
AOP(Aspect Oriented Programming)
이번 시간에는 Spring Framework의 3대 핵심 개념 중 하나인 AOP에 대해서 살펴보도록 하겠습니다.

[그림 2-11] Spring 삼각형 - AOP 설명
AOP(Aspect Oriented Programming)란?
AOP란 무엇일까요? AOP를 한글로 번역하면 관심 지향 프로그래밍 정도로 해석할 수 있습니다.
OOP(Object Oriented Programmig)란 객체 지향 프로그래밍 즉, 객체 간의 관계를 지향하는 프로그래밍 방식이라는 사실을 이제는 잘 알고 있을 거라고 생각합니다.
그렇다면 이 관심(Aspect)을 지향하는 프로그래밍에서 관심은 무엇을 의미하는 것일까요?

위 그림처럼 아기를 키우는 부모들의 육아 방식이나 교육 방식은 제각각 다를 수 있습니다. 어떤 부모들은 아기를 재우기 위해 아기띠를 이용해서 재우지만 또 어떤 부모는 처음부터 침대에 눕혀놓고 재우기도 합니다. 그리고 어떤 부모들은 아기의 언어 발달을 위해서 책을 읽어주는 시간을 많이 가지는 반면에 또 어떤 부모들은 책보다는 동요를 더 많이 들려주는 방식으로 아기의 언어 발달을 도우려 합니다.
그런데 부모들마다 아기를 키우는 방식이 다를 수 있지만 공통되는 부분도 있습니다.
그것은 바로 아기의 건강입니다.
어떤 식으로 아기를 키우든지 아기를 키우는 방식과 별개로 아기가 아프지 않고 잘 자라주었으면 하는 바람은 대부분 부모의 공통된 관심사입니다.
AOP에서의 Aspect는 부모들이 가지고 있는 아기의 건강 같은 공통 관심사와 마찬가지로 애플리케이션에 필요한 기능 중에서 공통적으로 적용되는 공통 기능에 대한 관심과 관련이 있습니다.
공통 관심 사항과 핵심 관심 사항
애플리케이션을 개발하다 보면 애플리케이션 전반에 걸쳐 공통적으로 사용되는 기능들이 있기 마련인데, 이러한 공통 기능들에 대한 관심사를 바로 공통 관심 사항(Cross-cutting concern)이라고 합니다.
그리고 우리가 흔히들 말하는 비즈니스 로직 즉, 애플리케이션의 주목적을 달성하기 위한 핵심 로직에 대한 관심사를 핵심 관심 사항(Core concern)이라고 합니다.
핵심 관심 사항에 반대되는 개념으로 공통 관심 사항을 부가적인 관심 사항이라고 표현하기도 합니다.
커피 주문을 위한 애플리케이션을 예로 들면,
커피 전문점의 주인이 고객에게 제공하는 커피 메뉴를 구성하기 위해 커피 종류를 등록하는 것과 고객이 마시고 싶은 커피를 주문하는 기능은 애플리케이션의 핵심 관심 사항에 해당됩니다.
하지만 커피 주문 애플리케이션에 아무나 접속하지 못하도록 제한하는 애플리케이션 보안에 대한 부분은 애플리케이션 전반에 공통적으로 적용되는 기능이기 때문에 공통 관심 사항에 해당됩니다.

[그림 2-12] 애플리케이션의 공통 관심 사항과 핵심 관심 사항 예
[그림 2-12]는 커피 주문 애플리케이션에서 핵심 관심 사항과 공통 관심 사항을 그림으로 표현한 것입니다.
[그림 2-12]에서 보다시피 로깅, 보안, 트랜잭션 같은 공통 관심 사항 기능들의 화살표가 애플리케이션의 핵심 관심 사항들을 관통하고 있습니다.
이것은 공통 관심 사항의 기능들이 애플리케이션의 핵심 로직에 전반적으로 두루 사용된다는 의미입니다.
그리고 그림에서 보면 공통 관심 사항이 핵심 관심 사항에 멀찌감치 떨어져 있는 것을 볼 수 있는데 이는 공통 관심 사항이 핵심 관심 사항에서 분리되어 있다는 것을 의미합니다.
결국 AOP라는 것은 애플리케이션의 핵심 업무 로직에서 로깅이나 보안, 트랜잭션 같은 공통 기능 로직들을 분리하는 것이라고 생각하면 이해가 빠를 것 같습니다.
AOP가 필요한 이유
그렇다면 애플리케이션의 핵심 로직에서 공통 기능을 분리하는 이유가 무엇일까요?
- 코드의 간결성 유지
- 객체 지향 설계 원칙에 맞는 코드 구현
- 코드의 재사용
상식적으로 생각해도 애플리케이션의 핵심 로직에 공통적인 기능의 코드들이 여기저기 보이면 코드 자체가 복잡해집니다.
코드 구성이 복잡해짐에 따라 버그가 발생할 가능성도 높아지고 유지 보수도 당연히 어려워지는 코드가 될 가능성이 높습니다.
그리고 만약 이런 공통 기능들에 수정이 필요하게 되면 애플리케이션 전반에 적용되어 있는 공통 기능에 해당하는 코드를 일일이 수정해야 되는 치명적인 문제가 발생할 가능성이 높습니다.
애플리케이션을 제작하면서 여러분들이 항상 기본적으로 가졌으면 하는 사고는 ‘어떻게 하면 이 코드를 깔끔하게 유지할 수 있을까?’, ‘어떻게 하면 여기저기 중복되는 코드들을 재사용할 수 있을까?’라는 것입니다.
자신이 구현한 코드를 깔끔하고, 재사용 가능하게 유지하려고 끊임없이 노력하다 보면 어느새 객체지향적인 사고에 익숙해져 있는 여러분들을 만나게 될 것이라고 생각합니다.
AOP에 대한 구체적인 내용은 ‘Spring Framework의 핵심 개념’ 유닛에서 자세히 살펴보도록 하고, 이번 시간에는 AOP가 적용되지 않은 코드와 AOP가 적용된 코드를 비교해 보면서 AOP가 필요한 이유를 체감해 보도록 하겠습니다.
public class Example2_11 {
private Connection connection;
public void registerMember(Member member, Point point) throws SQLException {
connection.setAutoCommit(false); // (1)
try {
saveMember(member); // (2)
savePoint(point); // (2)
connection.commit(); // (3)
} catch (SQLException e) {
connection.rollback(); // (4)
}
}
private void saveMember(Member member) throws SQLException {
PreparedStatement psMember =
connection.prepareStatement("INSERT INTO member (email, password) VALUES (?, ?)");
psMember.setString(1, member.getEmail());
psMember.setString(2, member.getPassword());
psMember.executeUpdate();
}
private void savePoint(Point point) throws SQLException {
PreparedStatement psPoint =
connection.prepareStatement("INSERT INTO point (email, point) VALUES (?, ?)");
psPoint.setString(1, point.getEmail());
psPoint.setInt(2, point.getPoint());
psPoint.executeUpdate();
}
}[코드 2-11] AOP가 적용되지 않는 JDBC 트랜잭션 예
[코드 2-11]은 트랜잭션 기능에 대해 AOP가 적용되지 않은 예제 코드입니다.
잠시 코드를 확인하기 전에 트랜잭션이라는 개념을 살펴보겠습니다.

트랜잭션(Transaction)이란 ‘데이터를 처리하는 하나의 작업 단위’를 의미합니다. 예를 들어 데이터베이스에 A 데이터와 B 데이터를 두 번에 걸쳐 각각 insert 하는 작업을 하나의 트랜잭션으로 묶는다면 A 데이터와 B 데이터는 모두 데이터베이스에 저장되던가 아니면 둘 중에 하나라도 오류로 인해 저장되지 않는다면 A, B 데이터는 모두 데이터베이스에 반영되지 않아야 합니다(All or Nothing).
이러한 처리를 위해 일반적으로 트랜잭션에는 커밋(commit) 또는 롤백(rollback)이라는 기능이 있습니다.
커밋은 모든 작업이 성공적으로 수행되었을 경우 수행한 작업을 데이터베이스에 반영하는 것이고, 롤백은 작업이 하나라도 실패한다면 이전에 성공한 작업들을 작업 수행 이전 상태로 되돌리는 것을 말합니다.
그리고 코드 2-11에서는 Java의 JDBC API를 사용했는데 여러분들이 로우 레벨의 JDBC API를 사용할 일은 없지만 AOP를 설명하기에는 적절한 예시이므로 API 기능 자체를 이해하려 하지 말고 단순히 코드의 흐름만 이해하길 바랍니다.
[코드 2-11]의 registerMember() 메서드는 커피 주문 애플리케이션을 사용할 회원 정보를 등록하는 기능을 합니다.
registerMember() 메서드 내에서 실제로 비즈니스 로직을 수행하는 코드는 회원 정보를 저장하는 (2)의 saveMember()와 회원의 포인트 정보를 저장하는savePoint()입니다.
이외에 (1)의 connection.setAutoCommit(false)이나 (3)의 connection.commit(), (4)의 connection.rollback()은 saveMember()와 savePoint() 작업을 트랜잭션으로 묶어서 처리하기 위한 기능들입니다.
문제는 이렇게 트랜잭션 처리를 하는 코드들이 애플리케이션의 다른 기능에도 중복되어 나타날 것이라는 겁니다.
서버 애플리케이션은 데이터베이스에 데이터를 저장하는 기능 없이 구성되는 것은 사실상 불가능하다고 보면 됩니다.
이처럼 애플리케이션 전반에 걸쳐서 트랜잭션 관련한 중복된 코드가 수도 없이 나타난다면 여러분들은 어떻게 해야 할까요?
맞습니다. 중복된 코드를 공통화해서 재사용 가능하도록 만들어야 합니다. 그리고 이 공통화 작업은 AOP를 통해서 할 수 있습니다.
그런데 Spring에서는 이미 이런 트랜잭션 처리 기능을 AOP를 통해서 공통화해두었습니다.
@Component
@Transactional // (1)
public class Example2_12 {
private Connection connection;
public void registerMember(Member member, Point point) throws SQLException {
saveMember(member);
savePoint(point);
}
private void saveMember(Member member) throws SQLException {
// Spring JDBC를 이용한 회원 정보 저장
}
private void savePoint(Point point) throws SQLException {
// Spring JDBC를 이용한 포인트 정보 저장
}
}[코드 2-12] Spring AOP 기능이 적용된 JDBC 트랜잭션 예
[코드 2-12]는 Spring의 AOP 기능을 사용하여 registerMember()에 트랜잭션을 적용한 예제 코드입니다.
[코드 2-12]에는 트랜잭션 처리를 위한 코드들이 모두 사라지고 순수하게 비즈니스 로직을 처리하기 위한 saveMember(member)와 savePoint(point)만 남은 것을 볼 수 있습니다.
그렇다면 트랜잭션 처리는 어떻게 하는 걸까요?
바로 (1)의 @Transactional 애노테이션 하나만 붙이면 Spring 내부에서 이 애노테이션 정보를 활용해서 AOP 기능을 통해 트랜잭션을 적용합니다.
이처럼 AOP를 활용하면 애플리케이션에 전반에 걸쳐 적용되는 공통 기능(트랜잭션, 로깅, 보안, 트레이싱, 모니터링) 등을 비즈니스 로직에서 깔끔하게 분리하여 재사용 가능한 모듈로 사용할 수 있습니다.
핵심 포인트
- AOP(Aspect Oriented Programming)는 관심 지향 프로그래밍이다.
- AOP에서 의미하는 Aspect는 애플리케이션의 공통 관심사를 의미한다.
- 애플리케이션의 공통 관심사는 비즈니스 로직을 제외한 애플리케이션 전반에 걸쳐서 사용되는 공통 기능들을 의미한다.
- 애플리케이션 전반에 걸쳐서 사용되는 공통 기능에는 로깅, 보안, 트랜잭션, 모니터링, 트레이싱 등의 기능이 있다.
- AOP를 애플리케이션에 적용해서 다음과 같은 이점을 누릴 수 있다.
- 코드의 간결성 유지
- 객체 지향 설계 원칙에 맞는 코드 구현
- 코드의 재사용
심화 학습
- 이번 챕터에서 이야기한 애플리케이션의 공통 기능 이외에 AOP로 적용할만한 공통 기능에는 뭐가 있을지 생각해 보세요.
- 구글링을 해보셔도 됩니다. 가벼운 마음으로 찾아보길 바랍니다.
PSA(Portable Service Abstraction)
이번 시간에는 Spring Framework의 3대 핵심 개념 중 하나인 PSA에 대해서 살펴보도록 하겠습니다.

[그림 2-13] Spring 삼각형 - PSA 설명
PSA(Portable Service Abstraction)란?
추상화(Abstraction)의 개념
IT를 전공하는 사람이든 그렇지 않은 사람이든 중학교 미술 교과 과정에서 꼭 접하게 되는 예술가 중 한 명이 바로 피카소입니다.
피카소는 여러분들이 알고 있다시피 추상화의 대가입니다. 어렸을 때 피카소의 그림을 보면서 ‘와.. 이 그림 정말 특이하다.. 그림이 정말 난해해..’라고 생각했었던 기억이 나네요!
객체지향 프로그래밍 세계에서 추상화(Abstraction)의 의미는 피카소가 그린 추상화 그림의 의미와 별반 다르지 않습니다.

피카소 작품 ‘the bull’: https://www.businessinsider.com/why-apple-employees-learn-design-from-pablo-picasso-2014-8
그림을 보시면, 왼쪽에서 오른쪽으로 갈수록 황소의 모습이 단순화되어 가는 것을 볼 수 있습니다.
첫 번째 황소의 구체적인 모습을 보지 않았다고 가정하더라도 황소까지는 아니지만 소의 형상과 비슷하다는 생각을 할 수 있을 거라고 생각합니다.
결론적으로 황소의 특성을 잘 살린 황소의 본질만을 남기려고 했음을 추측할 수 있습니다.
피카소의 그림처럼 객체지향 프로그래밍 세계에서는 어떤 클래스의 본질적인 특성만을 추출해서 일반화하는 것을 바로 추상화(Abstraction)라고 합니다.
어떤 용어든 간에 추상화의 의미를 이해하는데 더 적합한 언어를 사용하면 되겠지만 추상화보다는 일반화라는 표현이 설계 관점에서 더 적절한 표현인 것 같습니다.
객체지향 프로그래밍 언어인 Java에서 코드로 추상화를 표현할 수 있는 대표적인 방법이 바로 추상 클래스와 인터페이스입니다.
추상화의 예
예를 들어, 미취학 아동을 관리하는 애플리케이션을 설계하면서 아이 클래스를 일반화(추상화) 한다라고 가정해 봅시다.
먼저 미취학 아동을 관리하기 위해 필요한 아이의 일반적인 특징에는 뭐가 있는지 한번 살펴보겠습니다.
Java의 클래스는 속성을 나타내는 멤버 변수와 동작을 나타내는 메서드로 구성되므로, 아기의 속성과 동작을 일반화해서 멤버 변수와 메서드로 표현해 보도록 하겠습니다.
먼저 아이를 관리하는 관점에서 아이의 일반적인 속성으로는 이름, 키, 몸무게, 혈액형, 나이 등이 있을 것 같습니다.
그리고 일반적으로 아이가 할 수 있는 동작으로는 웃다, 울다, 자다, 먹다 등이 있을 테고요.
이렇게 추출해 본 일반적인 아기의 특징을 클래스로 작성해 보면 [코드 2-13]과 같을 것입니다.
public abstract class Child {
protected String childType;
protected double height;
protected double weight;
protected String bloodType;
protected int age;
protected abstract void smile();
protected abstract void cry();
protected abstract void sleep();
protected abstract void eat();
}[코드 2-13] 아이의 특징을 일반화 한 예
[코드 2-13]은 미취학 아동을 관리하기 위한 관점에서 아이의 일반적인 특징을 추상 클래스로 작성했습니다.
추상화를 하는 이유
그렇다면 추상화는 왜 하는 걸까요?
[코드 2-13]을 확장하는 예제 코드를 통해서 추상화가 필요한 이유를 설명하도록 하겠습니다.
// NewBornBaby.java(신생아)
public class NewBornBaby extends Child {
@Override
protected void smile() {
System.out.println("신생아는 가끔 웃어요");
}
@Override
protected void cry() {
System.out.println("신생아는 자주 울어요");
}
@Override
protected void sleep() {
System.out.println("신생아는 거의 하루 종일 자요");
}
@Override
protected void eat() {
System.out.println("신생아는 분유만 먹어요");
}
}
// Infant.java(2개월 ~ 1살)
public class Infant extends Child {
@Override
protected void smile() {
System.out.println("영아는 많이 웃어요");
}
@Override
protected void cry() {
System.out.println("영아는 종종 울어요");
}
@Override
protected void sleep() {
System.out.println("영아부터는 밤에 잠을 자기 시작해요");
}
@Override
protected void eat() {
System.out.println("영아부터는 이유식을 시작해요");
}
}
// Toddler.java(1살 ~ 4살)
public class Toddler extends Child {
@Override
protected void smile() {
System.out.println("유아는 웃길 때 웃어요");
}
@Override
protected void cry() {
System.out.println("유아는 화가나면 울어요");
}
@Override
protected void sleep() {
System.out.println("유아는 낮잠을 건너뛰고 밤잠만 자요");
}
@Override
protected void eat() {
System.out.println("유아는 딱딱한 걸 먹기 시작해요");
}
}[코드 2-14] Child의 하위 클래스 예
[코드 2-14]는 Child 클래스를 확장한 하위 클래스의 예입니다.
추상 클래스를 통해서 아이의 일반적인 특징을 Child 클래스로 작성했다면 코드 2-14의 클래스들은 Child 클래스의 일반화된 동작을 자신만의 고유한 동작으로 재구성하고 있습니다.
그렇다면 해당 연령에 맞는 NewBornBaby, Infant, Toddler 클래스를 사용하기 위해서 어떤 방식으로 접근하면 될까요?
public class ChildManageApplication {
public static void main(String[] args) {
Child newBornBaby = new NewBornBaby(); // (1)
Child infant = new Infant(); // (2)
Child toddler = new Toddler(); // (3)
newBornBaby.sleep();
infant.sleep();
toddler.sleep();
}
}
실행 결과
=========================================
신생아는 거의 하루 종일 자요
영아부터는 밤에 잠을 자기 시작해요
유아는 낮잠을 건너뛰고 밤잠만 자요[코드 2-15] 상위 클래스에 정의된 일반화된 특징을 하위 클래스의 특징에 맞게 사용하는 예
[코드 2-15]에서는 Child라는 상위 클래스에 일반화시켜 놓은 아이의 동작을 NewBornBaby, Infant, Toddler라는 클래스로 연령별 아이의 동작으로 구체화시켜서 사용을 하고 있습니다.
여기서 중요한 것은 클라이언트(여기서는 ChildManageApplication 클래스의 main() 메서드)는 NewBornBaby, Infant, Toddler를 사용할 때 구체화 클래스의 객체를 자신의 타입에 할당하지 않고, (1) ~ (3)과 같이 Child 클래스 변수에 할당을 해서 접근을 합니다.
이렇게 되면 클라이언트 입장에서는 Child라는 추상 클래스만 일관되게 바라보며 하위 클래스의 기능을 사용할 수 있습니다.
이처럼 클라이언트가 추상화된 상위 클래스를 일관되게 바라보며 하위 클래스의 기능을 사용하는 것이 바로 일관된 서비스 추상화(PSA)의 기본 개념입니다.
일반적으로 서버 / 클라이언트 측면에서는 서버 측 기능을 이용하는 쪽을 클라이언트라고 합니다. 우리가 알고 있는 대표적인 클라이언트는 바로 웹 브라우저입니다.
그런데 코드 레벨에서 어떤 클래스의 기능을 사용하는 측 역시 클라이언트라고 부른다는 사실을 기억하길 바랍니다.
서비스에 적용하는 일관된 서비스 추상화 (PSA) 기법
서비스 추상화란 위와 같은 추상화의 개념을 애플리케이션에서 사용하는 서비스에 적용하는 기법입니다.

