
[Spring MVC] JDBC 기반 데이터 액세스 계층
서비스 계층의 학습을 마치고 데이터 액세스 계층 학습을 위해 여기까지 오느라 수고 많았습니다.
이제 여러분들은 클라이언트의 요청을 Controller의 핸들러 메서드에서 전달받은 후에 서비스 계층과 연동하여 서비스 계층에서 비즈니스 로직을 처리하는 방법까지 알게 되었을 거라고 생각합니다.
이번 시간부터는 서비스 계층에서 비즈니스 로직을 통해 처리된 데이터를 데이터베이스(Database)에 저장하고, 비즈니스 로직을 처리하기 위해 데이터베이스(Database)에서 데이터를 조회하는 등의 역할을 수행하는 데이터 액세스 계층에 대한 학습을 진행해 보도록 하겠습니다.
프로그래밍 언어와 무관하게 어떠한 애플리케이션을 제작하더라도 데이터베이스 같은 데이터 저장소와의 연동은 필수라고 할 수 있습니다.
이번 유닛에서는 Java에서 지원하는 JDBC가 무엇인지 알아보고, Spring에서 지원하는 JDBC 기반의 데이터베이스 접근 방법을 자세히 살펴보도록 하겠습니다.
[Spring MVC] JDBC 기반 데이터 액세스 계층 학습을 위한 사전 준비 사항
이번 유닛의 학습을 원활하게 진행하기 위해 지금까지 여러분들이 구현해 본 Controller 및 Service 클래스들이 포함된 템플릿 프로젝트를 사용하도록 하겠습니다.
- JDBC 기반 데이터 액세스 계층 템플릿 프로젝트 복제
- 아래 github 링크에서 실습용 repository를 clone합니다.
- IntelliJ IDE로 clone 받은 local repository 디렉토리의 프로젝트를 Open합니다.
- 학습을 진행하며 학습 내용에 따라 예제 코드를 타이핑해 봅니다.
이 전 유닛에서 학습한 샘플 애플리케이션의 Controller나 Service 클래스 구현이 여전히 어려운 분들은 데이터 액세스 계층에 대한 학습을 진행하기 전에 이 전 유닛의 코드들을 한번 더 따라서 타이핑해 보고 난 후에 데이터 액세스 계층에 대한 학습을 진행하길 권장합니다.
데이터 액세스 계층부터는 여러분들이 학습을 통해 이해해야 되는 내용들이 상당히 많아집니다. 따라서 틈날 때마다 Controller와 Service 클래스, 예외 처리 등의 코드를 연습해서 여러분들의 지식으로 만들 수 있길 바랍니다.
[Spring MVC] JDBC 기반 데이터 액세스 계층 학습 참고용 레퍼런스 코드
이번 유닛에서 학습한 예제 코드는 아래 github에서 확인할 수 있습니다.
챕터에서 사용한 예제 코드는 챕터에 있는 코드들을 직접 타이핑해 본 후, 학습 내용을 조금 더 구체적으로 이해하기 위한 용도로만 활용해 주세요.
- Spring Data JDBC 유닛에 사용한 예제 코드
✅ 여러분들이 사용할 Spring Data JDBC 학습용 템플릿 프로젝트에는 여러분들이 Spring Data JDBC의 기술 학습을 하는데 집중할 수 있도록 리포지토리 클래스와 서비스 클래스 이외의 코드는 모두 구현이 되어 있습니다.
리포지토리(Repository) 클래스와 서비스 클래스는 여러분들이 템플릿 프로젝트에서 직접 구현을 해볼 수 있도록 비워져 있는 상태이니 참고 바랍니다.
만일 이번 챕터에서 수정된 모든 코드에 대해서 직접 타이핑을 해보고 싶다면 템플릿 프로젝트에 있는 일부 코드를 지우고 다시 타이핑해 보는 방식으로 코드 구현 연습을 할 수 있습니다.
한번 더 리마인드 해주세요!
복사/붙여넣기 해서 돌아가는 코드는 의미가 없습니다.
학습 목표
- JDBC가 무엇인지 이해할 수 있다.
- Spring Data JDBC가 무엇인지 이해할 수 있다.
- Spring Data JDBC를 이용해서 데이터의 저장, 수정, 조회, 삭제 작업을 할 수 있다.
- Spring Data JDBC 기반의 엔티티 연관 관계를 매핑할 수 있다.
JDBC란?
JDBC란?
