers (name, address) VALUES ('Gamma Press', '345 Gamma Blvd, Chicago, IL');
INSERT INTO Publishers (name, address) VALUES ('Delta Media', '456 Delta Ave, Los Angeles, CA');
INSERT INTO Publishers (name, address) VALUES ('Epsilon Publications', '567 Epsilon Way, Houston, TX');
INSERT INTO Publishers (name, address) VALUES ('Zeta Publishing House', '678 Zeta St, Phoenix, AZ');
INSERT INTO Publishers (name, address) VALUES ('Eta Publishing Group', '789 Eta Rd, Philadelphia, PA');
INSERT INTO Publishers (name, address) VALUES ('Theta Books', '890 Theta Blvd, San Antonio, TX');
INSERT INTO Publishers (name, address) VALUES ('Iota Press', '901 Iota Ave, San Diego, CA');
INSERT INTO Publishers (name, address) VALUES ('Kappa Media', '101 Kappa Way, Dallas, TX');
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Introduction to AI', '2022-01-15', 1);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Advanced SQL', '2022-02-20', 2);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Learning Python', '2023-03-25', 3);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Web Development', '2021-04-30', 4);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Cloud Computing Basics', '2023-05-05', 5);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Data Structures', '2021-06-10', 6);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Operating Systems', '2022-07-15', 7);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Network Security', '2021-08-20', 8);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Mobile App Development', '2022-09-25', 9);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Machine Learning for Beginners', '2023-10-30', 10);위 예시 코드에서 publisher_id 컬럼은 Publishers 테이블의 publisher_id 컬럼을 참조하는 외래 키(Foreign Key)입니다. ON DELETE RESTRICT 옵션이 설정되어 있으므로 Publishers 테이블의 레코드가 삭제될 때 해당 publisher_id를 참조하는 Books 테이블의 레코드를 삭제하지 않습니다.
3. Set Null
참조된 레코드가 삭제될 때 해당 레코드를 참조하는 다른 레코드의 컬럼 값을 Null로 설정합니다.
-- 출판사 테이블
CREATE TABLE Publishers (
publisher_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
address TEXT
);
-- 도서 테이블
CREATE TABLE Books (
book_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
publication_date DATE,
publisher_id INT NULL, -- publisher_id 칼럼이 NULL을 허용하도록 설정
FOREIGN KEY (publisher_id) REFERENCES Publishers(publisher_id) ON DELETE SET NULL
);
INSERT INTO Publishers (name, address) VALUES ('Alpha Publishing', '123 Alpha St, New York, NY');
INSERT INTO Publishers (name, address) VALUES ('Beta Books', '234 Beta Rd, San Francisco, CA');
INSERT INTO Publishers (name, address) VALUES ('Gamma Press', '345 Gamma Blvd, Chicago, IL');
INSERT INTO Publishers (name, address) VALUES ('Delta Media', '456 Delta Ave, Los Angeles, CA');
INSERT INTO Publishers (name, address) VALUES ('Epsilon Publications', '567 Epsilon Way, Houston, TX');
INSERT INTO Publishers (name, address) VALUES ('Zeta Publishing House', '678 Zeta St, Phoenix, AZ');
INSERT INTO Publishers (name, address) VALUES ('Eta Publishing Group', '789 Eta Rd, Philadelphia, PA');
INSERT INTO Publishers (name, address) VALUES ('Theta Books', '890 Theta Blvd, San Antonio, TX');
INSERT INTO Publishers (name, address) VALUES ('Iota Press', '901 Iota Ave, San Diego, CA');
INSERT INTO Publishers (name, address) VALUES ('Kappa Media', '101 Kappa Way, Dallas, TX');
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Introduction to AI', '2022-01-15', 1);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Advanced SQL', '2022-02-20', 2);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Learning Python', '2023-03-25', 3);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Web Development', '2021-04-30', 4);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Cloud Computing Basics', '2023-05-05', 5);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Data Structures', '2021-06-10', 6);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Operating Systems', '2022-07-15', 7);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Network Security', '2021-08-20', 8);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Mobile App Development', '2022-09-25', 9);
INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Machine Learning for Beginners', '2023-10-30', 10);위 예시 코드에서 publisher_id 컬럼은 Publishers 테이블의 publisher_id 컬럼을 참조하는 외래 키(Foreign Key)입니다. ON DELETE SET NULL 옵션이 설정되어 있으므로 Publishers 테이블의 레코드가 삭제될 때 해당 publisher_id를 참조하는 Books 테이블의 레코드의 publisher_id 컬럼 값을 Null로 설정합니다.