[그림 2-14] 서비스 추상화 클래스 다이어그램 예시
[그림 2-14]는 Java 콘솔 애플리케이션에서 클라이언트가 데이터베이스에 연결하기 위해 JdbcConnector를 사용하기 위한 서비스 추상화의 예입니다.
즉, JdbcConnector가 애플리케이션에서 이용하는 하나의 서비스가 되는 것입니다.
Java에서 특정 데이터베이스에 연결하기 위해서는 해당 데이터베이스의 JDBC 구현체로부터 Connection을 얻어야 하는데 [그림 2-14]는 이 동작을 재현해보기 위한 클래스 다이어그램이라고 생각하면 되겠습니다.
[그림 2-14]에서 DbClient는 OracleJdbcConnector, MariaDBJdbcConnector, SQLiteJdbcConnector 같은 JdbcConnector 인터페이스의 구현체에 직접적으로 연결해서 Connection을 얻는 것이 아니라 JdbcConnector 인터페이스를 통해 간접적으로 연결되어(느슨한 결합) Connection 객체를 얻는 것을 볼 수 있습니다.
그런데 DbClient에서 어떤 JdbcConnector 구현체를 사용하더라도 Connection을 얻는 방식은 getConnection() 메서드를 사용해야 하기 때문에 동일합니다.
즉, 일관된 방식으로 해당 서비스의 기능을 사용할 수 있다는 의미입니다.
이처럼 애플리케이션에서 특정 서비스를 이용할 때, 서비스의 기능을 접근하는 방식 자체를 일관되게 유지하면서 기술 자체를 유연하게 사용할 수 있도록 하는 것을 PSA(일관된 서비스 추상화)라고 합니다.
// DbClient.java
public class DbClient {
public static void main(String[] args) {
// Spring DI로 대체 가능
JdbcConnector connector = new SQLiteJdbcConnector(); // (1)
// Spring DI로 대체 가능
DataProcessor processor = new DataProcessor(connector); // (2)
processor.insert();
}
}
// DataProcessor.java
public class DataProcessor {
private Connection connection;
public DataProcessor(JdbcConnector connector) {
this.connection = connector.getConnection();
}
public void insert() {
// 실제로는 connection 객체를 이용해서 데이터를 insert 할 수 있다.
System.out.println("inserted data");
}
}
// JdbcConnector.java
public interface JdbcConnector {
Connection getConnection();
}
// MariaDBJdbcConnector.java
public class MariaDBJdbcConnector implements JdbcConnector {
@Override
public Connection getConnection() {
return null;
}
}
// OracleJdbcConnector.java
public class OracleJdbcConnector implements JdbcConnector {
@Override
public Connection getConnection() {
return null;
}
}
// SQLiteJdbcConnector.java
public class SQLiteJdbcConnector implements JdbcConnector {
@Override
public Connection getConnection() {
return null;
}
}[코드 2-16] JdbcConnector 서비스를 사용하기 위한 PSA 예제 코드
[코드 2-16]은 [그림 2-14]의 클래스 다이어그램을 기반으로 JdbcConnector 서비스를 사용하는 예제 코드인데, 편의상 6개의 .java 파일을 하나로 표시했습니다.
DbClient 클래스의 (1)에서 SQLiteJdbcConnector 구현체의 객체를 생성해서 JdbcConnector 인터페이스 타입의 변수에 할당(업캐스팅)하고 있는 것을 볼 수 있습니다.
그리고 (2)에서 실제로 데이터를 데이터베이스에 저장하는 기능을 하는 DataProcessor 클래스의 생성자로 JdbcConnector 객체를 전달하고 있습니다(의존성 주입).
만약에 다른 애플리케이션에서 SQLite 데이터베이스를 사용하는 것이 아니라 Oracle 데이터베이스를 사용해야 한다면, JdbcConnector 서비스 모듈을 그대로 가져와서 (1)의 new SQLiteJdbcConnector()를 new OracleJdbcConnector()로 바꿔서 사용하면 될 것입니다.
[코드 2-16]은 PSA의 개념을 이해하기 위한 용도로 작성된 것이지 실제 Java에서 JDBC를 이용하는 API 사용법이 코드 2-16과 동일하지 않습니다.
우리가 앞으로 Spring 기술을 사용하면서 내부적으로 JDBC 기술을 이용하긴 하지만 Java JDBC 기술을 로우 레벨에서 사용하는 일은 없을 테니 개념 이해 수준에서 넘어가면 되겠습니다.
PSA가 필요한 이유

PSA가 필요한 주된 이유는 어떤 서비스를 이용하기 위한 접근 방식을 일관된 방식으로 유지함으로써 애플리케이션에서 사용하는 기술이 변경되더라도 최소한의 변경만으로 변경된 요구 사항을 반영하기 위함입니다.
즉, PSA를 통해서 애플리케이션의 요구 사항 변경에 유연하게 대처할 수 있습니다.
Spring은 상황에 따라 기술이 바뀌더라도 변경된 기술에 일관된 방식으로 접근할 수 있는 PSA를 적극적으로 지원하고 있습니다.
Spring에서 PSA가 적용된 분야로는 트랜잭션 서비스, 메일 서비스, Spring Data 서비스 등이 있습니다.
여러분들이 당장에 직접적으로 PSA를 이용해 어떤 서비스를 구현할 일은 없을 거라 생각합니다. 하지만 PSA의 기본 개념을 이해함으로써 Spring이 지원하는 기술을 적절하게 사용할 수 있고, 필요하다면 미래에 PSA를 통한 서비스를 직접 개발할 수 있는 원동력이 될 것이라고 생각합니다.
핵심 포인트
- 객체지향 프로그래밍 세계에서 어떤 클래스의 본질적인 특성만을 추출해서 일반화하는 것을 추상화(Abstraction)라고 한다.
- 클라이언트가 추상화된 상위 클래스를 일관되게 바라보며 하위 클래스의 기능을 사용하는 것이 바로 일관된 서비스 추상화(PSA)의 기본 개념이다.
- 애플리케이션에서 특정 서비스를 이용할 때, 서비스의 기능을 접근하는 방식 자체를 일관되게 유지하면서 기술 자체를 유연하게 사용할 수 있도록 하는 것을 PSA(일관된 서비스 추상화)라고 한다.
- PSA가 필요한 주된 이유는 어떤 서비스를 이용하기 위한 접근 방식을 일관된 방식으로 유지함으로써 애플리케이션에서 사용하는 기술이 변경되더라도 최소한의 변경만으로 변경된 요구 사항을 반영하기 위함이다.
심화 학습
- [코드 2-13], [코드 2-14], [코드 2-15]를 활용한 학습
- [코드 2-13], [코드 2-14], [코드 2-15]에 작성된 클래스들을 IDE를 통해 직접 작성하고 실행해 보세요.
- 작성 순서는 다음과 같습니다.
- ‘src/main/com/springboot/chapter2’ 경로에 ‘psa’ Package를 생성합니다.
- 코드에 나온 각각의 클래스명으로 클래스를 생성한 후, 코드를 작성합니다.
- main() 메서드가 있는 ChildManageApplication 클래스를 실행합니다.
- 출력 결과를 확인합니다.
- IntelliJ 상단 메뉴에서 [Help] > [Edit Custom VM Options]를 클릭합니다.
- ‘idea64.exe.vmoptions’ 파일이 오픈되면 마지막 라인에 아래 설정을 입력합니다. -Dfile.encoding=UTF-8
- IntelliJ를 끄고, 다시 실행합니다.
- 한글이 잘 출력되는지 확인합니다.
- 작성 순서는 다음과 같습니다.
- [코드 2-13]의 Child 추상 클래스에 추가할 수 있는 아이의 일반적인 속성이나 동작에는 무엇이 있을지 생각해 보세요. (생각이나 사고에 정답은 없습니다. 서로의 의견을 주고받으면서 더 나은 방법을 찾아가면 되는 것입니다.)
- [코드 2-13], [코드 2-14], [코드 2-15]에 작성된 클래스들을 IDE를 통해 직접 작성하고 실행해 보세요.
Spring Framework 모듈 구성
이번 시간에는 소프트웨어 개발 시, 자주 사용하는 용어인 아키텍처(Architecture)가 무엇인지 살펴보고, Spring Framework의 아키텍처를 통해 Spring Framework에 지원하는 여러 가지 기능을 포함하고 있는 Spring 모듈에 대해서 살펴보도록 하겠습니다.
여러분들이 아직 Spring의 사용법은 배우지 않았기 때문에 이번 챕터의 내용을 진지하게 받아들일 필요는 없습니다.
다만, 이번 챕터를 통해 애플리케이션을 설계할 때 필요한 아키텍처가 무엇인지 그 의미를 이해하고, 애플리케이션을 개발하기 위해 애플리케이션의 아키텍처를 어떻게 그릴 것인지 이번 시간을 통해서 고민해 보는 시간을 가져보길 바랍니다.
학습 목표
- 아키텍처(Architecture)의 의미를 이해할 수 있다.
- 우리가 알아야 할 애플리케이션의 아키텍처를 이해할 수 있다.
- 아키텍처를 통해 Spring Framework의 모듈(Module) 구성을 이해할 수 있다.
아키텍처(Architecture)란?
아키텍처(Architecture)는 건축 분야에서 유래된 용어로써 요구 사항을 만족하는 건축물을 짓는 데 있어 청사진 같은 역할을 합니다.
과거 중세 시대에는 특정 지배 계층들이 원하는 의도나 요구 사항에 맞는 구조물을 만들기 위해서 해당 구조물의 콘셉트(Conecpt)를 먼저 정의한 후, 이 콘셉트를 기반으로 구조물을 만들어내기 시작했습니다.
아키텍처의 정의가 어렵게 느껴지신다면 아파트나 빌딩 같은 건축물의 조감도를 생각하시면 이해가 빠를 거라 생각합니다.

[그림 2-15] 건축물 조감도 예
[그림 2-15]는 어느 건물의 수영장을 위에서 바라본 조감도입니다.
해당 수영장을 짓기 위해서는 여러 이해 당사자들이 만나서 논의를 할 것입니다. 여기서 말하는 이해 당사자에는 이 수영장의 주인이 될 고객과 수영장을 설계하는 건축가(Architect), 설계를 토대로 수영장을 만드는 시공사 등이 있을 것입니다.
이처럼 아키텍처는 이해 당사자들을 위한 어떤 건물이나 구조물에 대한 콘셉트을 잡는 것으로부터 시작한다고 보면 되겠습니다.
대략적인 콘셉트을 잡았다면 이 콘셉트를 출발점으로 해서 구체적인 설계와 시공에 들어가게 되는 것입니다.
이처럼 컴퓨터 시스템에서의 아키텍처 역시 어떠한 시스템을 구축하는 데 있어 해당 시스템의 비즈니스적 요구 사항을 만족하는 전체 시스템 구조를 정의하는 것이며, 이해 당사자들이 전체 시스템 구조를 이해하는데 무리가 없도록 일반적으로 이미지나 도형 등을 많이 사용합니다.
아키텍처의 범위를 어디까지로 할 것이냐에 대해서는 의견이 분분하지만 아키텍처는 우선 너무 복잡하면 안 됩니다.
물론 아주 거대하고 방대한 시스템이라면 어쩔 수 없이 어느 정도의 복잡함이 아키텍처 내에 표현될 수밖에 없겠지만 기본적으로 최대한 심플함을 유지하기 위해 노력하는 것이 좋습니다.
컴퓨터 시스템에서 아키텍처 유형
시스템 아키텍처
시스템 아키텍처는 하드웨어와 소프트웨어를 모두 포함하는 어떤 시스템의 전체적인 구성을 큰 그림으로 표현한 것입니다.
시스템 아키텍처를 통해 기본적으로 해당 시스템이 어떤 하드웨어로 구성되고, 어떤 소프트웨어를 사용하는지를 대략적으로 알 수 있습니다.
또한 해당 시스템 구성 요소들 간의 상호작용이 어떻게 이루어지는지 등 시스템이 정상적으로 동작하기 위한 동작 원리 등이 시스템 아키텍처 안에 표현이 되면 이해 당사자들이 해당 아키텍처를 이해하는데 도움이 됩니다.
시스템 아키텍처 사례
시스템 아키텍처를 어떤 식으로 표현하는지 그리고 아키텍처를 점진적으로 개선해 나가는 모습을 사례를 통해서 알아보도록 합시다.
아키텍처 사례에 나오는 기술들을 몰라도 상관없습니다.
중요한 것은 이런 식으로 시스템 아키텍처를 그릴 수 있으며, 이해 당사자들 간에 논의를 거치면서 아키텍처를 점진적으로 개선해 나갈 수 있다는 사실만 이해하면서 편하게 읽으면 될 것 같습니다.
여러분들이 주니어 개발자로서 어느 기업에 입사를 하게 된다 하더라도 당장 시스템 아키텍처를 그리라고 하는 사람들은 아무도 없을 것입니다.
하지만 실무를 경험하면서 또는 개인적인 프로젝트를 진행해보면서 시스템 아키텍처를 그려보는 연습을 하게 된다면 개발자로서 한층 성장한 여러분들의 모습을 확인할 수 있을 거라고 생각합니다.

[그림 2-16] 채팅 서버 시스템 아키텍처 예
[그림 2-16]는 채팅 서버를 구축하기 위한 전통적인 시스템 아키텍처라고 할 수 있습니다.
채팅 사용자가 많지 않다면 [그림 2-16]와 같은 아키텍처만으로 해당 시스템을 이해하는데 큰 무리가 없습니다.
하지만 사용자가 많아진다면 [그림 2-16]와 같은 아키텍처에는 문제가 발생합니다.
우선 사용자의 요청을 단일 서버가 모두 처리하기 때문에 제한적인 사용자 요청만 처리할 수 있습니다. 즉, 사용자의 요청이 늘어나는 상황에 대비하기 위한 시스템 확장에 대한 부분이 전혀 고려되지 않았습니다.
그리고 웹소켓 서버가 단일 서버이기 때문에 해당 서버가 다운되면 시스템 전체가 죽게 되는 문제가 있습니다.

[그림 2-17] 채팅 서버 시스템 아키텍처
[그림 2-17]은 [그림 2-16]의 채팅 서버 아키텍처를 개선한 아키텍처 모습입니다.
[그림 2-17]에서 개선된 점은 다음과 같습니다.
- 아키텍처 사용자의 요청을 분산시켜 주는 로드 밸런서 영역을 두어서 웹소켓 서버를 안정적으로 운영할 수 있도록 하고 있습니다.
- 여러 대의 웹소켓 서버로 확장이 가능하기 때문에 사용자의 요청이 늘어나더라도 서버의 부하를 줄일 수 있으며, 특정 서버에 장애가 발생하더라도 전체 시스템이 죽는 경우를 방지할 수 있습니다.
- 메시지 브로커 영역을 두어서 웹소켓 서버가 다중 서버로 구성이 되어 있더라도 특정 사용자들 간에 메시지를 주고받을 수 있는 공유 채널을 사용하는 것이 가능해집니다.

[그림 2-18] 채팅 서버 시스템 아키텍처 예
[그림 2-18]은 채팅 서버의 전송 속도를 향상하는 것을 목적으로 한번 더 제안된 아키텍처입니다.
[그림 2-17]의 아키텍처와 어떤 부분이 다른지 확인해 볼까요?
- 사용자의 요청과 서버의 응답이 이루어지는 전체 영역에 걸쳐서 Blocking 되는 요소가 없도록 리액티브 시스템을 구성하여 클라이언트의 요청을 보다 빠르게 처리할 수 있습니다.
- 웹소켓이 하나의 Connection과 연결되는 것에 반해 RSocket은 하나의 Connection 내에서 다중 요청 처리가 가능하기 때문에 대량의 요청을 안정적으로 처리할 수 있습니다.
시스템 아키텍처의 사례를 살펴본 여러분들의 느낌은 어떨지 궁금합니다.
다시 한번 당부하지만, 위 사례를 보면서 '시스템 아키텍처는 저런 식으로 그릴 수 있구나' 정도로만 생각하길 바랍니다.
다만, 여러분들이 프로젝트를 시작할 때에는 프로젝트에서 만들게 될 시스템에 대한 아키텍처를 위 사례들처럼 스스로 그릴 수 있어야 합니다.
소프트웨어 아키텍처 / 애플리케이션 아키텍처
소프트웨어 아키텍처 / 애플리케이션 아키텍처 의미
소프트웨어는 하드웨어를 제외한 컴퓨터 내의 모든 프로그램을 포괄하는 의미를 가지고 있으며 이러한 소프트웨어의 구성을 큰 그림으로 표현한 것이 소프트웨어 아키텍처입니다.
소프트웨어 아키텍처 사례의 대표적인 것이 바로 Java 플랫폼 아키텍처입니다.
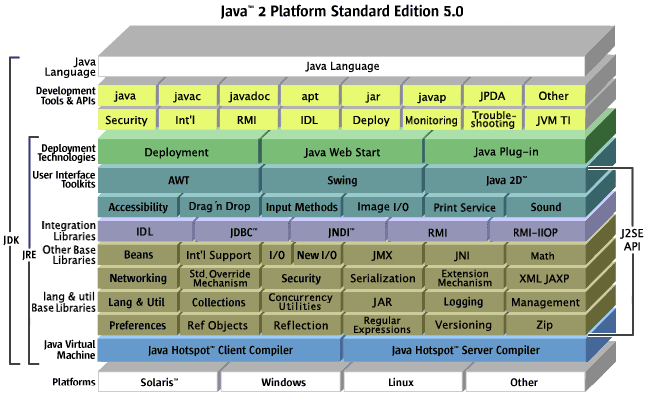
[그림 2-19] Java SE 아키텍처 예(출처:https://docs.oracle.com/javase/1.5.0/docs/index.html)
[그림 2-19]은 Java를 포함한 Java 플랫폼에 대한 아키텍처를 마치 벽돌을 쌓은 듯한 모습으로 표현한 아키텍처입니다.
이 아키텍처를 통해서 우리는 Java가 어떤 기술들을 지원하고 Java를 통해서 어떤 기능들을 사용할 수 있는지 등을 큰 그림으로 접근할 수 있습니다.
우리가 알아야 할 애플리케이션 아키텍처
그런데 우리가 주목해야 할 부분은 웹 상에서 동작하는 웹 애플리케이션을 위한 아키텍처입니다.
애플리케이션은 소프트웨어 종류의 하나로써 좁게는 데스크톱이나 스마트폰에서 사용하는 응용 프로그램을 말하며, 넓게는 클라이언트의 요청을 처리하는 서버 애플리케이션을 의미합니다.
애플리케이션의 아키텍처 유형에는 다양한 유형이 있지만 우리가 앞으로 만들게 될 웹 애플리케이션과 연관이 있는 계층형 아키텍처(N-티어)에 대해서 간단히 살펴보도록 하겠습니다.