- JDBC(Java Database Connectivity)는 Java 기반 애플리케이션의 코드 레벨에서 사용하는 데이터를 데이터베이스에 저장 및 업데이트하거나 반대로 데이터베이스에 저장된 데이터를 Java 코드 레벨에서 사용할 수 있도록 해주는 Java에서 제공하는 표준 사양(또는 명세, Specification)입니다.
JDBC는 Java 애플리케이션에서 데이터베이스에 액세스하기 위해 Java 초창기(JDK 1.1) 버전부터 제공되는 **표준 사양(또는 명세, Specification)**으로 Java 개발자는 JDBC API를 사용해서 다양한 벤더(Oracle, MS SQL, MySQL 등)의 데이터베이스와 연동할 수 있습니다.
JDBC API의 사용법을 배워야 할까?
결론부터 말하자면 Java에서 제공하는 JDBC API의 사용법은 배우지 않아도 됩니다.
그런데 왜 JDBC에 대해서 알아야 되는지 의아해하는 분도 있을 것 같습니다.
JDBC는 Java 기반의 애플리케이션에서 사용하는 데이터 액세스 기술의 기본이 되는 저수준(low level) API입니다.
하지만 뒤에서 우리가 학습하겠지만 Spring에서는 JDBC API를 직접적으로 사용하기보다는 Spring Data JDBC나 Spring Data JPA 같은 기술을 제공함으로써 개발자들이 조금 더 편리하게 데이터 액세스 로직을 구현할 수 있도록 해줍니다.
따라서 우리 코스에서 JDBC API를 직접적으로 사용할 일은 없습니다. 물론 여러분들이 기업에 입사를 하더라도 JDBC API를 사용할 가능성은 거의 없다고 봐도 무방합니다.
다만, Spring Data JDBC나 Spring Data JPA 같은 기술 역시 데이터베이스와 연동하기 위해 내부적으로는 JDBC를 이용하기 때문에 JDBC의 구체적인 API 사용법을 알 필요는 없지만 JDBC의 동작 흐름 정도는 알면 Spring에서 지원하는 데이터 액세스 기술을 사용하는데 도움이 됩니다.
JDBC API의 장단점에 대해서 더 알고 싶다면 아래 심화 학습을 참고하세요.
JDBC의 동작 흐름

[그림 3-32] JDBC의 동작 흐름
JDBC는 Java 애플리케이션 내에서 JDBC API를 사용하여 데이터베이스에 액세스하는 단순한 구조이기 때문에 JDBC의 동작 흐름은 [그림 3-32]와 같이 매우 심플합니다. [그림 3-32]의 동작 흐름을 한 문장으로 간단히 표현하자면 다음과 같습니다.
Java 애플리케이션에서 JDBC API를 이용해 적절한 데이터베이스 드라이버를 로딩한 후, 데이터베이스와 인터랙션 한다.
이처럼 JDBC API를 사용해 데이터베이스와 구체적인 인터랙션을 하기 위해서는 JDBC 드라이버를 먼저 로딩한 후에 데이터베이스와 연결을 해야 합니다.
✔ JDBC 드라이버(JDBC Driver)
JDBC 드라이버는 데이터베이스와의 통신을 담당하는 인터페이스인데, Oracle이나 MS SQL, MySQL 같은 다양한 벤더에서는 해당 벤더에 맞는 JDBC 드라이버를 구현해서 제공을 하게 되고, 우리는 이 JDBC 드라이버의 구현체를 이용해서 특정 벤더의 데이터베이스에 액세스 할 수 있습니다.