On Delete 옵션을 적절하게 사용하면 데이터의 무결성(Integrity)을 보장할 수 있습니다.
ALTER문
ALTER 문은 데이터베이스에서 기존의 데이터베이스 객체를 수정하는데 사용됩니다. ALTER 문을 사용하여 테이블, 인덱스, 시퀀스, 뷰 등의 데이터베이스 객체를 변경할 수 있습니다.
ALTER 문의 주요 사용 사례는 다음과 같습니다:
- 테이블에 열 추가, 수정, 삭제하기
- 제약 조건 추가, 수정, 삭제하기
- 인덱스 상태 변경하기 (활성화 또는 비활성화)
- 시퀀스의 시작값, 증가값, 최대값 등 변경하기
- 뷰 정의 변경하기
ALTER 문의 주요 종류는 다음과 같습니다:
- ALTER TABLE: 기존 테이블을 수정하는 데 사용됩니다. 열 추가, 열 삭제, 열 데이터 타입 변경, 제약 조건 추가/삭제/수정 등의 작업을 수행할 수 있습니다.
-- 열 추가 ALTER TABLE Users ADD phone_number VARCHAR(20) NOT NULL; -- 열 삭제 ALTER TABLE Books DROP COLUMN publication_date; -- 데이터 타입 변경 ALTER TABLE Authors MODIFY name TEXT NOT NULL; -- 제약 조건 추가 ALTER TABLE Users ADD CONSTRAINT unique_username UNIQUE (username); -- 제약 조건 삭제 ALTER TABLE Users DROP CONSTRAINT unique_username; -- 제약 조건 삭제 ALTER TABLE Books DROP FOREIGN KEY fk_publisher_id; - ALTER INDEX: 기존 인덱스를 수정하는 데 사용됩니다. 인덱스의 상태를 변경하거나 재구성할 수 있습니다.
-- 인덱스 비활성화 ALTER TABLE Books DISABLE INDEX idx_title; -- 인덱스 활성화 ALTER TABLE Books ENABLE INDEX idx_title;
ALTER 문을 사용하여 데이터베이스 객체를 필요에 따라 변경할 수 있습니다. 이를 통해 데이터베이스의 구조를 유지하면서 업데이트하거나 수정할 수 있습니다.
DROP TABLE, TRUNCATE TABLE, RENAME
- DROP TABLE: DROP TABLE 문은 데이터베이스에서 테이블을 완전히 삭제하는 데 사용됩니다. 이 명령은 테이블과 그 테이블에 관련된 모든 데이터, 인덱스, 제약 조건, 트리거, 권한 등을 제거합니다. 삭제한 테이블은 복구할 수 없으므로 주의해야 합니다.
DROP TABLE Books; - RENAME: RENAME문은 테이블의 이름을 변경하는 데 사용됩니다. 이 명령은 테이블의 구조나 데이터에 영향을 주지 않고 오직 이름만 변경합니다.
RENAME TABLE Books TO Book; - TRUNCATE TABLE: TRUNCATE TABLE 문은 테이블의 모든 데이터를 빠르게 삭제하는 데 사용됩니다. 이 명령은 테이블의 구조, 인덱스, 제약 조건 등은 그대로 유지하면서 오직 데이터만 삭제합니다. TRUNCATE는 롤백이 불가능하며, DELETE 문보다 더 빠르게 데이터를 삭제할 수 있습니다.