[그림 2-20] 계층형 웹 애플리케이션 아키텍처
[그림 2-20]은 우리가 앞으로 학습하게 될 웹 애플리케이션을 계층형으로 표현한 아키텍처입니다.
- API 계층(API Layer)
API 계층은 클라이언트의 요청을 받아들이는 계층입니다. 일반적으로 표현 계층(Presentation Layer)라고도 불리지만 REST API를 제공하는 애플리케이션의 경우 API 계층이라고 표현합니다.
우리가 학습하고 만들게 될 애플리케이션이 REST API 요청을 처리하는 애플리케이션이 될 것이므로 API 계층이라는 표현이 더 적절합니다.
- 서비스 계층(Service Layer)
서비스 계층은 API 계층에서 전달받은 요청을 업무 도메인의 요구 사항에 맞게 비즈니스적으로 처리하는 계층입니다.
애플리케이션의 핵심 로직은 서비스 계층에 포함되어 있다고 해도 과언이 아닐 만큼 애플리케이션에 있어 핵심이 되는 계층입니다.
도메인(Domain)이란? 애플리케이션 개발에서 흔하게 사용하는 도메인이란 용어는 주로 비즈니스적인 어떤 업무 영역과 관련이 있습니다.
예를 들어, 여러분들이 새로운 배달 주문 앱을 만들어야 한다면 고객과 음식점, 배달원, 그리고 카드사 또는 은행 등 배달 주문 앱을 구현하기 위해 필요한 업무들을 자세히 알면 알수록 퀄리티가 높은 애플리케이션을 만들 가능성이 높습니다.
즉, 고객이 음식을 주문하는 과정, 주문받은 음식을 처리하는 과정, 조리된 음식을 배달하는 과정 등의 도메인 지식(Domain Knowledge)들을 서비스 계층에서 비즈니스 로직으로 구현해야하는 것입니다.
애플리케이션을 제작하기 위한 기술도 중요하지만 애플리케이션에서 비즈니스 로직으로 표현해야 하는 도메인 지식 역시 아주 중요하다는 사실을 기억하기 바랍니다.
- 데이터 액세스 계층(Data Access Layer)
데이터 액세스 계층은 비즈니스 계층에서 처리된 데이터를 데이터베이스 등의 데이터 저장소에 저장하기 위한 계층입니다.
핵심 포인트
- 아키텍처(Architecture)는 건축 분야에서 유래된 용어로써 요구 사항을 만족하는 건축물을 짓는 데 있어 청사진 같은 역할을 한다.
- 소프트웨어의 구성을 큰 그림으로 표현한 것이 소프트웨어 아키텍처이다.
- 애플리케이션은 소프트웨어 종류의 하나로서 좁게는 데스크톱이나 스마트폰에서 사용하는 응용 프로그램을 말하며, 넓게는 클라이언트의 요청을 처리하는 서버 애플리케이션을 의미한다.
- 우리가 중점적으로 알아야 할 아키텍처는 웹 상에서 동작하는 웹 애플리케이션을 위한 아키텍처이다.
- 애플리케이션의 아키텍처 중에서 우리가 중점적으로 알아야 할 아키텍처는 계층형 애플리케이션 아키텍처이다.
- REST API 기반 웹 애플리케이션의 계층은 크게 API 계층(API Layer), 비즈니스 계층(Business Layer), 데이터 액세스 계층(Data Access Layer)으로 구분된다.
- API 계층은 클라이언트의 요청을 받아들이는 계층이다.
- 비즈니스 계층은 API 계층에서 전달받은 요청을 업무 도메인의 요구 사항에 맞게 비즈니스적으로 처리하는 계층이다.
- 데이터 액세스 계층은 비즈니스 계층에서 처리된 데이터를 데이터베이스 등의 데이터 저장소에 저장하기 위한 계층이다.
심화 학습
- 이번 챕터에서 언급하지 않은 소프트웨어 아키텍처 유형에는 어떤 것이 있는지 구글에서 검색해 보세요.
아키텍처로 보는 Spring Framwork 모듈(Module) 구성
우리가 앞으로 배우게 될 Spring Framework을 아키텍처 관점으로 바라보면서 Spring에서 어떤 기능들을 제공하는지 살펴보고, Spring에 대한 큰 그림을 생각해 보도록 합시다.

[그림 2-18] Spring Framework 모듈 아키텍처 (출처:https://docs.spring.io/spring-framework/docs/5.0.0.M5/spring-framework-reference/html/overview.html)
[그림 2-18]은 Spring Framework에서 지원하는 모듈들을 아키텍처로 표현한 그림입니다.
Spring Framework에서는 약 20여 개의 모듈을 통해 다양한 기능들을 제공하는데, 우리가 앞에서 언급했었던 AOP, Aspect, Servlet, Web 같은 용어들 역시 아키텍처에서 확인할 수 있습니다.
모듈(Module)이란? Java에서는 일반적으로, 지원되는 여러 가지 기능들을 목적에 맞게 그룹화하여 묶어 놓은 것을 모듈이라고 부릅니다.
이러한 모듈들은 Java의 패키지 단위로 묶여 있으며, 이 패키지 안에는 관련 기능을 제공하기 위한 클래스들이 포함되어 있습니다.
일반적으로 모듈은 재사용 가능하도록 라이브러리 형태로 제공되는 경우가 많습니다.
또한 우리가 앞으로 학습하게 될 내용들이 [그림 2-18]에 대부분 포함이 되어 있다는 사실 역시 기억을 해두시면 좋을 것 같습니다.
지금은 [그림 2-18]의 아키텍처가 눈에 들어오지 않을 수도 있지만 Spring에 대한 학습이 어느 정도 진행되고 난 이후에 이 아키텍처를 다시 보게 되면 놀랍도록 친숙해지는 느낌을 받을 거라 생각합니다.
핵심 포인트
- Spring Framework의 모듈 아키텍처를 통해 Spring이 어떤 기능들을 지원하는지 알 수 있다.
필수 학습
- [그림 2-18]에 나와 있는 각각의 기술 스택 들은 어디에 쓰이는 기술인지 대략적으로 살펴보세요.
- 관련 링크: https://docs.spring.io/spring-framework/docs/5.0.0.M5/spring-framework-reference/html/overview.html
- 영문으로 쓰여있어서 읽기 힘들다면 해당 기술 스택에 대해 구글에서 검색해 보고 대략적인 의미를 파악해보기 바랍니다.
- 기술 문서를 읽는 것도 개발자들이 해야 되는 주요 업무 중에 하나라는 사실도 기억해 두면 좋을 것 같습니다.
- 관련 링크: https://docs.spring.io/spring-framework/docs/5.0.0.M5/spring-framework-reference/html/overview.html
Spring Boot 소개
이번 챕터에서는 Spring Boot에 대해서 간략하게 살펴보도록 하겠습니다.
앞으로 학습하게 될 Spring 관련 기술들은 모두 Spring Boot 기반 하에서 배우게 될 것입니다.
Spring Boot이 무엇이고, 왜 Spring Boot을 사용하여야 하는지 이번 챕터를 통해서 이해하는 시간을 가져보도록 하겠습니다.
학습 목표
- Spring Boot이란 무엇인지 이해할 수 있다.
- Spring Boot을 사용해야 하는 이유를 알 수 있다.
- Spring Boot의 핵심 콘셉트가 무엇인지 이해할 수 있다.
Spring Boot이란?
[Spring Framework을 배워야 하는 이유] 챕터에서 Spring Boot을 사용할 경우, Spring의 설정이 얼마나 간결해지는지 확인을 했습니다.
그렇다면 Spring Boot은 무엇일까요?
Spring Framework은 엔터프라이즈 애플리케이션을 개발하기 위한 핵심 기능을 제공하는 Spring Project 중 하나입니다.
그리고 Spring Boot은 Spring Framework의 편리함에도 불구하고 Spring 설정의 복잡함으로 인해 Spring 기반 애플리케이션 개발을 시작하기도 전에 어려움을 겪는 문제점을 해결하기 위해 생겨난 Spring Project 중 하나입니다.
우리가 앞으로 학습하게 될 모든 강의 역시 Spring Boot을 기반으로 진행하게 됩니다. 따라서 기존에 Spring Boot을 사용하지 않았을 때의 어려움을 겪지 않아도 되고, 손쉽게 그리고 빠르게 여러분이 원하는 애플리케이션 제작을 할 수 있을 거라고 생각합니다.
Spring Boot에 대한 이론적인 내용들은 사실 애플리케이션 개발을 진행해본 적이 없는 분들이라면 이 시점에서 여러분들에게 현실감 있게 와닿을 수가 없습니다.
그렇기 때문에 이번 챕터에서는 Spring Boot에 대한 대략적인 내용들만 이해하면 되고, 실제로 애플리케이션 제작에 사용되는 구체적인 사용법은 Section 3에서 천천히 알아가도록 하겠습니다.
Spring Boot을 사용해야 하는 이유
우리가 Spring Boot을 사용해야 하는 현실적인 이유는 다음과 같습니다.
- XML 기반의 복잡한 설계 방식 지양
- 의존 라이브러리의 자동 관리
- 애플리케이션 설정의 자동 구성
- 프로덕션급 애플리케이션의 손쉬운 빌드
- 내장된 WAS를 통한 손쉬운 배포
XML 기반의 복잡한 설계 방식 지양
[Spring Framework을 배워야 하는 이유] 챕터에서 잠깐 언급했다시피 Spring Boot 이 전의 Spring 애플리케이션 개발을 위한 설정은 굉장히 복잡했습니다.
하지만 Spring Boot으로 인해 개발자는 Spring의 복잡한 설정에 대한 어려움으로부터 벗어날 수 있게 되었습니다.
의존 라이브러리의 자동 관리
Spring Boot 이전에는 애플리케이션에서 필요한 라이브러리를 사용하기 위해서는 필요한 라이브러리의 이름과 버전을 일일이 추가해 주어야 했습니다. 이로 인해 라이브러리 간의 버전 불일치로 인한 빌드 및 실행 오류 역시 빈번하게 발생을 했던 게 사실입니다.
하지만 Spring Boot의 starter 모듈 구성 기능을 통해 의존 라이브러리를 수동으로 설정해야 하는 불편함이 사라졌습니다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
implementation 'com.h2database:h2'
}[코드 2-17] 웹 애플리케이션 개발을 위한 Spring Boot의 의존 라이브러리 설정
[코드 2-17]은 Spring Boot에서 웹 애플리케이션을 개발하기 위한 기본적인 의존 라이브러리 설정 예입니다.
코드에서 보다시피 단 네 줄의 설정만으로 데이터베이스와의 연동은 물론 애플리케이션에 대한 모든 테스트까지 진행할 수 있습니다.

[그림 2-19] Spring Boot 의존 라이브러리 설정을 통해 실제 애플리케이션에서 의존하는 라이브러리가 포함된 모습 예
[그림 2-19]는 단 네 줄의 의존 라이브러리 설정을 통해 Spring 애플리케이션 구현 시 필요한 의존 라이브러리를 포함하고 있는 모습입니다.
이처럼 Spring Boot을 사용하면 개발자가 의존 라이브러리를 직접 관리해야 하는 부담에서 벗어날 수 있습니다.
애플리케이션 설정의 자동 구성
Spring Boot은 스타터(Starter) 모듈을 통해 설치되는 의존 라이브러리를 기반으로 애플리케이션의 설정을 자동으로 구성합니다.
예를 들면,
- “implementation 'org.springframework.boot:spring-boot-starter-web’” 와 같은 starter가 존재한다면 애플리케이션이 웹 애플리케이션이라고 추측한 뒤, 웹 애플리케이션을 띄울 서블릿 컨테이너(디폴트: Tomcat) 설정을 자동으로 구성합니다.
- “implementation 'org.springframework.boot:spring-boot-starter-jdbc’” 와 같은 starter가 존재한다면 애플리케이션에 데이터베이스 연결이 필요하다고 추측한 뒤, JDBC 설정을 자동으로 구성합니다.
이처럼 Spring Boot에서 지원하는 자동 구성으로 인해 여러분들이 애플리케이션에 대한 설정을 직접 해야 하는 번거로움을 최소화해 줍니다.
이러한 자동 구성을 활성화하기 위해서 여러분들이 해야 할 일은 아래와 같은 애너테이션을 코드에 추가해 주는 것뿐입니다.
@SpringBootApplication // (1)
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
}[코드 2-18] Spring Boot 자동 구성 활성화 예
(1)과 같이 @SpringBootApplication 애너테이션을 Spring 애플리케이션 코드에 추가해 주면 Spring Boot에서 자동 구성 설정을 활성화해줍니다.
Spring과 관련된 코드는 지금은 몰라도 됩니다. Spring에 친숙해지는 시간이라 생각하면서 걱정하지 말고 편하게 읽어주세요.
프로덕션급 애플리케이션의 손쉬운 빌드
Spring Boot을 사용하면 여러분들이 개발한 애플리케이션 구현 코드를 손쉽게 빌드하여 여러분들이 직접 빌드 결과물을 War 파일 형태로 WAS(Web Application Server)에 올릴 필요가 없습니다.

[그림 2-20] Spring Boot에서의 애플리케이션 빌드 예
[그림 2-20]은 Spring Boot에서 애플리케이션 빌드 명령을 실행하는 화면입니다.
[bootJar] 명령을 더블 클릭 하게 되면 [그림 2-21]과 같은 빌드 결과물이 생성됩니다.

[그림 2-21] Spring Boot에서의 빌드 시, 생성되는 빌드 결과물
[그림 2-21]처럼 [bootJar] 명령을 실행해서 생성된 jar 파일은 즉시 시작 가능한 애플리케이션 실행 파일로 사용됩니다.
WAS(Web Application Server)란?
Java 기반의 웹 애플리케이션을 배포하는 일반적인 방식은 개발자가 구현한 애플리케이션 코드를 WAR(Web application ARchive) 파일 형태로 빌드한 후에 WAS(Java에서는 서블릿 컨테이너라고도 부릅니다)라는 서버에 배포해서 해당 애플리케이션을 실행하는 것입니다. (Java 진영에서 사용되는 대표적인 WAS에는 Tomcat이 있습니다)
즉, WAS는 구현된 코드를 빌드해서 나온 결과물을 실제 웹 애플리케이션으로 실행되게 해주는 서버입니다.
내장된 WAS를 통한 손쉬운 배포
Spring Boot은 Apache Tomcat이라는 WAS를 내장하고 있기 때문에 별도의 WAS를 구축할 필요가 없으며, Spring Boot을 통해 빌드된 jar 파일을 이용해서 아래와 같은 명령어 한 줄만 입력해주면 서비스 가능한 웹 애플리케이션을 실행할 수 있습니다.

[그림 2-22] Spring Boot 기반 웹 애플리케이션 실행 화면
[그림 2-22]는 Spring Boot 기반의 웹 애플리케이션을 실행시킨 화면입니다.
이처럼 Spring Boot을 사용하면 ‘java -jar <jar 파일명>.jar’ 명령어를 통해 여러분들이 만든 애플리케이션을 손쉽게 실행할 수 있습니다.
Spring Boot의 핵심 콘셉트
Spring Boot의 핵심 콘셉트는 아래 한 문장으로 정리할 수 있습니다.
“Spring 구성은 Spring에게 맡겨버리고 비즈니스 로직에만 집중하자!”
다른 건 몰라도 이 한 문장만은 여러분들이 꼭 기억하길 바랍니다.
핵심 포인트
- Spring Boot은 Spring 설정의 복잡함이라는 문제점을 해결하기 위해 생겨난 Spring Project 중 하나이다.
- Spring Boot을 사용해야 하는 이유
- Spring Boot은 XML 기반의 복잡한 설계 방식을 지양한다.
- Spring Boot의 starter 모듈 구성 기능을 통해 의존 라이브러리를 자동으로 구성해 준다.
- 애플리케이션 설정의 자동 구성
- Spring Boot은 프로덕션급 애플리케이션의 빌드를 손쉽게 할 수 있다.
- Spring Boot은 내장된 WAS를 사용가능하기 때문에 배포가 용이하다.
- Spring Boot의 핵심 콘셉트
- Spring 구성은 Spring에게 맡겨버리고 비즈니스 로직에만 집중하자!
심화 학습
- 아파치 톰캣(Apache Tomcat) 이외에 Spring Boot에서 사용할 수 있는 서블릿 컨테이너(WAS라고도 부름)에는 어떤 것들이 있는지 구글에서 검색해 보세요.
Spring Framework Core
우리가 무엇인가를 배우고 학습할 때 가장 중요한 것 중에 하나는 전체적인 학습의 맥락을 잘 파악하는 일입니다.
효과적인 학습은 전체 주제의 큰 흐름 속에서 오늘 내가 학습해야 하는 과제의 위치를 고민해 보고, 나의 학습 성취도와 속도에 맞춰 적절한 학습 전략을 세워갈 때 보다 잘 이뤄질 수 있습니다.

같은 맥락에서, 이번 유닛에서 본격적인 스프링의 핵심 개념을 학습하기 전, 우리는 먼저 지금까지 우리가 배워왔던 내용들을 잠시 정리해 보면서 앞으로 배워나갈 학습 내용과 방향성에 대해 생각해 보도록 하겠습니다.
지금까지 학습한 모든 내용들을 세세하게 요약하고 정리하기는 어렵기 때문에, 특별히 이번 유닛과의 연결 고리가 있는 내용들을 먼저 선별하여 정리하고, 그 연장선 상에서 앞으로 우리가 배워갈 내용들을 간략하게 소개하겠습니다.
먼저, 우리는 자바 학습을 통해 프로그래밍에 대한 기본적인 이해를 바탕으로 자바라는 언어의 핵심적인 개념과 문법에 대해 학습했습니다. 특별히, 자바 언어의 심장이라 할 수 있는 객체 지향 프로그래밍에 대한 이론적인 내용들을 배우고, 그 토대 위에 버거퀸 실습 과제를 통해 학습한 이론들이 실제적으로 어떻게 적용될 수 있는지 이해할 수 있었습니다.