JDBC API 사용 흐름
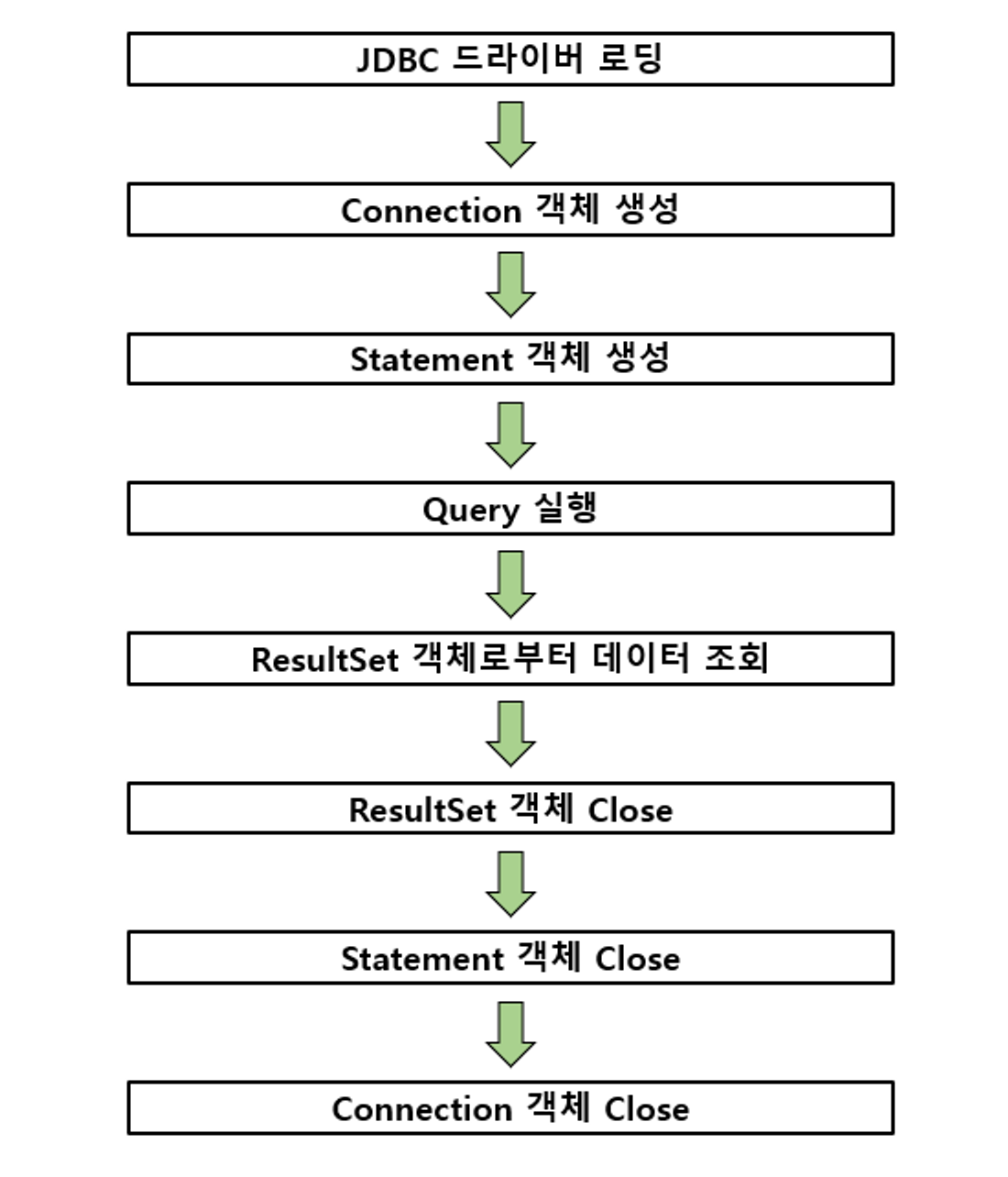
[그림 3-33] JBDC API 흐름
[그림 3-33]은 Java 코드 상에서 JDBC API를 사용하는 일반적인 흐름입니다.
JDBC API를 사용하는 구체적인 방법은 알 필요가 없지만 JDBC API에서 사용하는 각 구성요소들 중에서 우리가 기본적으로 알아야 하는 의미 있는 내용도 있기 때문에 간략하게나마 구성 요소들의 동작 흐름을 살펴보겠습니다.
1. JDBC 드라이버 로딩
사용하고자 하는 JDBC 드라이버를 로딩합니다. JDBC 드라이버는 DriverManager라는 클래스를 통해서 로딩됩니다.
2. Connection 객체 생성
JDBC 드라이버가 정상적으로 로딩되면 DriverManager를 통해 데이터베이스와 연결되는 세션(Session)인 Connection 객체를 생성합니다.
3. Statement 객체 생성
Statement 객체는 작성된 SQL 쿼리문을 실행하기 위한 객체로써 객체 생성 후에 정적인 SQL 쿼리 문자열을 입력으로 가집니다.
4. Query 실행
생성된 Statement 객체를 이용해서 입력한 SQL 쿼리를 실행합니다.
5. ResultSet 객체로부터 데이터 조회
실행된 SQL 쿼리문에 대한 결과 데이터 셋입니다.
6. ResultSet 객체 Close, Statement 객체 Close, Connection 객체 Close
JDBC API를 통해 사용된 객체들은 사용 이후에 사용한 순서의 역순으로 차례로 Close를 해주어야 합니다.