-- 출판사 테이블 CREATE TABLE Publishers ( publisher_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255) NOT NULL, address TEXT ); -- 도서 테이블 CREATE TABLE Books ( book_id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(255) NOT NULL, publication_date DATE, publisher_id INT, FOREIGN KEY (publisher_id) REFERENCES Publishers(publisher_id) ); INSERT INTO Publishers (name, address) VALUES ('Alpha Publishing', '123 Alpha St, New York, NY'); INSERT INTO Publishers (name, address) VALUES ('Beta Books', '234 Beta Rd, San Francisco, CA'); INSERT INTO Publishers (name, address) VALUES ('Gamma Press', '345 Gamma Blvd, Chicago, IL'); INSERT INTO Publishers (name, address) VALUES ('Delta Media', '456 Delta Ave, Los Angeles, CA'); INSERT INTO Publishers (name, address) VALUES ('Epsilon Publications', '567 Epsilon Way, Houston, TX'); INSERT INTO Publishers (name, address) VALUES ('Zeta Publishing House', '678 Zeta St, Phoenix, AZ'); INSERT INTO Publishers (name, address) VALUES ('Eta Publishing Group', '789 Eta Rd, Philadelphia, PA'); INSERT INTO Publishers (name, address) VALUES ('Theta Books', '890 Theta Blvd, San Antonio, TX'); INSERT INTO Publishers (name, address) VALUES ('Iota Press', '901 Iota Ave, San Diego, CA'); INSERT INTO Publishers (name, address) VALUES ('Kappa Media', '101 Kappa Way, Dallas, TX'); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Introduction to AI', '2022-01-15', 1); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Advanced SQL', '2022-02-20', 2); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Learning Python', '2023-03-25', 3); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Web Development', '2021-04-30', 4); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Cloud Computing Basics', '2023-05-05', 5); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Data Structures', '2021-06-10', 6); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Operating Systems', '2022-07-15', 7); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Network Security', '2021-08-20', 8); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Mobile App Development', '2022-09-25', 9); INSERT INTO Books (title, publication_date, publisher_id) VALUES ('Machine Learning for Beginners', '2023-10-30', 10);
--아래는 따로 실행할 예
TRUNCATE TABLE Books;
DROP TABLE과 TRUNCATE TABLE의 차이점:
- 복구 가능성: DROP TABLE은 테이블 자체를 삭제하므로 복구할 수 없습니다. TRUNCATE TABLE은 테이블의 데이터만 삭제하므로 테이블 구조는 복구 가능합니다.
- 영향 받는 객체: DROP TABLE은 테이블과 관련된 인덱스, 제약 조건, 트리거, 권한 등 모든 객체를 삭제합니다. TRUNCATE TABLE은 오직 데이터만 삭제하고, 다른 객체는 그대로 둡니다.
- 속도: TRUNCATE TABLE은 테이블의 모든 데이터를 빠르게 삭제하는 데 반해, DROP TABLE은 테이블 자체를 삭제하므로 시간이 다소 걸릴 수 있습니다.
- 트랜잭션 및 롤백: TRUNCATE TABLE은 트랜잭션을 사용하지 않으며 롤백이 불가능합니다. 반면, DROP TABLE은 트랜잭션을 사용하며 롤백이 가능합니다(단, 오라클에서는 롤백이 불가능합니다).
- 용도: DROP TABLE은 테이블을 완전히 제거할 때 사용되며, TRUNCATE TABLE은 테이블의 데이터만 빠르게 삭제하려는 경우 사용됩니다.