우리가 앞서 배웠던 객체 지향 프로그래밍의 핵심 내용을 몇 가지로 요약하면 다음과 같이 정리할 수 있습니다.
- 객체 지향 패러다임(Object-oriented Programming Paradigm; OOP)의 출발점은 객체이며, 각각의 객체가 적절한 역할과 책임을 가지고 특정한 기능을 수행하기 위해 협력하도록 만드는 일과 관련이 있다.
- 객체 지향적 설계의 핵심은 변화와 확장에 유연하도록 프로그램을 고안하는 것이며, 이를 위해 반드시 필요한 일이 인터페이스를 활용한 역할과 구현의 분리이다.
- 객체 간의 의존 관계가 높은 경우, 그 관계의 결합도가 높다고 할 수 있으며, 이는 변화와 확장에 유연한 코드 설계에 위배되는 것으로 최대한 지양해야 한다.
- 캡슐화를 통해 각 객체의 자율성을 보장하고 응집도를 높이되, 다른 객체와의 강한 결합도를 낮춰 유기적인 협력관계에 참여할 수 있도록 코드를 설계해야 한다.
위의 내용이 잘 기억이 나지 않는다면, 객체 지향 프로그래밍 심화 유닛의 실습 과제 중 객체 지향 원리 적용에 대한 내용을 꼭 다시 확인하고, 다음 학습으로 넘어가길 권장드립니다.
스프링 프레임워크는 결국 위에서 요약한 객체지향적 프로그램 설계를 보다 효과적이고 간편하게 구현할 수 있도록 도와줄 수 있는 도구로서 개발되었기 때문에, 위에서 요약한 객체 지향 프로그래밍의 핵심 개념에 대한 바른 이해는 앞으로의 학습에 있어서 매우 중요하기 때문입니다.

다음으로, 우리는 먼저 추후 요긴하게 활용될 데이터베이스와 스키마 디자인을 학습했고, 앞선 Spring Framework 기본 유닛을 통해 본격적인 스프링 프레임워크에 대한 학습을 시작했습니다.
앞서 스프링 프레임워크와 관련한 핵심적인 내용을 다음과 같이 요약하여 정리할 수 있습니다.
- 프레임워크(Framework)란 어떤 애플리케이션을 만들기 위한 틀 또는 구조를 의미하며, 코드 흐름의 제어권이 개발자가 아닌 프레임워크에 있다는 점에서 개발자가 주도권을 가지는 라이브러리(Library)와 구분될 수 있다.
- 스프링 프레임워크는 POJO 프로그래밍을 지향하면서 IoC/DI, AOP, PSA라는 세 가지 축을 통해 이를 달성하고자 한다.
- 스프링 프레임워크는 다양한 기능들을 제공하는 모듈들의 묶음으로 구성된다.
- 스프링부트는 의존 라이브러리의 자동 관리, 설정의 자동 구성, 손쉬운 빌드 및 배포 등의 강력한 장점들을 가지고, 개발자가 비즈니스 로직에만 집중할 수 있도록 도와준다.
마찬가지로 위의 내용이 잘 기억나지 않는다면, 바로 이전의 Spring Framework 기본 유닛을 다시 확인해 주시고 다음 학습으로 넘어가길 권장드립니다.
어떤가요?
정리된 내용을 보니 잊혀가던 기억이 다시 새록새록 떠오르나요?
앞서 설명한 것처럼, 지금부터 본격적으로 학습하게 되는 스프링의 핵심 개념과 원리들은 이렇게 우리가 지금까지 배우고 학습한 개념들의 터 위에 세워지게 됩니다. 스프링 프레임워크는 자바 언어가 가지는 객체 지향 프로그래밍 패러다임을 잘 반영하여 의도한 서비스 또는 프로그램을 보다 효과적이고 간편한 방식으로 구현할 수 있도록 돕는 매우 효과적인 도구입니다.
그러면 지금부터 본격적으로 코드 예제와 함께 우리들의 코드 작업을 한층 효과적이고 즐겁게 변모시켜 줄 스프링 프레임워크의 핵심 개념들에 대해 하나씩 알아보도록 합시다.
DI(Dependency Injection)
지난 Spring Framework 기본 유닛에서 우리는 의존성 주입(Dependency Injection; 이하 DI)이 무엇이며, 왜 필요하고, 어떻게 사용할 수 있는지에 대한 개념적인 내용을 중심으로 학습했습니다.
앞서 배웠던 내용을 요약해 보면, DI란 일반적인 의미의 IoC(제어의 역전) 개념을 스프링 프레임워크의 맥락에서 구체화시킨 것으로, 객체 간의 의존 관계를 객체가 직접 생성하는 것이 아닌 외부로부터 주입 또는 전달받는 방식을 의미합니다.

의존성 주입이 필요한 이유는 우리가 앞서 배웠던 객체 지향적 코드 설계의 과정 속에서 객체 간의 강한 결합도를 낮춰 보다 변경과 확장에 유연한 코드를 작성하기 위함이며, 대부분의 경우 생성자를 통해 의존 관계를 주입받는 생성자 주입 방식(Constructor Injection)을 사용한다는 사실을 이해할 수 있었습니다.
이러한 흐름 속에서 이제 우리는 자바에서 객체 지향 프로그래밍을 학습하며 실습했었던 실습 과제를 스프링으로 전환하는 과정을 통해 머리로 이해한 이론적인 내용들을 좀 더 우리의 것으로 체화시키고, 학습한 내용을 기반으로 DI를 비롯한 좀 더 구체적인 스프링의 핵심 동작 원리와 개념들을 이해해 보는 시간을 가질 것입니다.
본격적인 내용에 들어가기 앞서, 정리했던 내용이 잘 기억이 안 나거나 충분히 이해가 안 되었다고 생각된다면 다시 앞에서 배웠던 내용을 복습하고, 이어지는 내용을 학습하길 권장드립니다.
자, 준비되었다면 이제 정말 출발해 볼까요?
학습 목표
- 키오스크 프로그램을 스프링으로 전환해 보면서 스프링의 핵심 개념에 대해 이해할 수 있다.
- 기본적인 테스트 케이스의 개념과 구조를 이해하고, 간단한 테스트 케이스를 작성할 수 있다.
- 스프링 컨테이너가 싱글톤 컨테이너임을 이해하고, 그 내용을 설명할 수 있다.
- @Configuration과 @Bean 애너테이션을 사용하는 수동 주입과 @ComponentScan과 @Component를 사용하는 자동 주입의 차이에 대해 이해하고, 이를 활용할 수 있다.
- @Autowired 애너테이션의 특성과 작동 방식에 대해 이해하고, 적절하게 활용할 수 있다.
https://github.com/Lucky-kor/be-spring-kiosk
GitHub - Lucky-kor/be-spring-kiosk
Contribute to Lucky-kor/be-spring-kiosk development by creating an account on GitHub.
github.com
키오스크 프로그램 - 스프링
자, 그럼 먼저 우리가 기존에 순수한 자바 코드를 사용하여 작성했었던 키오스크 프로그램 실습과제를 스프링 프레임워크를 사용하도록 전환해 보면서 스프링의 핵심 원리에 대해 점진적으로 하나씩 알아가 보도록 하겠습니다.
아래의 안내를 따라 순차적으로 하나씩 진행해 주세요.
프로젝트 준비하기
동일한 선상에서 학습을 진행하기 위해, 실습을 위한 가장 기본적인 단계의 스프링 부트 프로젝트는 사전에 미리 생성이 되어 있습니다. 아래 안내를 참고하여 프로젝트를 준비해 봅시다.
참고로, 아래의 프로젝트는 원활한 실습을 위해 약간의 디렉토리 구조 변경 및 코드 리팩토링이 되어있습니다. 하지만, 기본적인 코드의 흐름과 구성은 기존에 실습했던 과제와 크게 다르지 않기 때문에 전반적인 코드의 흐름을 이해하는 데 크게 어려운 부분은 없을 것입니다.
먼저, 위의 github 링크에서 실습용 리포지토리를 fork한 후에 git clone 명령어를 사용하여 로컬 리포지토리로 복제하겠습니다.

다음으로 여러분들의 IntelliJ로 로컬에 복제한 리포지토리의 프로젝트를 열어주세요.
- 위의 그림과 같이 build.gradle을 선택하거나 해당 폴더를 프로젝트로 열 수 있습니다.
- 프로젝트가 열리면 Gradle이 자동으로 의존 관계가 있는 라이브러리를 다운로드하고 설정을 진행합니다. 설정이 완료될 때까지 잠시 기다려주세요.
의존 라이브러리 다운로드 및 설정이 모두 끝나면, 프로젝트 디렉토리 구조 및 클래스 파일들을 확인하면서 우리가 이전에 배웠던 내용들을 다시 살펴봅니다. 혹시 내용이 잘 기억나지 않는다면, 자바에서 학습했던 내용으로 다시 돌아가서 내용을 복습하는 것도 매우 좋은 방법입니다.
지금 당장 모든 내용이 잘 이해가 되지 않더라도 괜찮습니다.
순수 자바로 만들었던 우리 프로젝트를 스프링으로 전환하는 과정에서 비슷한 개념과 원리들이 계속 반복해서 등장하기 때문에, 이해가 될 때까지 여러 번 반복하는 과정을 거치다 보면 금세 모든 것이 자연스럽게 다가갈 것입니다.
이전과 동일하게 Main 실행 클래스의 main() 메서드를 통해 버거퀸 프로그램이 문제없이 잘 작동하는지 확인하셨다면, 이제 아래의 학습 콘텐츠를 통해 버거퀸 프로그램을 스프링으로 전환해 보도록 하겠습니다.
스프링 전환
우리 프로젝트를 스프링으로 전환하기 전, 잠시 우리가 이전에 배웠던 내용을 복기해보도록 하겠습니다.
결국 스프링 프레임워크이라는 도구는 앞서 우리가 경험했던 것처럼 객체지향적인 코드 설계를 수행할 때 필연적으로 통과해야 하는 어려움과 문제들을 보다 효과적으로 해결하기 위해 만들어진 것이라는 사실을 기억하는 것이 중요합니다. 즉, 순수 자바 코드로 코드를 작성했을 때 직면해야 했었던 한계와 어려움에 대해 더 뚜렷하게 인식할수록 스프링이 우리에게 제공하는 강력한 이점들을 보다 분명하게 경험할 수 있습니다.
기존의 코드에서 추가된 부분은 아래와 같습니다.

1. 할인 정책을 추가했습니다. 위의 패키지에 2가지 정책이 적용되어 있습니다.

2. kiosk.java 에서 할인 정책을 생성자를 통해 전달받고 있습니다.

3. 주문 기능에서, 각 상품의 금액에 할인율을 적용하고 있습니다.

4. 메인 프로그램에서, Kiosk 객체를 생성할 때, 할인 객체를 생성해 전달하고 있습니다.
앞의 내용에서 우리가 마주할 수 있는 문제가 어떤게 있을까요?
- 새로운 할인 정책을 도입하는 데 있어 부수적으로 변경해야 할 코드들이 너무 많았고, 이것은 변화와 확장에 유연한 객체지향적 코드 설계 원칙에 위배된다. (개방-폐쇄 원칙(Open-Closed Principle; OCP) 위반)
- 문제 발생의 핵심적인 지점은 특정 객체가 어떤 객체를 사용할 것인지 직접 결정한다는 점에 있었다. 즉, 역할이 아닌 구현에 의존하고 있었다. (의존성 역전 원칙(Dependency Inversion Principle; DIP) 원칙 위반)
인터페이스를 도입하고 객체지향의 다형성을 활용하여 DiscountPolicy 타입의 참조변수를 만들었지만, 구현 객체는 여전히 new 연산자를 사용하여 FixedRateDiscountPolicy에게 직접적으로 의존하고 있어 같은 문제가 반복되고 있습니다. (DIP 위반)
다른 말로 표현하자면, 객체 간 높은 결합도를 보이고 있습니다.

앞에서 사용했던 비유를 떠올려보면, 이 상황은 마치 어떤 연극이나 영화의 남배우가 여배우의 역할에 집중하여 연기를 펼치는 것이 아니라, 송혜교나 김태희와 같은 구체적인 특정 인물을 직접 선택하고 특정 배우에 의존해서 연기를 펼치는 것과 같다고 했습니다.
또한 이런 경우, 구체적이고 특정한 배우에 의존하고 있기 때문에, 송혜교나 김태희가 다른 여배우로 교체되는 순간 남배우는 새롭게 등장한 여주인공을 위해 다시 새롭게 연기 연습을 해야 한다고 했습니다. 그 반대의 경우도 마찬가지입니다.

DI
이번 챕터에서는 스프링으로 전환한 실습과제에서 의존성 주입이 어떻게 일어나고 있는지 좀 더 자세히 살펴보도록 하겠습니다.
앞에서 언급했던 것처럼, 같은 개념을 여러 번 반복하는 것은 그만큼 이 기술이 빈번하게 사용되는 스프링의 핵심 중에 핵심 개념이기 때문입니다. 아래 예제를 보면서, 다시 한번 DI에 대한 개념을 꼼꼼하게 복습하고 실제로 코드를 반복해서 작성해 보면서 충분히 이해하는 시간을 가져주세요.
그럼 먼저 우리 코드에서 의존성 주입이 일어나는 모든 지점들을 나열하여 쭉 한번 살펴보겠습니다.
- KioskApplication 클래스
public class KioskApplication implements CommandLineRunner {
private Kiosk kiosk;
@Autowired
public KioskApplication(Kiosk kiosk) {
this.kiosk = kiosk;
}
}
- Kiosk 클래스
public class Kiosk {
private MenuItem[] menuItemArray;
private Printer printer;
private DiscountPolicy discountPolicy;
@Autowired
public Kiosk(MenuItem[] menuItemArray, Printer printer, DiscountPolicy discountPolicy) {
this.menuItemArray = menuItemArray;
this.printer = printer;
this.discountPolicy = discountPolicy;
}
위의 코드를 확인해 보면 공통적으로 두 가지 특징을 가지고 있습니다.
먼저는 1) 외부로부터 특정한 객체를 주입받아 this 키워드를 사용하여 내부 필드에 할당하여 값을 사용하고 있다는 사실과 2) 모두 생성자를 통해서 객체를 주입받고 있다는 점입니다. 여기서 주입을 받는 대상이 되는 객체는 외부로부터 어떤 객체의 참조값이 들어올지 알지 못하고 단순히 주입받은 객체를 받아 사용할 뿐이라 했습니다.
앞서 설명한 것처럼, 대부분의 경우 애플리케이션이 종료되기까지 의존 관계가 변하지 않기 때문에, 위와 같이 생성자를 통해 객체의 참조값이 주입되는 방법을 사용하지만 이 외에도 setter 메서드를 사용한 주입(setter 주입)과 필드에 직접 주입하는 방식(필드 주입)이 존재합니다.
부득이하게 의존 관계의 변경이 필요하거나 간단한 테스트를 실행하는 경우에는 setter 메서드와 필드 주입이 사용되기도 하지만 이러한 방법들은 주로 권장되는 방법이 아닙니다. 공식 문서에서도 생성자 주입 방식을 사용할 것을 권장하고 있습니다. 만약 좀 더 자세한 내용이 궁금하다면 여기를 참고해 주세요.
또 한 가지는, 앞에서 언급한 것처럼 각각의 필드의 접근 제어자가 private 키워드를 통해 선언되었다는 사실입니다. 다르게 표현하자면, 최초에 객체 인스턴스가 생성될 때 생성자를 통해 주입된 각각의 필드의 값은 다시 수정될 수 있는 방법이 없습니다.
앞에서 우리가 배웠던 내용에 대한 기억을 더듬어 왜 이렇게 정의를 하고 있는 지 생각해 볼까요?
그렇습니다. 앞에서 우리가 학습한 객체지향의 4가지 기둥 중 하나인 캡슐화를 구현하기 위함입니다. 즉, 내부에서 사용되는 데이터들이 개발자의 실수 또는 어떤 원인을 통해 임의로 변경되지 않도록 보호하고 외부로의 노출을 방지하기 위한 것이라 생각할 수 있습니다.
같은 맥락에서 생성자 주입의 경우, private 접근 제어자와 함께 final 키워드를 함께 종종 사용하여 값의 변경을 원천적으로 차단하기도 합니다. final 키워드를 사용하는 경우, 해당 값이 들어오지 않는 경우 컴파일러가 곧바로 에러를 알려주기 때문에 개발자의 실수에 의한 오류를 방지할 수 있다는 장점이 있습니다.
여기까지가 주입받는 객체의 입장이었습니다.
그렇다면 그 반대편에서 객체를 외부로부터 주입해 주는 주체는 누구였나요?
- AppConfig 클래스
@Configuration
public class AppConfig {
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
@Bean
public MenuItem[] menuItems() {
return new MenuItem[]{
new MenuItem("김밥", 1500),
new MenuItem("계란 김밥", 2000),
new MenuItem("충무 김밥", 8000),
new MenuItem("치즈 김밥", 4000),
new MenuItem("참치 김밥", 4500),
new MenuItem("돈까스 김밥", 5000),
new MenuItem("떡볶이", 5000),
new MenuItem("라볶이", 6000),
new MenuItem("쫄면", 6500),
new MenuItem("우동", 4500)
};
}
@Bean
public DisplayPrinter printer() {
return new DisplayPrinter();
}
@Bean
public Kiosk kiosk(MenuItem[] menuItems, DisplayPrinter printer, DiscountPolicy discountPolicy) {
return new Kiosk(menuItems, printer, discountPolicy);
}
}
맞습니다. 앞에서 봤던 것처럼 AppConfig가 객체를 생성하고 의존 관계를 연결시키는 역할을 한다고 했습니다. 마치 공연의 기획자처럼, AppConfig 클래스는 어떤 배우가 어떤 역할을 담당할지 결정하고(객체의 생성), 극의 전반적인 구성을 조율(의존관계 주입)하는 역할을 담당합니다. 이 내용은 매우 중요하기 때문에 그만큼 여러 번 강조해서 반복하고 있습니다.
참고로 모든 비유가 그렇듯이, 공연 기획자에 대한 비유도 실제 현실과 100% 일치한다고 말하기는 어렵습니다. 처음으로 배우는 단계에서 이해를 돕기 위한 첫 단추라고 생각하고, 차차 좀 더 깊은 내용들을 학습해 가시기를 권장드립니다.
그러면 다시 돌아가서, 대표적인 예시로 할인 정책을 결정하는 부분을 잠시 살펴볼까요?
- AppConfig 클래스
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
Discount 클래스의 생성자는 객체가 최초에 생성될 때, 각각 정률 할인(FixedRateDiscountPolicy)과 정액 할인(FixedAmountDiscountPolicy)이 적용될 수 있도록 객체들 간 의존 관계를 구성하는 역할을 수행하고 있습니다.
참고로, 정률 할인이란 특정한 비율에 따라 할인(ex. 5% 할인)을 적용하는 것이며, 정액 할인이란 특정한 액수(ex. 500원)에 따라 할인을 적용하는 것을 의미합니다.
만약 여기서 현재 정액 할인이 적용되어 있는 부분을 정액 할인으로 변경하고 싶다면 어떻게 해야 할까요?
- AppConfig 클래스
@Configuration
public class AppConfig {
@Bean
public DiscountPolicy discountPolicy() {
return new FixedRateDiscountPolicy(20);
}
--- 생략 ---
}
앞에서 확인했던 것처럼 위와 같이 아주 간단하게 할인 정책의 객체만 바꿔주면 모든 코드 작성이 끝났습니다. 이렇게 코드를 수정하기 전에 일일이 번거롭게 코드를 수정해야 했던 반대의 경우는 앞에서 여러 번 언급했기 때문에 여기서는 생략하겠습니다.
결론적으로, 계속 강조한 것처럼 객체지향 프로그래밍의 가장 중요한 핵심 중에 하나는 변경과 확장에 유연한 코드를 설계하는 것이며, 위의 코드 예제를 통해서 확인할 수 있었던 것처럼 그 중심에는 DI가 있습니다. DI가 없었다면, 역할과 구현을 구분할 수는 있었을지언정 객체 간 직접적으로 강하게 결합되는 것을 피할 방도를 달리 찾을 수 없었을 것입니다.
그런데, 이 부분도 결국 자바 코드로 의존성 주입에 대한 코드를 직접 작성하고 있습니다. 현재 스프링을 적용하고 있는데, 매번 이 과정을 거쳐야 할까요?
코드를 좀 더 개선하여, 더 편리한 방법으로 DI를 활용할 수 있습니다.
다음 버전에서 개선된 코드를 살펴보겠습니다.
스프링 컨테이너와 빈
이번 챕터에서는 그렇다면 앞서 간단하게 설명한 스프링 컨테이너(Spring Container)와 스프링 빈(Spring Bean)이 무엇인지 좀 더 구체적인 내용들을 살펴보겠습니다.
- KioskApplication 실행 클래스
@SpringBootApplication
public class KioskApplication implements CommandLineRunner {
private Kiosk kiosk;
@Autowired
public KioskApplication(Kiosk kiosk) {
this.kiosk = kiosk;
}
public static void main(String[] args) {
SpringApplication.run(KioskApplication.class, args);
}
@Override
public void run(String... args) {
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// (2) 빈 조회
DiscountPolicy discountPolicy = applicationContext.getBean("discountPolicy", DiscountPolicy.class);
Printer printer = applicationContext.getBean("printer", Printer.class);
Kiosk kiosk_check = applicationContext.getBean("kiosk", Kiosk.class);
--- 생략 ---
먼저 앞서 우리가 봤었던 KioskApplication 실행 클래스를 좀 더 자세히 살펴보겠습니다.
(1) 스프링 컨테이너 생성
앞에서 프로그램을 스프링 전환하는 과정에서 간략하게 언급했던 것처럼, ApplicationContext 인터페이스를 일반적으로 스프링 컨테이너라고 부릅니다.
좀 더 정확하게는 스프링 컨테이너를 말할 때 ApplicationContext가 상속하고 있는 BeanFactory와 구분해서 사용하지만, BeanFactory를 직접 사용하는 경우는 거의 없기 때문에 일반적으로 ApplicationContext를 스프링 컨테이너라 합니다.

참고로, BeanFactory는 스프링 컨테이너의 최상위 인터페이스로 스프링 빈을 관리하고 조회하는 역할을 담당합니다. 곧 뒤에서 보게 될 getBean() 메서드를 제공하는 주체도 바로 BeanFactory입니다.
그렇다면 BeanFactory 인터페이스를 상속하고 있는 ApplicationContext는 BeanFactory와 무엇이 다를까요?
사실 ApplicationContext가 상속하고 있는 것은 BeanFactory뿐만이 아닙니다.
- ApplicationContext 인터페이스

여러분들의 인텔리제이에서 ApplicationContext 인터페이스에 대한 정보를 찾아보면, 이 사실을 직접 확인할 수 있습니다.
위의 그림에서 확인할 수 있는 것처럼 ApplicationContext는 BeanFactory로부터 확장된 인터페이스뿐만 아니라 EnvironmentCapable, MessageSource, ApplicationEventPublisher, ResourcePatternResolver 등 다양한 기능의 인터페이스들을 상속받아 사용하고 있습니다. 이러한 인터페이스들은 환경 변수 설정, 메시지 국제화 기능, 이벤트 발생, 리소스 조회 등 다양한 기능들을 지원합니다.
정리하면, ApplicationContext는 빈을 관리하고 조회하는 기능뿐 아니라 웹 애플리케이션을 개발하는 데 필요한 다양한 부가 기능들을 함께 제공합니다.
다음으로, AnnotationConfigApplicationContext는 그 구현 객체이며 매개변수로 구성 정보(AppConfig.class)를 넘겨주고 있습니다.

참고로, 스프링 컨테이너는 우리가 했던 것처럼 애너테이션 기반 자바 설정 클래스로도 만들 수 있지만, XML(Extensible Markup Language)를 기반으로 생성하는 것도 가능합니다. XML은 데이터를 정의하는 규칙을 제공하는 마크업 언어로서, 컴퓨터 시스템 간의 공유 가능한 방식으로 데이터를 정의하고 저장할 수 있습니다. 좀 더 자세한 내용이 궁금하다면 여기를 참고해 주세요.
스프링 컨테이너는 이렇게 넘겨받은 구성 정보를 가지고 메서드들을 호출하여 빈을 생성하고, 빈들 간의 의존 관계를 설정합니다. 이렇게 빈을 생성하는 과정에서, 스프링 컨테이너는 호출되는 메서드의 이름을 기준으로 빈의 이름을 등록합니다.
AppConfig 클래스
package com.springboot.v2;
import com.springboot.v2.discount.DiscountPolicy;
import com.springboot.v2.discount.FixedAmountDiscountPolicy;
import com.springboot.v2.helper.DisplayPrinter;
import com.springboot.v2.helper.Printer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AppConfig {
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
@Bean
public MenuItem[] menuItems() {
return new MenuItem[]{
new MenuItem("김밥", 1500),
new MenuItem("계란 김밥", 2000),
new MenuItem("충무 김밥", 8000),
new MenuItem("치즈 김밥", 4000),
new MenuItem("참치 김밥", 4500),
new MenuItem("돈까스 김밥", 5000),
new MenuItem("떡볶이", 5000),
new MenuItem("라볶이", 6000),
new MenuItem("쫄면", 6500),
new MenuItem("우동", 4500)
};
}
@Bean
public DisplayPrinter printer() {
return new DisplayPrinter();
}
@Bean
public Kiosk kiosk(MenuItem[] menuItems, DisplayPrinter printer, DiscountPolicy discountPolicy) {
return new Kiosk(menuItems, printer, discountPolicy);
}
}예를 들면, 우리가 넘긴 구성 정보에서 @Bean 애너테이션이 붙어있는 discountPolicy()라는 이름의 메서드의 호출 결과로 반환된 new FixedAmountDiscountPolicy(100) 객체 빈은 discountPolicy라는 이름으로 스프링 컨테이너의 빈 리스트에 저장이 되는 방식입니다.
아래에서 보겠지만, 아래와 같은 코드로 저장된 빈 객체를 불러올 수 있습니다.
- 빈 조회 - getBean(빈 이름, 타입)
- DiscountPolicy discountPolicy = applicationContext.getBean("discountPolicy", DiscountPolicy.class);
참고로, 필요에 따라서 아래와 같이 빈의 이름을 다르게 설정해 줄 수도 있습니다.
- AppConfig 클래스 - 빈 이름 설정
@Configuration
public class AppConfig {
@Bean(name="discountPolicy2")
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
만약 위와 같은 방식으로 빈의 이름을 등록해 줄 시, 같은 이름의 빈이 등록되는 경우 에러의 원인이 되므로, 항상 다른 이름의 빈을 생성하도록 각별히 주의해야 합니다.
(2) 빈 조회
스프링 컨테이너가 관리하는 자바 객체를 스프링 빈(Bean)이라 한다 했습니다.
빈은 클래스의 등록 정보, getter/setter 메서드를 포함하며, 앞서 본 것처럼 구성 정보(설정 메타 정보)를 통해 생성됩니다.

빈과 관련된 좀 더 자세한 정보가 궁금하시다면, 여기 공식 문서를 참고해 보시길 바랍니다.
위에서 살펴본 내용처럼, 우리가 넘긴 구성 정보를 토대로 스프링 컨테이너가 빈을 생성하고 의존 관계를 연결해 주면 이제 스프링 컨테이너의 관리 하에 있는 객체 빈들을 아래와 같이 getBean() 메서드로 조회할 수 있습니다.
- KioskApplication 실행 클래스 - 빈 조회
@SpringBootApplication
public class KioskApplication implements CommandLineRunner {
private Kiosk kiosk;
@Autowired
public KioskApplication(Kiosk kiosk) {
this.kiosk = kiosk;
}
public static void main(String[] args) {
SpringApplication.run(KioskApplication.class, args);
}
@Override
public void run(String... args) {
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// (2) 빈 조회
DiscountPolicy discountPolicy = applicationContext.getBean("discountPolicy", DiscountPolicy.class);
Printer printer = applicationContext.getBean("printer", Printer.class);
Kiosk kiosk_check = applicationContext.getBean("kiosk", Kiosk.class);
System.out.println(discountPolicy);
System.out.println(printer);
System.out.println(kiosk_check);
실제로 getBean() 메서드를 통해 불러온 빈들을 출력해 보면 아래 사진과 같이 객체 인스턴스의 참조값이 찍히는 것을 확인할 수 있습니다.
가장 기본적인 빈 조회 방법은 다음과 같습니다.
- getBean(빈 이름, 타입)
- 예시) applicationContext.getBean("discountPolicy", DiscountPolicy.class);
- getBean(타입)
- 예시) applicationContext.getBean(DiscountPolicy.class);
위의 두 가지 기본적인 방법으로 빈 조회가 가능합니다.
세 번째 방법으로 getBean(DiscountPolicy.class))처럼 구체 타입으로 빈 조회를 하는 방법도 있지만, 변경에 유연하지 않기 때문에 일반적으로 권장되지 않습니다.
만약 getBean(타입)으로 빈을 조회했을 때처럼 같은 타입의 객체가 두 개 이상 있는 경우에는 오류가 발생합니다. 이런 경우 @Qualifier 또는 @Primary 애너테이션을 사용하여 특정한 객체가 들어오거나 먼저 우선순위를 가지도록 설정해 줄 수 있습니다. 이것과 관련한 좀 더 자세한 내용은 뒤에서 @Autowired 애너테이션에 대해 학습하면서 좀 더 알아보겠습니다.
추가적으로, 아래와 같이 스프링 컨테이너에 있는 모든 빈을 조회하는 것도 가능합니다.
- Main 실행 클래스 - 모든 빈 조회
public class Main {
public static void main(String[] args) {
// (2) 모든 빈 조회
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfigurer.class);
String[] beanDefinitionNames = applicationContext.getBeanDefinitionNames();
for (String beanDefinitionName : beanDefinitionNames) {
Object bean = applicationContext.getBean(beanDefinitionName);
System.out.println("beanName=" + beanDefinitionName + " object=" + bean);
}
}
위의 코드처럼 getBeanDefinitionNames() 메서드를 사용하면, 아래의 그림처럼 스프링 컨테이너가 관리하는 모든 빈을 조회할 수 있습니다.
마지막으로, 각각의 빈은 해당 빈에 대한 메타 정보를 가지고 있는데, 앞으로 사용할 일이 많지는 않겠지만 이 정보들도 조회가 가능합니다. 참고로, 스프링 컨테이너는 이러한 메타 정보(BeanDefinition)를 기반으로 스프링 빈을 생성합니다.
- Main 실행 클래스 - 빈 메타 정보 조회
public class Main {
public static void main(String[] args) {
// (2) 빈 메타정보 조회
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfigurer.class);
String[] beanDefinitionNames = applicationContext.getBeanDefinitionNames();
for (String beanDefinitionName : beanDefinitionNames) {
BeanDefinition beanDefinition = applicationContext.getBeanFactory().getBeanDefinition(beanDefinitionName);
System.out.println("Bean name: " + beanDefinitionName + ", Scope: " + beanDefinition.getScope());
}
}
위의 코드를 입력하고 프로그램을 실행하면 다음 그림과 같은 각 빈들의 메타 정보를 얻을 수 있습니다.
지금 위의 코드를 이해하는 과정은 중요하지 않으니, 지금은 이렇게 각 빈들의 메타 정보 데이터를 얻어올 수 있다는 사실만 기억해 주세요.
테스트 케이스 작성 기초
지금까지 우리는 우리가 작성한 코드가 의도한 값을 바르게 도출하고 있는지 여부를 판단하기 위해 주로 아래와 같이 System.out.println() 메서드를 활용하여 콘솔에 값을 출력하는 방법을 사용하였습니다.
- KioskApplication 실행 클래스 - 빈 조회 & 출력
@SpringBootApplication
public class KioskApplication implements CommandLineRunner {
private Kiosk kiosk;
@Autowired
public KioskApplication(Kiosk kiosk) {
this.kiosk = kiosk;
}
public static void main(String[] args) {
SpringApplication.run(KioskApplication.class, args);
}
@Override
public void run(String... args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// (2) 빈 조회
DiscountPolicy discountPolicy = applicationContext.getBean("discountPolicy", DiscountPolicy.class);
Printer printer = applicationContext.getBean("printer", Printer.class);
Kiosk kiosk_check = applicationContext.getBean("kiosk", Kiosk.class);
System.out.println(discountPolicy);
System.out.println(printer);
System.out.println(kiosk_check);
사실 이렇게 콘솔에 값을 출력하는 방법은 경우에 따라 간편하게 우리가 의도한 값이 나왔는지 빠르게 테스트하기에 유용한 방법이지만, 가장 최선의 효과적인 방법이라 하기는 어렵습니다. 일일이 값을 이렇게 확인하는 일이 개발자 입장에서 번거롭기도 하지만 비용과 성능의 측면에서도 좋은 테스트 방법이 아니기 때문입니다.
다른 한편으로, 좋은 테스트를 잘 설계하는 일은 잠재적으로 발생할 수 있는 코드 상의 문제와 성능적인 비용을 최소화할 수 있을 뿐 아니라, 개발자 스스로 자신이 작성한 코드가 바르게 잘 작동하고 있다는 확신을 얻기 위해 매우 중요하다고 할 수 있습니다.

따라서, 이번 챕터에서는 어떤 기능 또는 계층 단위로 작게 작성한 테스트를 검증할 때 유용하게 사용될 수 있는 단위 테스트(Unit Test)에 대한 가장 기초적인 내용을 학습해 보겠습니다.
단위 테스트란 이름처럼 작은 단위의 어떤 특정한 기능을 테스트하고, 검증하기 위한 도구를 의미합니다. 다른 말로, 테스트 케이스(Test Case)를 작성한다고도 표현하는데, 그 과정에는 주로 입력 데이터, 실행 조건, 그리고 기대 결과에 대한 값이 포함됩니다.
스프링에서는 이러한 단위 테스트를 간편하고 효과적으로 수행할 수 있도록 자바 언어 기반의 JUnit이라는 오픈 소스 테스트 프레임워크를 제공하는데, 주로 각각의 단위 테스트는 메서드 단위로 작성됩니다. 좀 더 자세한 사용 방법은 아래에서 함께 확인해 보도록 하겠습니다.
사실 단위 테스트와 관련한 내용은 매우 중요하고 많은 내용을 담고 있기 때문에, 이어지는 섹션 3에서 한 유닛을 할애하여 좀 더 자세하게 다룰 예정입니다.
따라서 여기서는 가장 기본적이고 간단한 사용법을 중심으로 살펴보고, 앞에서 우리가 println() 메서드를 사용하여 빈을 조회했던 부분을 다시 JUnit을 활용하여 테스트해볼 수 있도록 코드를 변경해 보겠습니다.
JUnit 기본 테스트 구조
Spring Boot Initializr에서 Gradle 기반의 스프링 부트 프로젝트를 생성하고 해당 프로젝트를 오픈하면 기본적으로 src/test 디렉토리가 만들어집니다. 우리 프로젝트는 앞에서 이미 스프링 부트로 생성했기 때문에 아래 그림과 같이 자동으로 생성되어 있는 test 디렉토리를 확인할 수 있습니다.
- 자동으로 생성된 test 디렉토리 구조의 모습

JUnit을 사용하는 테스트는 기본적으로 위의 그림처럼 test 디렉토리 안에서 작성되는 것을 원칙으로 합니다. 또한, 테스트케이스 작성을 위한 디렉토리 구조는 앞서 우리가 main 패키지 안에 작성한 디렉토리 구조와 동일하게 작성하는 것을 권장합니다.
예를 들면, 우리가 앞에서 스프링 컨테이너 관리 하에 있는 빈을 조회했던 Main 클래스에 대한KioskApplicationTest 테스트 클래스는 아래 그림과 같은 디렉토리 구조를 가져야 합니다.
- 테스트 케이스 디렉토리 기본 구조 예시

참고로, 테스트 케이스 작성을 위한 테스트 클래스는 관례적으로 테스트의 대상이 되는 클래스의 이름에 Test를 붙여 클래스를 생성합니다.
그럼 이제 가장 기본적인 JUnit 테스트 케이스의 구조를 살펴보겠습니다.
- JUnit 테스트 케이스의 기본 구조
import org.junit.jupiter.api.Test;
public class JunitDefaultStructure {
@Test
public void test1() {
// 테스트하고자 하는 대상에 대한 테스트 로직 작성
}
@Test
public void test2() {
// 테스트하고자 하는 대상에 대한 테스트 로직 작성
}
@Test
public void test3() {
// 테스트하고자 하는 대상에 대한 테스트 로직 작성
}
}
위의 코드에서 확인할 수 있는 것처럼, Junit을 활용한 단위 유닛 테스트는 test1() , test2() , test3() 등 각각 검증하고자 하는 기능 단위에 따라 메서드로 작성이 되는데, 실질적인 내용을 살펴보면 크게 어렵지 않습니다.
가장 먼저, 여러분이 작성한 프로그램에서 테스트하고자 하는 대상에 public void test1() {...}과 같은 void타입의 메서드를 작성합니다. 원래 JUnit 5 이하 버전에서는 클래스와 메서드에 public과 static 키워드를 필수적으로 작성해야 했지만 Junit 5부터는 생략이 가능합니다.
이렇게 메서드를 생성한 이후에 각각의 메서드 레벨에 @Test 애너테이션을 붙여주고, 이제 메서드 바디 안에 테스트 로직을 작성하기만 하면 됩니다.
테스트 로직 작성
그럼 이제 이러한 기본적인 구조에 대한 이해를 가지고, 빈을 조회하는 간단한 테스트 케이스 로직을 작성하여 하나의 완전한 테스트 케이스를 만들어보도록 하겠습니다.
- MainTest 클래스 - 빈 조회 단위 테스트 작성
package com.springboot.v2;
import com.springboot.v2.discount.DiscountPolicy;
import org.assertj.core.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import static org.junit.jupiter.api.Assertions.*;
class KioskApplicationTest {
// 스프링 컨테이너 생성
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// 빈 조회 테스트케이스
@Test
void findBean() {
// (1) given => 초기화 또는 테스트에 필요한 입력 데이터
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// (2) when => 테스트 할 동작
DiscountPolicy discountPolicy = applicationContext.getBean("discountPolicy", DiscountPolicy.class);
// (3) then => 검증
Assertions.assertThat(discountPolicy).isInstanceOf(DiscountPolicy.class);
}
}
먼저, 앞에서 작성한 MainTest 클래스에 위의 코드를 작성하고 실행하여 테스트를 동작시켜 봅시다.
- 테스트 실행

위의 테스트 코드가 정상적으로 동작했다면, 아래와 같은 실행 화면을 확인할 수 있습니다. 테스트 케이스가 무사히 통과되면 좌측의 초록색 체크 버튼이 보입니다.
- 출력 화면

그럼 이제 위의 작성된 비즈니스 로직을 한번 살펴보도록 하겠습니다.
위에서 주석으로 표시한 given - when - then 은 BDD(Behavior Driven Development)라고 부르는 테스트 방식에서 사용되는 방법으로 아직 단위 테스트에 익숙하지 않은 사람들에게 매우 유용한 테스트 로직 작성 템플릿입니다. 아래에서 좀 더 자세히 학습할 예정이지만, 각각 입력 데이터, 실행 동작, 그리고 결과 검증을 나타냅니다.