DML
-- 사용자 테이블
CREATE TABLE Users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);
-- 출판사 테이블
CREATE TABLE Publishers (
publisher_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
address TEXT
);
-- 도서 테이블
CREATE TABLE Books (
book_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
publication_date DATE,
publisher_id INT,
FOREIGN KEY (publisher_id) REFERENCES Publishers(publisher_id)
);
-- 저자 테이블
CREATE TABLE Authors (
author_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
-- 대출 기록 테이블
CREATE TABLE LoanRecords (
record_id INT AUTO_INCREMENT PRIMARY KEY,
book_id INT,
user_id INT,
loan_date DATE,
return_date DATE,
FOREIGN KEY (book_id) REFERENCES Books(book_id),
FOREIGN KEY (user_id) REFERENCES Users(user_id)
);
-- 도서와 저자의 다대다 관계를 위한 테이블
CREATE TABLE Book_Authors (
book_id INT,
author_id INT,
PRIMARY KEY (book_id, author_id),
FOREIGN KEY (book_id) REFERENCES Books(book_id),
FOREIGN KEY (author_id) REFERENCES Authors(author_id)
);
INSERT INTO Users (username, email) VALUES
('johndoe', 'johndoe@example.com'),
('janedoe', 'janedoe@example.com'),
('alice', 'alice@example.com'),
('bob', 'bob@example.com'),
('charlie', 'charlie@example.com'),
('david', 'david@example.com'),
('eve', 'eve@example.com'),
('frank', 'frank@example.com'),
('grace', 'grace@example.com'),
('hannah', 'hannah@example.com');
INSERT INTO Publishers (name, address) VALUES
('Penguin Books', '123 Penguin Street'),
('HarperCollins', '234 Harper Road'),
('Simon & Schuster', '345 Simon Blvd'),
('Random House', '456 Random Avenue'),
('Scholastic', '567 School Lane'),
('Hachette', '678 Hatchet Court'),
('Macmillan', '789 Macmillan Lane'),
('Elsevier', '890 Elsevier Rd'),
('Wiley', '901 Wiley Way'),
('Oxford Press', '012 Oxford Circle');
INSERT INTO Books (title, publication_date, publisher_id) VALUES
('Book One', '2020-01-01', 1),
('Book Two', '2020-02-01', 2),
('Book Three', '2020-03-01', 3),
('Book Four', '2020-04-01', 4),
('Book Five', '2020-05-01', 5),
('Book Six', '2020-06-01', 6),
('Book Seven', '2020-07-01', 7),
('Book Eight', '2020-08-01', 8),
('Book Nine', '2020-09-01', 9),
('Book Ten', '2020-10-01', 10);
INSERT INTO Authors (name) VALUES
('Author A'),
('Author B'),
('Author C'),
('Author D'),
('Author E'),
('Author F'),
('Author G'),
('Author H'),
('Author I'),
('Author J');
INSERT INTO LoanRecords (book_id, user_id, loan_date, return_date) VALUES
(1, 1, '2022-01-01', '2022-01-15'),
(2, 2, '2022-02-01', '2022-02-15'),
(3, 3, '2022-03-01', '2022-03-15'),
(4, 4, '2022-04-01', '2022-04-15'),
(5, 5, '2022-05-01', '2022-05-15'),
(6, 6, '2022-06-01', '2022-06-15'),
(7, 7, '2022-07-01', '2022-07-15'),
(8, 8, '2022-08-01', '2022-08-15');
INSERT INTO Book_Authors (book_id, author_id) VALUES
(1, 1),
(2, 2),
(3, 3),
(4, 4),
(5, 5),
(6, 6),
(7, 7),
(8, 8),
(9, 9),
(10, 10);DML 개념
DML(Data Manipulation Language)은 데이터베이스 내의 데이터를 조작하는 데 사용되는 SQL 구문의 한 부분입니다. DML의 주요 구문은 SELECT, INSERT, UPDATE, DELETE 등이 있습니다. 오라클 데이터베이스에서 사용되는 DML 구문에 대해 간략하게 설명하겠습니다.
- SELECT: SELECT문은 데이터베이스에서 데이터를 조회(검색)하는 데 사용됩니다. 특정 테이블에서 원하는 열(column)과 행(row)을 선택하여 결과를 반환합니다.