이제 이러한 기본적인 이해를 가지고 우리가 앞서 작성한 빈 조회와 관련된 테스트 코드를 좀 더 살펴보겠습니다.
(1) given: 입력 데이터
- 테스트에 필요한 초기화 값 또는 입력 데이터를 의미합니다.
- 위의 예제의 경우, 빈 조회 테스트에 필요한 초기화 세팅은 AppConfigurer 클래스를 구성 정보로 하는 스프링 컨테이너를 생성하는 것입니다.
(2) when: 실행 동작
- 테스트할 실행 동작을 지정합니다. 일반적으로 단위 테스트에서는 메서드 호출을 통해 테스트를 진행하므로 한 두줄 정도로 작성이 끝납니다.
- 빈 조회 테스트에서 실행할 동작은 getBean() 메서드를 사용하여 빈을 불러오는 것입니다.
(3) then: 결과 검증
- 테스트의 결과를 최종적으로 검증하는 단계입니다.
- 일반적으로 테스트 결과 예상되는 기대값(expected)과 실제 실행 결과의 값을 비교하여 테스트를 검증합니다.
- 주로 JUnit 또는 AssertJ 라이브러리에서 제공하는 Assertions 클래스의 기능들을 필요에 따라 사용하여 검증을 진행합니다.
- 위의 코드는 AssertJ 라이브러리의 Assertions 클래스의 메서드인 assertThat()을 사용한 검증 방법을 보여주고 있습니다.
- AssertJ는 메서드 체이닝(method chaining)을 지원하기 때문에 스트림과 유사하게 여러 메서드들을 연속하여 호출하여 간편하게 사용이 가능합니다.
- AssertJ에서 모든 테스트코드는 assertThat()을 사용하고, 테스트를 실행할 대상을 파라미터로 전달하여 호출합니다. 호출의 결과로 ObjectAssert 타입의 인스턴스를 반환하는데, 이를 사용하여 isInstanceOf() , isSameAs() , isNotNull() , isNotEmpty() 등 다양한 검증을 편리하게 실행할 수 있습니다.
- 우리가 작성한 코드를 해석해 보면, 먼저 Assertions.assertThat() 메서드에 테스트를 실행할 참조변수 discountPolicy를 전달인자로 전달하고, 메서드 체이닝을 사용하여 isInstanceOf() 메서드를 사용하고 있습니다. isInstanceOf() 메서드는 대상 타이 주어진 유형의 인스턴스인지 검증할 때에 사용합니다. 자바의 instanceOf() 메서드와 유사하다고 할 수 있습니다.
위의 간단한 예제를 통해, JUnit으로 작성하는 테스트 코드의 기본 구조와 given - when - then을 사용한 기본적인 테스트 로직 작성법에 대해 알아보았습니다.
아직 끝나지 않았습니다.
사실 좋은 테스트 케이스를 작성한다는 것은 테스트가 무사히 통과하는 것을 눈으로 확인하는 데 그치지 않습니다. 우리가 작성한 테스트 로직이 의도대로 잘 동작하는 것도 중요하지만, 그 반대의 경우 통과되지 않아야 하는 테스트가 통과되지 않는 것을 확인하는 것도 매우 중요합니다.
위의 테스트 코드 로직을 조금 수정해서, cart 객체가 아닌 다른 객체가 들어오는 경우 테스트 코드는 정상적으로 통과되어서는 안 됩니다.
과연 정말 그런지 확인해 보겠습니다.
- MainTest 클래스 - 테스트 실패 검증
package com.springboot.v2;
import com.springboot.v2.discount.DiscountPolicy;
import org.assertj.core.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import static org.junit.jupiter.api.Assertions.*;
class KioskApplicationTest {
// 스프링 컨테이너 생성
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// 빈 조회 테스트케이스
@Test
void findBean() {
// (1) given => 초기화 또는 테스트에 필요한 입력 데이터
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// (2) when => 테스트 할 동작
Printer printer = applicationContext.getBean("printer", Printer.class);
// (3) then => 검증
Assertions.assertThat(printer).isInstanceOf(DiscountPolicy.class);
}
}
위와 같이 조회하는 빈을 printer 인스턴스로 변경한 후에 다시 테스트 케이스를 동작시켜 보겠습니다.
- 출력 화면

우리가 예상한 대로, 테스트 케이스가 정상적으로 통과되지 않은 것을 확인할 수 있습니다. 오류 메시지를 보면 스프링 프레임워크가 어떤 문제가 발생해서 테스트 케이스가 정상적으로 동작하지 않았는 지 친절하게 알려주고 있습니다.
심화 학습 자료
JUnit과 AssertJ에서 제공하는 API들에 대해 좀 더 자세히 공부하고 싶다면, 아래 심화 학습 자료를 참고해 주세요.
JUnit 5 tutorial - Learn how to write unit tests
Assertions - assertj-core 3.24.2 javadoc
스프링 컨테이너 = 싱글톤 컨테이너
이번 챕터에서는 앞에서 간략하게 언급하고 지나갔던 스프링의 싱글톤 패턴(Singleton Pattern)에 대해 좀 더 알아보도록 하겠습니다.
싱글톤 패턴
사실 싱글톤 패턴에 대한 기본적인 내용은 앞에서 이미 모두 배웠습니다.
잠시 코드를 다시 살펴볼까요?
- AppConfig 클래스
@Configuration
public class AppConfig {
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
@Bean
public MenuItem[] menuItems() {
return new MenuItem[]{
new MenuItem("김밥", 1500),
new MenuItem("계란 김밥", 2000),
new MenuItem("충무 김밥", 8000),
new MenuItem("치즈 김밥", 4000),
new MenuItem("참치 김밥", 4500),
new MenuItem("돈까스 김밥", 5000),
new MenuItem("떡볶이", 5000),
new MenuItem("라볶이", 6000),
new MenuItem("쫄면", 6500),
new MenuItem("우동", 4500)
};
}
@Bean
public DisplayPrinter printer() {
return new DisplayPrinter();
}
@Bean
public Kiosk kiosk(MenuItem[] menuItems, DisplayPrinter printer, DiscountPolicy discountPolicy) {
return new Kiosk(menuItems, printer, discountPolicy);
}
}
싱글톤 패턴은 이처럼 특정 클래스의 인스턴스가 단 하나만 생성되도록 보장하는 디자인 패턴을 의미합니다. 만약 여러 개의 동시다발적인 고객 요청을 처리해야 하는 웹 애플리케이션에서 요청이 있을 때마다 new 연산자를 사용하여 객체를 생성해야 한다면, 매번 이를 위한 메모리 영역을 할당받아야 하는데 이것은 결과적으로 큰 메모리 낭비를 초래할 수 있습니다.
이런 경우 싱글톤 패턴을 구현하여, 최초에 단 하나의 객체를 생성해 두고 요청이 돌아올 때마다 같은 객체를 공유하는 방법으로 메모리 낭비를 최소화할 수 있습니다.
앞에서 배웠던 테스트 코드를 작성하여 다시 한번 확인해 보겠습니다.
- SingletonTest 클래스 생성
위의 test 디렉토리의 v2 패키지 아래 SingletonTest 클래스를 생성합니다.
- WithoutSingletonTest 클래스
package com.springboot.v2.discount;
import org.assertj.core.api.Assertions;
import org.junit.jupiter.api.Test;
class WithoutSingletonTest {
// 싱글톤 구현 X
@Test
void runWithoutSingleton() {
TestConfig testConfig = new TestConfig();
// productRepository 객체 생성
DiscountPolicy discountPolicy = testConfig.getDiscountPolicy();
DiscountPolicy discountPolicy2 = testConfig.getDiscountPolicy();
// 출력
System.out.println("discountPolicy = " + discountPolicy);
System.out.println("discountPolicy2 = " + discountPolicy2);
// 생성한 두 개의 객체가 다른 참조값을 가지고 있는지 검증
Assertions.assertThat(discountPolicy).isNotSameAs(discountPolicy2);
}
// 테스트를 위한 TestConfig 클래스
static class TestConfig {
public DiscountPolicy getDiscountPolicy() {
return new FixedAmountDiscountPolicy(100);
}
}
}먼저 static 키워드를 사용하여 테스트용 TestConfig 클래스를 정의하고, ProductRepository 객체 인스턴스를 반환하는 메서드를 정의했습니다. 다음으로, runWithoutSingleton 메서드 안에 TestConfig 인스턴스를 생성한 후에 productRepository() 메서드를 두 번 호출하고 출력하여 각각 다른 값이 출력되는지 확인합니다.
- 출력 화면

사실 println() 메서드를 사용한 출력 부분은 테스트 코드 작성법을 배운 이 시점에서 생략이 가능하지만, 학습 초반인만큼 눈으로 직접 확인해 보기 위한 목적으로 추가되었습니다. 이어지는 테스트 코드들에서는 크게 필요하지 않다면 생략될 예정이니 공부를 하면서 필요하다고 생각되면 직접 추가해서 각각의 값을 확인해 보시기를 권장드립니다.
자, 이제 그러면 다시 싱글톤을 구현하여 테스트 코드를 아래와 같이 작성해 봅시다.
- SingletonTest 클래스
package com.codestates.burgerqueenspring.singleton;
import com.codestates.burgerqueenspring.product.ProductRepository;
import org.assertj.core.api.Assertions;
import org.junit.jupiter.api.Test;
public class SingletonTest {
// 싱글톤 구현 O
@Test
void runWithSingleton() {
TestConfig2 testConfig2 = new TestConfig2();
// productRepository 객체 생성
ProductRepository productRepository = testConfig2.productRepository();
ProductRepository productRepository2 = testConfig2.productRepository();
// 생성한 두 개의 객체가 같은 참조값을 가지고 있는지 검증
Assertions.assertThat(productRepository).isSameAs(productRepository2);
}
// 테스트를 위한 TestConfig2 클래스
static class TestConfig2 {
private final ProductRepository productRepository = new ProductRepository();
private TestConfig2(){}
public ProductRepository productRepository() {
return productRepository;
}
}
}
싱글톤을 적용하여 작성한 테스트 코드입니다. 반복되는 내용이니 자세한 설명은 생략하도록 하겠습니다.
이처럼 싱글톤 패턴을 사용하면 반복적으로 사용되는 객체를 매번 새롭게 생성하지 않고 하나의 객체를 공유하여 메모리 낭비를 최소화할 수 있습니다.
하지만, 이러한 장점에도 불구하고, 위에서 우리가 구현한 것과 같은 싱글톤 패턴은 꼭 필요한 상황이 아니라면 사용을 지양하는 것이 좋습니다.
- SingletonTest 클래스
public class SingletonTest {
// 싱글톤 구현 O
@Test
void runWithSingleton() {
TestConfig2 testConfig2 = new TestConfig2();
--- 생략 ---
}
}
가장 큰 이유는 위의 코드에서 확인할 수 있는 것처럼, 우리가 지금까지 객체지향적인 코드 설계를 이야기하면서 그토록 피하고 싶었던 구현 객체에 직접적으로 의존하는 상황, 즉 객체 간 높은 결합도가 야기되기 때문입니다.
앞서 반복해서 확인할 수 있었던 것처럼, 객체 간 결합도가 높아지면 유지보수가 어렵고 테스트를 원활하게 진행할 수 없는 문제점이 발생합니다. 또한, private 생성자를 사용했기 때문에 하위 클래스로 확장할 수 없습니다. 결론적으로, 우리가 객체지향 프로그래밍을 통해 달성하고자 하는 변경과 확장에 유연한 코드를 작성하는 것이 굉장히 어려워집니다.
그렇다면 방법이 없는 걸까요?
그렇지 않습니다. 역시 우리의 스프링 프레임워크는 항상 답을 가지고 있습니다. 이어지는 내용을 통해 스프링이 어떻게 이러한 싱글톤의 한계를 극복하고 객체들을 싱글톤 패턴으로 관리할 수 있는지 알아보도록 하겠습니다.
스프링 컨테이너와 싱글톤 패턴
결론적으로, 스프링 컨테이너는 위에서 우리가 작성한 싱글톤 패턴 코드, 즉 결합도가 높은 상태를 야기하는 코드를 직접적으로 작성하지 않아도 내부적으로 객체 인스턴스를 싱글톤으로 관리함으로 싱글톤 패턴이 가지는 모든 잠재적인 단점들을 효과적으로 극복할 수 있었습니다.
AppConfig 클래스 코드를 다시 살펴보겠습니다.
- AppConfig 클래스
@Configuration
public class AppConfig {
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100);
정말 싱글톤으로 객체들을 관리하고 있는지 테스트 코드를 통해 확인해 보겠습니다. 지금까지 작성했던 테스트 코스와 마찬가지로 test/com/springboot/v2/ 패키지 안에 AppConfigTest 클래스를 생성해 봅시다.
- AppConfigTest 클래스 생성
package com.codestates.burgerqueenspring.singleton;
import com.codestates.burgerqueenspring.AppConfigurer;
import com.codestates.burgerqueenspring.Cart;
import org.assertj.core.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class CartSingletonTest {
@Test
void checkCartSingleton() {
// given - 컨테이너 생성
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfigurer.class);
// when - 빈 조회
Cart cart = applicationContext.getBean("cart", Cart.class);
Cart cart2 = applicationContext.getBean("cart", Cart.class);
// 출력
System.out.println("cart = " + cart);
System.out.println("cart2 = " + cart2);
// then - 검증
Assertions.assertThat(cart).isSameAs(cart2);
}
}
위의 테스트 코드를 작성하고, 프로그램을 동작시켜 보면 아래와 같은 실행 화면을 확인할 수 있습니다.
- 출력 화면

이로써 스프링 컨테이너가 내부적으로 객체들을 싱글톤으로 관리한다는 사실이 확실하게 확인되었습니다. 결론적으로, 스프링 컨테이너는 싱글톤 컨테이너 역할을 수행합니다. 그리고 이렇게 싱글톤으로 객체를 생성 및 관리하는 기능을 싱글톤 레지스트리(Singleton Registry)라 부릅니다.
어떻게 스프링 컨테이너는 싱글톤 레지스트리를 구현가능할까요?
복잡하고 어려운 내용들이 있지만, 결론적으로 설명하면 스프링은 CGLIB라는 바이트코드 조작 라이브러리를 사용하여 싱글톤 레지스트리를 가능하게 합니다. 내부적인 동작을 대략적으로 코드로 표현해 보면 다음과 같습니다.
- CGLIB 내부 동작 의사 코드
@Bean
public Kiosk kiosk() {
if(Kiosk 가 이미 스프링 컨테이너에 있는 경우) {
return 이미 있는 객체를 찾아서 반환
} else {
새로운 객체를 생성하고 스프링 컨테이너에 등록
return 생성한 객체 반환
}
}
위의 코드와 관련된 구체적인 내용들까지 모두 이해할 필요는 없습니다.
지금 단계에서는 스프링 컨테이너가 싱글톤 레지스트리 기능을 가지고 있는 싱글톤 컨테이너이기 때문에 그 안에서 생성되고 관리되는 객체들이 싱글톤으로 관리된다는 핵심적인 사실만 기억해도 충분합니다.
이제 이어지는 챕터에서는 스프링 컨테이너가 관리하는 빈 객체들의 생명주기와 범위에 대한 내용을 학습해 보겠습니다.
빈 생명주기와 범위
스프링 컨테이너는 크게 초기화와 종료라는 생명 주기(life-cycle)를 가지고 있습니다.
여기서 생명 주기라는 단어가 조금 생소할 수 있는데, 이름 그대로 스프링 컨테이너의 탄생과 죽음에 대한 것입니다. 마치 아기가 태어나 노화의 과정을 거쳐 죽음에 이르는 것과 같습니다.
아래의 코드를 통해 좀 더 자세한 내용을 살펴보도록 하겠습니다.
- KioskApplication 실행 클래스
@Override
public void run(String... args) {
// (1) 컨테이너 초기화
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
// (2) 컨테이너 사용
String[] beanDefinitionNames = applicationContext.getBeanDefinitionNames();
for (String beanDefinitionName : beanDefinitionNames) {
Object bean = applicationContext.getBean(beanDefinitionName);
System.out.println("beanName=" + beanDefinitionName + " object=" + bean);
--- 생략 ---
// (3) 컨테이너 종료
applicationContext.close();
}
(1) 컨테이너 초기화
AnnotationConfigApplicationContext를 통해 객체를 생성함과 동시에 스프링 컨테이너를 초기화합니다. 이때 스프링 컨테이너는 앞에서 설명한 것처럼 구성 정보를 기반으로 빈 객체를 생성하고, 각 의존 관계를 연결하는 작업을 수행합니다.
(2) 컨테이너 사용
스프링 컨테이너의 초기화 작업이 완료되는, 이제 스프링 컨테이너의 관리하에 있는 빈 객체들을 조회하여 사용할 수 있습니다. 이때 주로 getBean() 메서드를 사용하여 빈을 조회합니다.
(3) 컨테이너 종료
컨테이너 사용이 모두 끝나면 컨테이너를 close() 메서드를 통해 종료시킬 수 있습니다.
참고로, close() 메서드는 AbstractApplicationContext 클래스에 정의되어 있는데, 이것을 AnnotationConfigApplicationContext 클래스가 상속하여 사용하는 것입니다.
정리하면, 스프링 컨테이너는 (1) 빈 객체의 생성, 의존 관계 주입, 초기화 과정을 수행하는 컨테이너 초기화 단계와 (2) 빈 객체의 소멸을 의미하는 컨테이너 종료로 구분할 수 있습니다. 너무나 당연하게도 스프링 컨테이너의 생성과 종료는 그 안에서 관리되고 있는 빈 객체들의 탄생과 죽음과 그 궤를 같이 합니다.
아래 내용을 통해 좀 더 알아보겠습니다.
빈 객체 생명주기
스프링 컨테이너가 관리하는 빈 객체의 생명주기는 다음과 같습니다.
- 빈 객체 생명 주기

- (1) 빈 객체 생성 → (2) 의존 관계 주입 → (3) 초기화 → (4) 소멸
얼핏 보아도, 앞에서 본 스프링 컨테이너의 생명 주기와 거의 비슷하다는 당연한 사실을 다시 확인할 수 있습니다.
간략하게 설명해 보면, 스프링 컨테이너가 초기화 될 때 스프링 컨테이너는 (1) 가장 먼저 빈 객체들을 생성하고, 이 (2) 객체들 간 의존 관계를 설정합니다. 이렇게 모든 의존 관계 설정이 모두 완료되면 내부적으로 지정한 메서드를 호출하여 (3) 빈 객체의 초기화를 진행합니다.
마지막으로, 빈 객체들의 사용이 마무리되고 스프링 컨테이너가 종료되면, 스프링 컨테이너는 지정한 메서드를 호출하여 (4) 빈 객체들의 소멸을 처리합니다.

그렇다면 왜 스프링 컨테이너와 빈 객체의 생명 주기에 대해 이해해야 할까요?
그 이유는 이러한 과정을 바르게 이해해야 우리의 어떤 필요에 따라 필요한 기능 구현이 가능하기 때문입니다. 예를 들면, 데이터베이스의 커넥션 풀이나 채팅 클라이언트의 기능을 구현할 때가 그런 경우에 해당합니다.
초기화의 단계에서, 커넥션 풀을 위한 빈 객체는 데이터베이스를 연결하며, 채팅 클라이언트는 서버와의 연결을 진행합니다. 반대로, 컨테이너가 종료되어 빈 객체가 소멸되는 시점에서는 데이터베이스 또는 서버와의 연결을 적절하게 끊어낼 수 있어야 합니다.
따라서, 생명 주기에 대한 이러한 기본적인 이해가 없다면 앞서 언급한 기능들을 적절한 시점에 바르게 수행하기가 매우 어려워질 것입니다.
그런데, 생명 주기에 대한 이해가 있더라도 그 적절한 시점을 어떻게 알 수 있을까요?
결론적으로, 스프링은 의존 관계 설정이 완료된 시점과 스프링 컨테이너의 종료 직전의 시점에 지정된 메서드를 호출하여 개발자로 각각의 시점에 필요한 작업을 수행할 수 있도록 지원합니다.
스프링은 다음의 두 가지 인터페이스에 이 메서드를 정의하고 있습니다.
- InitializingBean & DisposableBean 인터페이스
// 초기화 단계에서 실행되는 메서드
public interface InitializingBean {
void afterPropertiesSet() throws Exception;
}
// 소멸 단계에서 실행되는 메서드
public interface DisposableBean {
void destroy() throws Exception;
}
만약, 빈 객체가 InitialzingBean과 DisposableBean 인터페이스를 구현하면 스프링 컨테이너는 초기화 과정과 소멸 과정에서 각각 빈 객체의 afterPropertiesSet() 메서드와 destroy() 메서드를 실행합니다.
따라서 개발자가 이 시점에 특정한 작업을 수행하고 싶다면 메서드 오버라이딩을 통해 적절한 기능을 구현할 수 있습니다.
코드를 통해 확인해 보겠습니다.
- lifecycle 패키지 아래 클래스 추가

먼저 프로젝트 디렉토리에 lifecycle 이라는 이름의 새로운 패키지를 추가한 후에 아래의 클래스들을 작성해 보겠습니다.
- TestClient 클래스 - InitializingBean과 DisposableBean 인터페이스 구현체
public class TestClient implements InitializingBean, DisposableBean {
private String url;
public TestClient(String url) {
System.out.println("생성자 호출.");
this.url = url;
}
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("초기화 메서드 실행.");
}
public void connect() {
System.out.println("클라이언트를 " + url + "로 연결.");
}
@Override
public void destroy() throws Exception {
System.out.println("종료 메서드 실행.");
}
}
먼저 InitializingBean과 DisposableBean 인터페이스를 구현한 TestClient라는 이름의 클래스를 만들고 위와 같이 코드를 작성합니다. TestClient는 생성자로 받은 url 주소를 연결하는 역할을 하는 클래스입니다.
- ClientConfig 클래스
@Configuration
public class ClientConfig {
@Bean
public TestClient testClient() {
// 생성자로 url 주소값 전달
TestClient testClient = new TestClient("www.naver.com");
return testClient;
}
}
다음으로 @Configuration과 @Bean 애너테이션을 사용하여 스프링 컨테이너에 TestClient 빈 객체를 수동으로 등록해 주는 빈 구성 정보 클래스를 정의합니다.
- ClientMain 클래스
public class ClientMain {
public static void main(String[] args) {
// 컨테이너 생성
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(ClientConfig.class);
// 컨테이너 사용
TestClient testClient = applicationContext.getBean("testClient", TestClient.class);
testClient.connect();
// 컨테이너 종료
applicationContext.close();
}
}
이제 ClientMain 실행 클래스를 생성하여 우리가 정의한 구성정보를 바탕으로 스프링 컨테이너를 생성하고, testClient 빈 객체를 가져와 사용하고, 모든 작업이 종료된 후에는 컨테이너를 종료하도록 해 보겠습니다.
실행 후에는 아래와 같은 출력 결과를 확인할 수 있습니다.
- 출력 화면

콘솔에 출력된 결과를 확인해 보면, 가장 먼저 생성자가 호출되고 있습니다. 이 단계에서 빈 객체의 생성과 의존 관계 주입이 이뤄집니다.
이렇게 의존 관계의 주입까지 모두 이뤄지면, 초기화 과정에서 호출되는 메서드인 afterPropertiesSet()가 호출됩니다. 이 메서드를 통해 초기화 작업까지 모두 마치면, 이제 앞에서 우리가 해왔던 방식대로 스프링 컨테이너의 빈 객체들을 불러 사용할 수 있습니다. 마지막으로, 로그를 통해 사용이 모두 끝나고 컨테이너가 종료되면 destroy() 메서드가 호출된다는 사실을 알 수 있습니다.
하지만, InitializingBean 인터페이스와 DisposableBean 인터페이스를 사용하는 것은 몇 가지 한계를 가지고 있습니다. 이들 인터페이스는 스프링 전용 인터페이스이기 때문에, 초기화와 소멸 메서드의 이름을 개발자가 임의로 변경할 수 없으며, 직접 구현한 클래스가 아닌 외부에서 받은 라이브러리나 클래스 등에 두 가지 인터페이스를 적용할 수 있는 방법이 없습니다.
이러한 문제를 극복하기 위해, 구성 정보 클래스에 initMethod 속성과 destoryMethod 속성을 사용하여 위의 문제를 해소할 수 있습니다.
기존에 우리가 작성했던 클래스를 아래와 같이 조금 수정해 보겠습니다.
- TestClient 클래스
public class TestClient {
private String url;
public TestClient(String url) {
System.out.println("생성자 호출.");
this.url = url;
}
public void init() {
System.out.println("init() 초기화 메서드 실행.");
}
public void connect() {
System.out.println("클라이언트를 " + url + "로 연결.");
}
public void close() {
System.out.println("close() 종료 메서드 실행.");
}
}
먼저, TestClient 클래스에서 implements 키워드를 사용하여 인터페이스를 구현하는 부분을 삭제합니다.
다음으로, 기존에 메서드 오버라이딩을 사용하여 정의한 afterPropertiesSet()과 destroy() 메서드를 제거하고, 그 자리를 임의로 만든 init()과 close() 메서드로 대체했습니다.
- ClientConfig 클래스
@Configuration
public class ClientConfig {
@Bean(initMethod = "init", destroyMethod = "close")
public TestClient testClient() {
TestClient testClient = new TestClient("www.naver.com");
return testClient;
}
}
ClientConfig 클래스의 @Bean 태그에서 iniMethod 속성과 destroyMethod 속성을 각각 init과 close 메서드로 지정해 줍니다. 모든 작업이 완료되었다면, 다시 프로그램을 실행해 봅니다.
출력 결과를 확인해 보면, 우리가 의도한 대로 init() 메서드와 close() 메서드가 각각 초기화와 소멸 과정에서 정상적으로 잘 호출이 되었음을 알 수 있습니다.
참고로 destroyMethod 속성은 디폴트값이 (inferred), 즉 추론되도록 등록이 되어있습니다.
이 추론 기능은 일반적으로 라이브러리 등에서 빈번하게 사용하는 close 또는 shutdown이라는 이름의 메서드를 자동으로 호출해 줍니다. 따라서 위의 경우에도 destroyMethod 속성 값을 아예 빼고 다시 실행하더라도 같은 close 메서드가 호출됩니다. 만약 이 기능을 사용하고 싶지 않은 경우에는 destroyMethod=””처럼 빈 공백을 지정하면 됩니다.
결론적으로, 이렇게 @Bean 태그의 속성 값들을 활용하면, 메서드명을 자유롭게 수정할 수 있고, 코드를 수정할 수 없는 외부 라이브러리 등을 우리의 의도에 맞게 적절하게 변경하여 사용할 수 있습니다.
마지막으로 최신 스프링에서 가장 권장하는 방법이자 가장 간편하고 강력한 방법을 살펴보겠습니다. 바로 @PostConstruct와 @PreDestory 애너테이션을 활용하는 것입니다.
바로 코드로 확인해 보겠습니다.
- TestClient 클래스
public class TestClient {
private String url;
public TestClient(String url) {
System.out.println("생성자 호출.");
this.url = url;
}
@PostConstruct
public void init() {
System.out.println("init() 초기화 메서드 실행.");
}
public void connect() {
System.out.println("클라이언트를 " + url + "로 연결.");
}
@PreDestroy
public void close() {
System.out.println("close() 종료 메서드 실행.");
}
}
코드 작성 끝입니다. 매우 간편하죠?
기존에 ClientConfig 클래스에 작성했던 부분을 지우고, 이전과 동일하게 프로그램을 실행해 보면 정확하게 동일한 값을 출력한다는 사실을 확인할 수 있습니다.
이렇게 두 가지 애너테이션을 사용하는 것은 간편하고 컴포넌트 스캔 방식과도 잘 어울리는 방법이기 때문에 최신 스프링에서는 @PostConstruct와 @PreDestory을 사용하여 초기화 메서드와 종료 메서드를 호출하는 것을 권장하고 있습니다. 유일한 단점은 수정이 어려운 외부 라이브러리 코드에 적용하기는 어렵다는 것인데, 그 경우에는 유연하게 앞에서 봤었던 @Bean 태그 속성을 활용할 수 있습니다.
빈 객체의 관리 범위
지금까지 우리는 스프링 컨테이너에 대해 학습하면서, 스프링 컨테이너는 싱글톤 레지스트리 기능을 가진 싱글톤 컨테이너이며, 그 안에서 관리되는 스프링 빈도 스프링 컨테이너의 생성과 종료와 함께 운명을 같이 한다는 사실을 배웠습니다.
사실 이렇게 스프링 빈이 스프링 컨테이너와 운명을 같이하게 된 것은 해당 빈 객체가 별도의 설정이 없는 경우 싱글톤 범위(scope)를 가지기 때문입니다. 여기서 빈 객체의 스코프란 이름 그대로 빈 객체가 존재할 수 있는 범위를 의미합니다.
지금까지 우리는 가장 기본적이고 가장 넓은 범위를 가지는 싱글톤 범위를 중심으로 살펴봤지만, 빈 객체의 관리 범위에는 싱글톤 외에도 프로토타입(prototype), 세션(session), 리퀘스트(request) 등의 범위가 존재합니다.

사실 사용 빈도 측면에 있어서는 대부분 싱글톤 범위를 사용하기 때문에 그 외의 범위들은 사용 빈도가 상대적으로 낮다고 할 수 있지만, 알고 있으면 추후에 필요할 때 유용하게 사용할 수 있습니다.
여기서는 프로토타입 범위를 예시로 설명하겠습니다.
테스트 케이스를 통해 확인하면 더 편리하기 때문에, 먼저 test 디렉토리의 springboot/v2 패키지에 새롭게 scope라는 이름의 패키지를 생성하고 아래와 같이 ScopeTest 테스트 클래스를 생성해 보겠습니다.
다음으로, ScopeTest 클래스에 다음과 같이 코드를 작성합니다.
- ScopeTest 클래스
public class ScopeTest {
@Test
public void scopeTest() {
// 컨테이너 생성
AnnotationConfigApplicationContext annotationConfigApplicationContext = new AnnotationConfigApplicationContext(TestBean.class);
// 컨테이너 사용
TestBean bean = annotationConfigApplicationContext.getBean(TestBean.class);
TestBean bean2 = annotationConfigApplicationContext.getBean(TestBean.class);
System.out.println("bean = " + bean);
System.out.println("bean2 = " + bean2);
// 검증
Assertions.assertThat(bean).isSameAs(bean2);
// 컨테이너 종료
annotationConfigApplicationContext.close();
}
static class TestBean {
// 초기화 메서드 설정
@PostConstruct
public void init() {
System.out.println("init() 초기화 메서드 실행.");
}
// 종료 메서드 설정
@PreDestroy
public void close() {
System.out.println("close() 종료 메서드 실행.");
}
}
}
먼저 static으로 선언된 테스트용 TestBean 클래스를 생성하고 그 안에 초기화 메서드와 종료 메서드를 각각 선언했습니다.
다음으로, TestBean 클래스를 구성 정보로 하는 스프링 컨테이너를 생성한 다음, getBean() 메서드를 통해 빈을 두 번 조회하여 동일한 객체를 반환하는지 출력하고 Assertions 클래스의 isSameAs() 메서드를 통해 다시 검증했습니다.
마지막으로 이렇게 컨테이너 사용이 끝나면 close() 메서드를 통해 컨테이너를 종료하도록 코드를 작성합니다.
코드를 모두 작성했다면, 이제 테스트 케이스를 실행하여 그 결과를 확인해 봅시다.
- 출력 화면

결과는 지금까지 우리가 확인했던 것과 크게 다르지 않습니다.
스프링 컨테이너가 생성되면 빈 객체 생성과 의존 관계 주입이 이뤄지고, 주입이 모두 끝난 시점에 초기화 메서드가 실행됩니다.
다음으로 우리가 코드로 작성한 내용을 통해, 두 번 조회한 빈 객체가 동일한 객체임을 확인하고, isSameAs() 메서드를 통해 다시 검증했습니다. 마지막으로 컨테이너가 종료되면서, 종료 메서드가 실행되는 부분을 눈으로 확인할 수 있습니다.
이제 그럼 스프링 컨테이너의 빈 객체의 관리 범위를 싱글톤이 아닌 프로토타입으로 변경하여 같은 코드를 실행해 보겠습니다. 관리 범위를 프로토타입으로 두면, 스프링 컨테이너는 프로토타입 빈의 생성, 의존성 주입, 초기화 단계까지만 관여하고 그 이후에는 더 이상 관여하지 않습니다.
코드를 통해 어떤 의미인지 확인해 보겠습니다.
- ScopeTest 클래스
public class ScopeTest {
@Test
public void scopeTest() {
// 컨테이너 생성
AnnotationConfigApplicationContext annotationConfigApplicationContext = new AnnotationConfigApplicationContext(TestBean.class);
// 컨테이너 사용
TestBean bean = annotationConfigApplicationContext.getBean(TestBean.class);
TestBean bean2 = annotationConfigApplicationContext.getBean(TestBean.class);
System.out.println("bean = " + bean);
System.out.println("bean2 = " + bean2);
// 검증
Assertions.assertThat(bean).isSameAs(bean2);
// 컨테이너 종료
annotationConfigApplicationContext.close();
}
@Scope("prototype")
static class TestBean {
// 초기화 메서드 설정
@PostConstruct
public void init() {
System.out.println("init() 초기화 메서드 실행.");
}
// 종료 메서드 설정
@PreDestroy
public void close() {
System.out.println("close() 종료 메서드 실행.");
}
}
}
테스트 방법은 간단합니다.
좀 전에 작성했었던 코드의 TestBean 클래스에 위와 같이 @Scope("prototype") 애너테이션을 붙여 해당 클래스의 인스턴스의 관리 범위를 프로토타입으로 할 것임을 표시해주기만 하면 됩니다.
이제 다시 테스트 코드를 실행시켜 결과를 확인해 보겠습니다.
- 출력 화면