--모든 사용자의 이름과 이메일 출력 SELECT username, email FROM Users; --모든 저자의 이름 출력: SELECT name FROM Authors; --모든 대출 기록의 대출 날짜와 반납 예정 날짜 출력 SELECT loan_date, return_date FROM LoanRecords; - 예시:
- INSERT: INSERT문은 데이터베이스에 새로운 데이터를 추가하는 데 사용됩니다. 특정 테이블의 행(row)에 값을 지정하여 삽입할 수 있습니다.
--사용자 테이블에 새로운 사용자 추가: INSERT INTO Users (username, email) VALUES ('alice', 'alice@example.com'); --출판사 테이블에 새로운 출판사 추가: INSERT INTO Publishers (name, address) VALUES ('ABC Publishing', '123 Main Street'); --도서 테이블에 새로운 도서 추가: INSERT INTO Books (title, publication_date, publisher_id) VALUES ('The Book Thief', '2005-11-01', 1); --저자 테이블에 새로운 저자 추가: INSERT INTO Authors (name) VALUES ('Markus Zusak'); - 예시:
- UPDATE: UPDATE문은 데이터베이스의 기존 데이터를 수정하는 데 사용됩니다. 특정 테이블에서 행(row)과 열(column)을 선택하여 값을 변경할 수 있습니다.
--특정 사용자의 이메일 변경: UPDATE Users SET email = 'newemail@example.com' WHERE user_id = 1; --특정 도서의 출판 날짜 변경: UPDATE Books SET publication_date = '2006-01-01' WHERE book_id = 1; -- 모든 대출 기록의 반납 날짜를 현재 날짜로 변경: UPDATE LoanRecords SET return_date = CURRENT_DATE; - 예시:
- DELETE: DELETE문은 데이터베이스에서 데이터를 삭제하는 데 사용됩니다. 특정 테이블에서 행(row)을 선택하여 삭제할 수 있습니다.
--특정 사용자 삭제: DELETE FROM Users WHERE user_id = 1; - 예시:
이러한 DML 구문은 오라클 데이터베이스에서 데이터를 검색, 추가, 수정, 삭제할 때 사용됩니다. 이를 활용하여 데이터베이스를 관리하고 필요한 데이터를 조작할 수 있습니다.
INSERT 문
INSERT문은 데이터베이스에 새로운 데이터를 추가하는 데 사용되는 DML(Data Manipulation Language) 중 하나입니다. INSERT문은 기본적으로 두 가지 방법으로 사용할 수 있습니다: 단일 행 삽입 및 다중 행 삽입.
- 단일 행 삽입: 한 번에 하나의 행을 테이블에 삽입하는 방법입니다.
예시:여기서 table_name은 데이터를 삽입하려는 테이블의 이름이고, column1, column2, column3, ...은 값을 삽입하려는 테이블의 열(column)입니다. value1, value2, value3, ...은 해당 열에 삽입할 값입니다.INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...); - --도서 테이블에 새로운 도서 추가: INSERT INTO Books (title, publication_date, publisher_id) VALUES ('The Book Thief', '2005-11-01', 1);
- 기본 구문:
- 다중 행 삽입: 한 번에 여러 행을 테이블에 삽입하는 방법입니다. 이는 테이블에 대량의 데이터를 삽입할 때 효율적입니다.
예시:INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...), (value4, value5, value6, ...), (value7, value8, value9, ...), ...;
INSERT INTO Users (username, email)
VALUES ('alice', 'alice@example.com'),
('bob', 'bob@example.com'),
('charlie', 'charlie@example.com');
INSERT INTO Publishers (name, address)
VALUES ('ABC Publishing', '123 Main Street'),
('DEF Press', '456 Elm Street');
INSERT INTO Books (title, publication_date, publisher_id)
VALUES ('The Book Thief', '2005-11-01', 1),
('Pride and Prejudice', '1813-01-28', 2);
INSERT INTO Authors (name)
VALUES ('Markus Zusak'),
('Jane Austen');
INSERT INTO LoanRecords (book_id, user_id, loan_date)
VALUES (1, 1, '2024-04-30'),
(2, 2, '2024-04-29');
INSERT INTO Book_Authors (book_id, author_id)
VALUES (1, 1),
(2, 2);여기서 각 괄호 안에 있는 값들은 삽입할 행의 데이터를 나타냅니다.
또한, INSERT문을 사용하여 다른 테이블에서 선택한 데이터를 삽입할 수도 있습니다. 이를 INSERT INTO SELECT문이라고 합니다.
- INSERT INTO SELECT: 다른 테이블에서 선택한 데이터를 기반으로 행을 삽입하는 방법입니다.
기본 구문:
INSERT INTO table_name1 (column1, column2, column3, ...)
SELECT column1, column2, column3, ...
FROM table_name2
WHERE condition;
예시:
-- 모든 사용자 이름과 이메일을 'New Users' 테이블에 복사:
CREATE TABLE NewUsers (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);
INSERT INTO NewUsers (username, email)
SELECT username, email
FROM Users;
이 예시에서 NewUsers 테이블에 Users 테이블에서 선택한 데이터를 삽입합니다.
INSERT문을 사용하여 테이블에 데이터를 삽입할 때 주의해야 할 점은 다음과 같습니다:
- NOT NULL 제약 조건이 있는 열에는 NULL 값을 삽입할 수 없습니다. 반드시 값을 제공해야 합니다.
- 기본 키(primary key) 또는 고유 키(unique key) 제약 조건이 있는 열에 중복 값을 삽입하려고 하면 오류가 발생합니다.
- 외래 키(foreign key) 제약 조건이 있는 열에 존재하지 않는 참조 값을 삽입하려고 하면 오류가 발생합니다.
INSERT문을 사용하여 데이터베이스 테이블에 데이터를 삽입하는 방법을 다양한 예시와 함께 설명하였습니다. 이를 통해 데이터를 관리하고 필요한 정보를 저장할 수 있습니다.
UPDATE 문
UPDATE문은 데이터베이스의 기존 데이터를 수정하는 데 사용되는 DML(Data Manipulation Language) 중 하나입니다. UPDATE문을 사용하면 테이블의 행의 값을 변경할 수 있습니다. 이때, WHERE 절을 사용하여 특정 행을 선택할 수 있으며, 원하는 열의 값을 수정할 수 있습니다.
기본 구문:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
여기서 table_name은 데이터를 수정하려는 테이블의 이름이고, column1, column2, ...은 값을 수정하려는 테이블의 열(column)입니다. value1, value2, ...은 해당 열에 수정할 값입니다. 마지막으로 condition은 특정 행을 선택하는 조건입니다.
예시:
--특정 사용자의 이메일 변경:
UPDATE Users
SET email = 'newemail@example.com'
WHERE user_id = 1;
이 예시에서 Users 테이블에서 user_id가 1인 행의 email 값을 수정하였습니다.
UPDATE문을 사용할 때 주의할 점은 다음과 같습니다:
- WHERE 절을 사용하여 특정 행을 선택하지 않으면, 테이블의 모든 행이 업데이트됩니다.
- NOT NULL 제약 조건이 있는 열에 NULL 값을 설정하려고 하면 오류가 발생합니다.
- 기본 키(primary key) 또는 고유 키(unique key) 제약 조건이 있는 열에 중복 값을 설정하려고 하면 오류가 발생합니다.
- 외래 키(foreign key) 제약 조건이 있는 열에 존재하지 않는 참조 값을 설정하려고 하면 오류가 발생합니다.
UPDATE문을 사용할 때 다양한 연산자와 함수를 사용하여 값을 계산하거나 조작할 수 있습니다. 예를 들어, 기존 값에 숫자를 더하거나 빼거나, 문자열을 연결하거나, 날짜를 변경할 수 있습니다.
예시:
-- 특정 사용자의 나이를 1 증가시키기:
UPDATE Users
SET age = age + 1
WHERE user_id = 1;
-- 특정 도서의 출판 연도를 2023으로 변경:
UPDATE Books
SET publication_year = 2023
WHERE book_id = 1;
이 예시에서 Users 테이블에서 user_id가 1인 행의 age 값을 1만큼 증가하였습니다.