결과를 확인해 보면, 이전과 달리 테스트가 통과되지 않고, 출력 화면에 초기화 메서드가 두 번 출력되면서 각기 다른 빈이 조회되는 것을 확인할 수 있습니다.
지금까지 우리가 빈을 조회할 때에는 앞선 경우처럼, 빈의 관리 범위가 디폴트인 싱글톤이었기 때문에 빈 조회 시 같은 객체가 반환되는 반면, 이번에 작성한 코드의 경우 빈의 관리 범위가 프로토토입이기 때문에 빈을 조회했을 때 각기 다른 객체가 반환되면서 이전의 테스트가 더 이상 통과되지 않는 것을 확인할 수 있습니다.
또한, 앞서 언급했던 것처럼 프로토타입 범위는 싱글톤 범위와 다르게 빈의 생성, 의존성 주입, 초기화까지만 스프링 컨테이너가 관여하게 됨으로 초기화 메서드만 두 번 호출될 뿐 종료 메서드는 더 이상 호출되지 않는다는 사실도 눈여겨봐야 합니다.
다른 주제들과 유사하게, 빈 생명주기와 범위와 관련된 내용들도 파고들면 매우 복잡한 내용들을 포함하고 있습니다. 따라서, 지금 단계에서는 너무 깊은 내용보다는 스프링 컨테이너의 빈 객체에 대한 범위를 각기 다르게 설정할 수 있다는 사실 정도만 기억해 두었다가, 추후에 필요에 따라 필요한 내용들을 검색하여, 적절하게 활용하시기를 권장드립니다.
심화 학습 자료
Bean life cycle in Java Spring - GeeksforGeeks
컴포넌트 스캔과 의존성 자동 주입
지금까지 의존성 주입을 할 때 우리는 AppConfigurer 클래스와 같은 외부의 구성 정보를 직접 수동으로 입력하여 스프링 컨테이너가 필요한 모든 객체(빈)들을 생성하고 의존 관계를 설정할 수 있도록 하였습니다.
- @Configuration과 @Bean을 사용한 수동 주입 방식
package com.springboot.v2;
import com.springboot.v2.discount.DiscountPolicy;
import com.springboot.v2.discount.FixedAmountDiscountPolicy;
import com.springboot.v2.helper.DisplayPrinter;
import com.springboot.v2.helper.Printer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AppConfig {
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
@Bean
public MenuItem[] menuItems() {
return new MenuItem[]{
new MenuItem("김밥", 1500),
new MenuItem("계란 김밥", 2000),
new MenuItem("충무 김밥", 8000),
new MenuItem("치즈 김밥", 4000),
new MenuItem("참치 김밥", 4500),
new MenuItem("돈까스 김밥", 5000),
new MenuItem("떡볶이", 5000),
new MenuItem("라볶이", 6000),
new MenuItem("쫄면", 6500),
new MenuItem("우동", 4500)
};
}
@Bean
public DisplayPrinter printer() {
return new DisplayPrinter();
}
@Bean
public Kiosk kiosk(MenuItem[] menuItems, DisplayPrinter printer, DiscountPolicy discountPolicy) {
return new Kiosk(menuItems, printer, discountPolicy);
}
}
이렇게 수동으로 개발자가 직접 의존 관계를 설정해 주는 일은 분명 직관적이고 유용하지만, 또 다른 한편에서 굉장히 번거롭기도 합니다. 지금은 등록해야 할 스프링의 빈의 수가 적아서 큰 문제가 없지만, 만약에 그 수가 수 십, 수 백 개에 이른다면 어떨까요?
이러한 번거로움을 해결하기 위해, 스프링 프레임워크는 수동으로 클래스 구성 정보를 일일이 작성하지 않고, 자동으로 스프링 빈을 등록하는 컴포넌트 스캔(Component Scan) 기능을 지원합니다.
더 나아가, 컴포넌트 스캔만으로는 앞에서 우리가 봤던 것과 같은 구체적인 의존 관계 설정이 불가능하기 때문에 @Autowired 애너테이션을 통해 빈을 자동으로 등록함과 동시에 의존 관계가 설정될 수 있도록 편리한 기능을 제공합니다.
길게 설명하기보다, 코드를 통해 어떻게 사용할 수 있는 것인지 확인해 보겠습니다.
package com.springboot.v3;
import com.springboot.v2.Kiosk;
import com.springboot.v2.helper.DisplayPrinter;
import com.springboot.v3.discount.DiscountPolicy;
import com.springboot.v3.discount.FixedAmountDiscountPolicy;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AppConfig {
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
@Bean
public MenuItem[] menuItems() {
return new MenuItem[]{
new MenuItem("김밥", 1500),
new MenuItem("계란 김밥", 2000),
new MenuItem("충무 김밥", 8000),
new MenuItem("치즈 김밥", 4000),
new MenuItem("참치 김밥", 4500),
new MenuItem("돈까스 김밥", 5000),
new MenuItem("떡볶이", 5000),
new MenuItem("라볶이", 6000),
new MenuItem("쫄면", 6500),
new MenuItem("우동", 4500)
};
}
// @Bean
// public DisplayPrinter printer() {
// return new DisplayPrinter();
// }
//
// @Bean
// public com.springboot.v2.Kiosk kiosk(com.springboot.v2.MenuItem[] menuItems, DisplayPrinter printer, com.springboot.v2.discount.DiscountPolicy discountPolicy) {
// return new Kiosk(menuItems, printer, discountPolicy);
// }
}
- AppConfig 클래스 - 수정
AppConfig 클래스에서 수동으로 데이터를 넣을 필요가 없는 부분은, 모두 메서드를 삭제합니다.
우리가 익숙하게 봐왔던 공연 기획자의 모습과는 다르게 @Bean 애너테이션이 붙여진 메서드가 일부 사라졌습니다. 다만, @Configuration 애너테이션과 함께 새로운 @ComponentScan이라는 이름의 애너테이션이 클래스 레벨에 붙여져 있는 것을 확인할 수 있습니다.
- 변경된 ConsolePrint 클래스
package com.springboot.v3.helper;
import org.springframework.stereotype.Component;
@Component
public class ConsolePrint implements Printer {
@Override
public void print(String str) {
System.out.println(str);
}
}
- 변경된 Kiosk 클래스
package com.springboot.v3;
import com.springboot.v3.discount.DiscountPolicy;
import com.springboot.v3.helper.Printer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.Scanner;
@Component
public class Kiosk {
--- 생략 ---
이제 모든 기본적인 세팅이 완료되었습니다. 컴포넌트 스캔은 이름처럼 @Component 애너테이션이 붙은 클래스를 모두 스캔하여 자동으로 스프링 빈으로 등록합니다.
참고로, 별다른 설정이 없다면 @ComponentScan이 붙은 구성 정보 클래스의 패키지가 스캔의 시작 위치가 됩니다.
그렇다면 우리 코드의 컴포넌트 스캔 시작 지점은 어디일까요?
- AppConfig 클래스
@Configuration
@ComponentScan
public class AppConfig {
그렇습니다!
TestConfigurer 클래스의 패키지, 즉 v3 디렉토리 전체가 스캔의 대상이 됩니다.
따라서 구성 정보 클래스의 위치를 프로젝트 최상단에 두어 자동으로 디렉토리 전체가 스캔의 대상이 되도록 하는 방법이 일반적으로 널리 사용되는 방법입니다. 만약 범위를 변경하고 싶다면, @ComponentScan(basePackages = “”) 에서 “” 부분에 패키지 이름을 표시하는 방법으로 스캔의 범위 지정을 바꿀 수 있습니다.
자 그럼 지금부터 스캔의 대상이 되어야 하는 클래스에 @Component과 @Autowired 애너테이션을 사용하여 자동으로 스프링 빈 등록 및 의존 관계 설정이 되도록 순차적으로 작업해 보겠습니다.
그럼 어떤 클래스들이 스캔의 대상이 되어야 할까요?
답은 바로 우리가 설정 파일을 지웠던 AppConfig 클래스에 있습니다.
- AppConfig 클래스
package com.springboot.v3;
import com.springboot.v3.Kiosk;
import com.springboot.v3.helper.DisplayPrinter;
import com.springboot.v3.discount.DiscountPolicy;
import com.springboot.v3.discount.FixedAmountDiscountPolicy;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan
public class AppConfig {
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
@Bean
public MenuItem[] menuItems() {
return new MenuItem[]{
new MenuItem("김밥", 1500),
new MenuItem("계란 김밥", 2000),
new MenuItem("충무 김밥", 8000),
new MenuItem("치즈 김밥", 4000),
new MenuItem("참치 김밥", 4500),
new MenuItem("돈까스 김밥", 5000),
new MenuItem("떡볶이", 5000),
new MenuItem("라볶이", 6000),
new MenuItem("쫄면", 6500),
new MenuItem("우동", 4500)
};
}
// @Bean
// public DisplayPrinter printer() {
// return new DisplayPrinter();
// }
//
// @Bean
// public Kiosk kiosk(MenuItem[] menuItems, DisplayPrinter printer, DiscountPolicy discountPolicy) {
// return new Kiosk(menuItems, printer, discountPolicy);
// }
}
위의 코드를 확인해 보면, 기존에 애플리케이션을 정상적으로 실행하기 위해 의존관계를 설정해 준 객체 중, 2개의 객체의 설정정보가 비 활성화 되어있습니다.
Printer 인터페이스에서 사용할 객체를 선택해야 하고 ,Kiosk 객체가 생성되는 시점에서 사용할 객체들도 모두 컴포넌트 스캔이 되어야 합니다. 앞선 과정에서 두개의 클래스에 모두 @Component 애너테이션을 추가했습니다.
그럼 순차적으로 이들 클래스에 @Autowired 애너테이션을 사용하여 해당 클래스들의 의존관계를 연결해 주겠습니다.
- Kiosk 클래스
@Component
public class Kiosk {
private MenuItem[] menuItemArray;
private Printer printer;
private DiscountPolicy discountPolicy;
@Autowired
public Kiosk(MenuItem[] menuItemArray, Printer printer, DiscountPolicy discountPolicy) {
this.menuItemArray = menuItemArray;
this.printer = printer;
this.discountPolicy = discountPolicy;
}
--- 생략 ---
}
- KioskApplication 클래스
public class KioskApplication implements CommandLineRunner {
private Kiosk kiosk;
@Autowired
public KioskApplication(Kiosk kiosk) {
this.kiosk = kiosk;
}
--- 생략 ---
}
끝입니다. 정말 간단합니다.
단순하게 생성자에 @Autowired 애너테이션을 붙이면 스프링이 관리하고 있는 해당 타입의 객체가 자동으로 주입되어 의존 관계가 완성됩니다.
참고로 생성자가 단 하나만 존재하는 경우에는 @Autowired 애너테이션을 붙이지 않아도 자동으로 의존 관계가 연결이 됩니다.
또 한 가지 언급해야 할 부분은 앞에서 코드를 변경하지 않은 Discount 클래스입니다.
위의 코드를 확인해 보면 아시겠지만, Discount 클래스의 생성자 코드를 보면 객체들이 직접적으로 결합되어 있습니다. 계속 강조하는 부분이지만, 이렇게 new 키워드를 사용하여 직접적으로 결합되어 있는 코드는 객체지향적으로 결코 권장되는 방식이 아닙니다.
그럼에도 불구하고, 위와 같은 코드를 작성한 것은 학습상의 편의를 위해서 위한 것인데, 이것과 관련한 좀 더 자세한 내용은 이어지는 챕터에서 @Autowired 애너테이션에 대한 내용을 다루면서 함께 좀 더 알아보도록 하겠습니다.
자, 이제 컴포넌트 스캔을 위한 모든 준비 작업이 끝났습니다. 이제 Main 클래스를 실행해 봅니다.
마지막으로, @Component 애너테이션만 컴포넌트 스캔의 기본 타깃에 들어가는 것은 아닙니다.
의존 관계를 자바로 수동으로 설정할 때 사용했던 @Configuration 애너테이션, 그리고 곧이어 우리가 배울 MVC 패턴에서 주로 사용될 @Controller, @Service, @Repository 등의 애너테이션도 컴포넌트 스캔의 대상에 포함됩니다.
- Configuration 인터페이스

이것은 사실 위에서 언급한 애너테이션 안에 위의 그림과 같이 이미 @Component 애너테이션이 포함되어 있기 때문입니다. 따라서, 그 원리는 앞에서 배운 내용과 동일하다고 할 수 있습니다.
위에서 언급한 애너테이션에 대한 좀 더 자세한 내용들은 이어지는 섹션 3에서 스프링의 핵심 기술들과 함께 좀 더 자세히 배울 예정이니, 지금 단계에서는 이 정도만 이해하고 지나가셔도 충분합니다.
그럼 이제 다음 챕터로 넘어가 @Autowired 애너테이션에 대해 좀 더 알아보겠습니다.
@Autowired
이번 챕터에서는 앞에서 의존관계 자동 주입을 위해 사용되었던 @Autowired 애너테이션에 대해 좀 더 알아보도록 하겠습니다.
먼저 앞의 챕터에서 언급했던 AppConfig 클래스를 잠시 살펴보겠습니다.
- AppConfig 클래스
@Component
public class Discount {
private DiscountCondition[] discountConditions;
@Bean
public DiscountPolicy discountPolicy() {
return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
}
}
앞서 위의 코드를 언급하면서, 객체들이 직접적으로 결합되어 있기 때문에 객체지향적으로 좋은 코드 설계는 아니지만, 학습 상 편의를 위해 위와 같이 작성했다는 점을 설명한 바 있습니다.
잠시, 위에서 새로 추가한 생성자 부분을 주석 처리해서 원래의 코드로 한번 돌아가 문제를 확인해 보겠습니다.
- 변경 후 AppConfig 클래스
@Configuration
@ComponentScan
public class AppConfig {
// @Bean
// public DiscountPolicy discountPolicy() {
// return new FixedAmountDiscountPolicy(100); // 할인 금액을 여기서 설정
// }
- 변경 후 FixedAmountDiscountPolicy 클래스
package com.springboot.v4.discount;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
@Component
public class FixedAmountDiscountPolicy implements DiscountPolicy {
private double discountAmount;
public FixedAmountDiscountPolicy(@Value("${discount.amount}") double discountAmount) {
this.discountAmount = discountAmount;
}
@Override
public double applyDiscount(double price) {
return price - discountAmount;
}
}
- 변경 후 FixedRateDiscountPolicy 클래스
package com.springboot.v4.discount;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
@Component
public class FixedRateDiscountPolicy implements DiscountPolicy {
private double discountRate;
public FixedRateDiscountPolicy(@Value("${discount.rate}") double discountRate) {
this.discountRate = discountRate;
}
@Override
public double applyDiscount(double price) {
return price * (1 - discountRate);
}
}
- 변경 후 application.yml 클래스
spring:
h2:
console:
enabled: true
path: /h2
datasource:
url: jdbc:h2:mem:test
jpa:
hibernate:
ddl-auto: create # (1) 스키마 자동 생성
show-sql: true # (2) SQL 쿼리 출력
discount:
amount: 100
rate: 20
컴포넌트 스캔을 사용하는 자동 주입 방식에서 위의 코드로 프로그램을 실행하면 어떤 일이 일어날까요?
직접 프로그램을 동작시켜서 한번 확인해 봅시다.

문제점을 발견하셨나요?
스프링 컨테이너가 자동으로 빈을 주입해야 하지만, 두 가지 할인 정책이 모두 스프링 컨테이너가 관리하고 있어, 어떤 빈을 주입해야 할 지 선택할 수 없어서 발생하는 오류입니다.
에러 메시지를 읽어보면, 하나의 빈이 매칭될 것이 예상되었는데 두 개의 빈이 발견되었다고 합니다. 잘 생각해 보면, 지극히 자연스러운 일입니다.
Kiosk 클래스의 입장에서 보면, Discount 타입의 객체만 주입되면 아무런 문제가 없는데, 들어올 수 있는 선택지가 두 가지가 되어 어떤 구현 객체가 들어와야 할지 스프링에 입장에서는 알 방도가 전혀 없기 때문입니다.
만약 FixedAmountDiscountPolicy 또는 FixedRateDiscountPolicy 클래스 중에 하나만 @Component를 붙인다면, @Value 애너테이션을 사용하기 위해 빈에 등록이 필요하다는 오류와 함께 실행되지 않게 됩니다.
그러면 이 문제를 왜 이렇게까지 세세하게 다뤄야 했을까요?
사실 앞서 확인할 수 있었던 것처럼 이 문제가 @Autowired의 특성과 그 특성으로 인해 발생할 수 있는 잠재적인 문제를 잘 보여주고 있기 때문입니다.
@Autowired 애너테이션은 기본적으로 타입으로 빈을 조회합니다.
마치 getBean(Discount.class) 메서드를 호출하여 빈을 조회하는 것과 같습니다. 따라서, 위의 경우처럼 해당 빈의 타입이 2개 이상인 경우 스프링의 입장에서는 어떤 구현 객체가 들어와야 하는지 알 수 있는 방법이 없어 오류가 발생합니다.
물론, 참조 변수의 타입을 하위 구현 객체의 타입으로 변경할 수 있겠지만, 이 또한 구체적인 객체에 의존하는 결과를 초래하게 되어 객체지향적 설계의 원칙에 위배되는 것이기 때문에 권장되는 방식이 아닙니다.
그렇다면 어떻게 이 문제를 해결할 수 있을까요?
스프링은 크게 3가지의 해결 방법을 제공하고 있습니다.
- @Autowired 필드명 매칭
- @Qualifier 사용
- @Primary 사용
1. @Autowired 필드명 매칭
가장 손쉬운 방법으로는 필드명을 활용한 매칭 방법이 있습니다. @Autowired는 먼저 타입으로 빈을 조회하고, 만약 2개 이상의 여러 개의 빈이 있는 경우에 필드명 또는 매개변수명으로 빈을 매칭합니다.
하지만 해당 방법은, 필드 주입을 사용해야 하므로 실무에선 사용하지 않습니다.
2. @Qualifier 사용
두 번째 방법으로 @Qualifier를 사용하는 방법이 있습니다. 추가적인 구분자를 통해 의존 관계를 연결하는 방식입니다. 바로 코드를 통해 확인해 보겠습니다.
먼저 FixedAmountDiscountPolicy와 FixedRateDiscountPolicy 클래스에 @Qualifier 애너테이션을 통해 구분자를 지정해 줍니다.
- FixedAmountDiscountPolicy 클래스
@Component
@Qualifier("fixedAmount")
public class FixedAmountDiscountPolicy implements DiscountPolicy {
--- 생략 ---
}
- FixedRateDiscountPolicy 클래스
@Component
@Qualifier("fixedRate")
public class FixedRateDiscountPolicy implements DiscountPolicy {
--- 생략 ---
}
다음으로, 위의 할인 정책을 생성자로 주입받아 사용하고 있는 클래스들에 아래와 같이 매칭을 시켜줍니다.
- CozDiscountCondition 클래스
@Component
public class CozDiscountCondition implements DiscountCondition {
private boolean isSatisfied;
private DiscountPolicy discountPolicy;
public CozDiscountCondition(@Qualifier("fixedRate") DiscountPolicy discountPolicy) {
this.discountPolicy = discountPolicy;
}
--- 생략 ---
}
이제 프로그램을 실행하여, 이전과 같이 정상적으로 동작하는지 확인해 주세요.
@Qualifier 애너테이션은, 먼저 @Qualifier이 붙여진 추가 구분자를 통해 매칭되는 빈이 있는지 탐색하고, 매칭되는 빈이 없다면 빈의 이름으로 조회를 진행합니다.
참고로 여기서 따로 다루지는 않겠지만, 애노테이션을 직접 커이스마이징하여 사용할 수 있는 방법도 존재합니다. 혹시 이와 관련된 내용이 궁금하다면, 검색을 통해 학습해 보시기 바랍니다.
- @Primary 사용
마지막으로, 가장 빈번하게 사용되는 방식인 @Primary 애너테이션을 사용하여 여러 개의 빈이 들어올 수 있는 경우 빈 객체들 간 우선순위를 설정해 줄 수 있습니다.
마찬가지로 코드로 살펴보겠습니다.
아래와 같이 FixedRateDiscountPolicy 클래스에 @Primary 애너테이션을 붙여줍니다.
- FixedRateDiscountPolicy 클래스
@Component
@Primary
public class FixedRateDiscountPolicy implements DiscountPolicy {
private int discountRate = 10;
public int calculateDiscountedPrice(int price) {
return price - (price * discountRate / 100);
}
}