UPDATE문을 사용하여 데이터베이스 테이블의 기존 데이터를 수정하는 방법을 다양한 예시와 함께 설명하였습니다. 이를 통해 데이터를 관리하고 필요한 정보를 유지할 수 있습니다.
DELETE 문
DELETE문은 데이터베이스에서 기존 데이터를 삭제하는 데 사용되는 DML(Data Manipulation Language) 중 하나입니다. DELETE문을 사용하면 테이블의 행을 삭제할 수 있습니다. 이때, WHERE 절을 사용하여 특정 행을 선택할 수 있습니다.
기본 구문:
DELETE FROM table_name
WHERE condition;
여기서 table_name은 데이터를 삭제하려는 테이블의 이름이고, condition은 특정 행을 선택하는 조건입니다.
예시:
--사용자 테이블에서 특정 사용자 삭제하기:
DELETE FROM Users WHERE username = 'john_doe';
--도서 테이블에서 특정 도서 삭제하기:
DELETE FROM Books WHERE title = 'Sample Book';
--출판사 테이블에서 주소가 불분명한 출판사 삭제하기:
DELETE FROM Publishers WHERE address IS NULL;
DELETE문을 사용할 때 주의할 점은 다음과 같습니다:
- WHERE 절을 사용하여 특정 행을 선택하지 않으면, 테이블의 모든 행이 삭제됩니다. 이 경우, TRUNCATE문을 사용하는 것이 더 효율적일 수 있습니다.
- 삭제된 데이터는 복구할 수 없으므로, DELETE문을 사용하기 전에 데이터를 백업하거나 데이터를 복구할 수 있는 방법을 고려해야 합니다.
- 외래 키(foreign key) 제약 조건으로 인해 참조 무결성이 깨질 경우, 해당 행을 삭제할 수 없습니다. 이 경우, 참조하는 행을 먼저 삭제하거나 외래 키 제약 조건을 수정해야 합니다.
DELETE문을 사용하여 데이터베이스 테이블에서 행을 삭제하는 방법을 다양한 예시와 함께 설명하였습니다. 이를 통해 데이터를 관리하고 필요한 정보를 유지할 수 있습니다.
DELETE FROM 과 TRUNCATE TABLE의 차이
DELETE FROM과 TRUNCATE TABLE은 데이터베이스에서 행을 삭제하는 데 사용되는 명령입니다. 두 명령 모두 유사한 결과를 얻지만, 작동 방식과 성능, 사용 사례에 차이가 있습니다.
- 작동 방식:
- DELETE FROM은 WHERE 절을 사용하지 않으면 테이블의 모든 행을 하나씩 삭제합니다. 이 경우, 각 행의 삭제에 대한 로그가 기록되고, 트리거가 발생할 수 있습니다.
- TRUNCATE TABLE은 테이블의 모든 데이터를 한 번에 삭제하며, 로그를 남기지 않고 테이블을 초기 상태로 재설정합니다. 이 명령은 트리거를 발생시키지 않습니다.
- 성능:
- DELETE FROM은 각 행을 개별적으로 삭제하므로, 테이블이 큰 경우 실행 속도가 느릴 수 있습니다.
- TRUNCATE TABLE은 테이블의 모든 데이터를 한 번에 삭제하므로, 실행 속도가 빠르고 효율적입니다.
- 사용 사례:
- DELETE FROM은 특정 조건을 만족하는 행을 삭제할 때 사용됩니다. WHERE 절을 사용하지 않으면 모든 행을 삭제할 수 있지만, 이 경우에는 일반적으로 TRUNCATE TABLE을 사용하는 것이 더 효율적입니다.
- TRUNCATE TABLE은 테이블의 모든 데이터를 빠르게 삭제하고자 할 때 사용됩니다. 예를 들어, 테스트 데이터를 삭제하거나 임시 테이블의 데이터를 초기화할 때 사용할 수 있습니다.
실무적 측면에서의 예시:
- DELETE FROM: 개발 중인 웹 애플리케이션에서 특정 날짜 이전의 테스트 데이터를 삭제하려면 DELETE FROM을 사용하여 WHERE 절을 포함하여 특정 조건을 충족하는 행을 삭제할 수 있습니다.
DELETE FROM LoanRecords
WHERE loan_date < '2022-01-01';
- TRUNCATE TABLE: 하루에 한 번씩 임시 데이터를 삭제해야 하는 시나리오에서는 TRUNCATE TABLE을 사용하여 임시 테이블의 모든 데이터를 빠르게 삭제할 수 있습니다.
TRUNCATE TABLE temporary_data;
요약하면, DELETE FROM은 특정 조건을 충족하는 행을 삭제할 때 사용되며, TRUNCATE TABLE은 테이블의 모든 데이터를 빠르게 삭제할 때 사용됩니다. 실무에서는 상황에 따라 적절한 명령을 선택하여 사용해야 합니다.
데이터베이스에서 행을 삭제할 때 DELETE FROM을 사용하는 경우:
- 특정 조건을 충족하는 행만 삭제하려는 경우
- 트리거를 발생시키려는 경우
- 삭제 과정을 로깅하려는 경우
반면에, TRUNCATE TABLE을 사용하는 경우:
- 테이블의 모든 데이터를 빠르게 삭제하려는 경우
- 트리거를 발생시키지 않으려는 경우
- 삭제 과정을 로깅하지 않으려는 경우
실무적인 예를 들자면, 웹 애플리케이션에서 사용자가 작성한 댓글을 삭제할 때 DELETE FROM을 사용하여 특정 댓글만 삭제할 수 있습니다. 반면에, 일정 기간이 지난 후 사용되지 않는 임시 데이터를 삭제하려면 TRUNCATE TABLE을 사용하여 테이블의 모든 데이터를 빠르게 삭제할 수 있습니다. 이렇게 상황에 따라 적절한 명령을 선택하여 사용하면 데이터베이스에서 행을 효율적으로 삭제할 수 있습니다.
SELECT 문
SELECT 문은 데이터베이스 테이블에서 원하는 데이터를 조회하는 데 사용됩니다. 기본 사용법과 DISTINCT, 문자열 연결 연산자 ||, 그리고 별칭(alias) 지정에 대해 설명하겠습니다.
1. 기본 사용법 :
기본적으로 SELECT문은 다음과 같은 형태를 가집니다.
SELECT column_name1, column_name2, ... FROM table_name;예를 들어, Authors테이블에서 name열을 조회하려면 다음과 같이 작성할 수 있습니다.
SELECT name FROM Authors;2. DISTINCT :
DISTINCT 키워드는 중복된 값을 제거하고 고유한 값만 조회하려는 경우 사용됩니다.
SELECT DISTINCT column_name FROM table_name;SELECT DISTINCT name FROM Authors;3. 문자열 연결 연산자 ||:
|| 연산자를 사용하여 문자열을 연결할 수 있습니다.
SELECT column_name1 || ' ' || column_name2 AS new_column_name FROM table_name;예를 들어, Users 테이블에서 username과 email을 연결하여 name_email으로 조회하려면 다음과 같이 작성할 수 있습니다.
SELECT username || ' ' || email AS name_mail FROM Users;4. 별칭(alias) 지정:
SELECT문에서 별칭(alias)을 사용하면 열 이름이나 표현식에 다른 이름을 지정할 수 있습니다. 별칭을 사용하면 결과셋의 가독성을 높이고 쿼리를 더 간결하게 작성할 수 있습니다.
SELECT column_name AS alias_name FROM table_name;예를 들어, Users 테이블에서 username열을 이름이라는 별칭으로 조회하려면 다음과 같이 작성할 수 있습니다.
SELECT username AS 이름 FROM Users;