Connection Pool이란?

[그림 3-34] Connection Pool 사용 흐름
JDBC API를 사용해서 데이터베이스와의 연결을 위한 Connection 객체를 생성하는 작업은 비용이 많이 드는 작업 중 하나입니다.
따라서 애플리케이션 로딩 시점에 Connection 객체를 미리 생성해 두고 애플리케이션에서 데이터베이스에 연결이 필요할 경우, Connection 객체를 새로 생성하는 것이 아니라 미리 만들어 둔 Connection 객체를 사용함으로써 애플리케이션의 성능을 향상할 수 있습니다.
이처럼 데이터베이스 Connection을 미리 만들어서 보관하고 애플리케이션이 필요할 때 이 Connection을 제공해 주는 역할을 하는 Connection 관리자를 바로 Connection Pool이라고 합니다.
Spring Boot 2.0 이전 버전에는 Apache 재단의 오픈 소스인 Apache Commons DBCP(Database Connection Pool, DBCP)를 주로 사용했지만 Spring Boot 2.0부터는 성능면에서 더 나은 이점을 가지고 있는 HikariCP를 기본 DBCP로 채택했습니다.
HikariCP에 대해서 더 알아보고 싶다면 아래 심화 학습을 참고하세요.
핵심 포인트
- JDBC(Java Database Connectivity)는 Java 기반 애플리케이션의 코드 레벨에서 사용하는 데이터를 데이터베이스에 저장 및 업데이트하거나 반대로 데이터베이스에 저장된 데이터를 Java 코드 레벨에서 사용할 수 있도록 해주는 Java에서 제공하는 표준 API이다.
- JDBC의 구체적인 API 사용법을 알 필요는 없지만 JDBC의 동작 흐름을 알면 Spring에서 지원하는 데이터 액세스 기술을 사용하는데 도움이 된다.
- 데이터베이스 Connection 객체를 미리 만들어서 보관하고 애플리케이션이 필요할 때 이 Connection을 제공해 주는 역할을 하는 Connection 관리자를 바로 Connection Pool이라고 한다.
- Spring Boot 2.0부터 HikariCP가 기본 DBCP로 채택되었다.
심화 학습
- JDBC에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- HikariCP에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
[기본] Spring Data JDBC란?
데이터 액세스 기술 유형
Spring에서는 데이터베이스에 액세스하는 다양한 기술들을 사용할 수 있습니다.
Spring에서 사용할 수 있는 대표적인 데이터 액세스 기술에는 mybatis, Spring JDBC, Spring Data JDBC, JPA, Spring Data JPA 등이 있습니다.
노파심에 미리 얘기하지만 밑에서 소개하는 SQL 중심의 기술들은 기술들의 차이점을 설명하기 위한 용도이지 여러분들이 이번 코스에서 학습할 필요가 없는 내용들입니다. 기술들 간에 이런 차이점이 있다 정도로 이해하고 넘어가면 됩니다.
SQL 중심 기술
앞에서 언급한 mybatis와 Spring JDBC는 대표적인 SQL 중심 기술입니다.
즉, SQL 중심 기술은 애플리케이션에서 데이터베이스에 접근하기 위해 SQL 쿼리문을 애플리케이션 내부에 직접적으로 작성하는 것이 중심이 되는 기술입니다.
<select id="findMember" resultType="Member">
SELECT * FROM MEMBER WHERE member_id = #{memberId}
</select>[코드 3-69] mybatis의 SQL Mapper 예
코드 3-69는 mybatis에서 사용되는 SQL Mapper의 예입니다.
mybatis의 경우, SQL Mapper라는 설정 파일이 존재하는데 이 SQL Mapper에서 SQL 쿼리문을 직접적으로 작성합니다.
작성된 SQL 쿼리문을 기반으로 데이터베이스의 특정 테이블에서 데이터를 조회한 후, Java 객체로 변환해 주는 것이 mybatis의 대표적인 기술적 특징입니다.
코드에서 보다시피 SQL 쿼리문이 직접적으로 포함이 되어 있는 것을 볼 수 있습니다.
Member member = this.jdbcTemplate.queryForObject(
"select * from member where member_id=?", 1, Member.class);[코드 3-70] Spring JDBC의 JdbcTemplate 사용 예
코드 3-70은 Spring JDBC의 JdbcTemplate이라는 템플릿 클래스를 사용한 데이터베이스 접근 예입니다.
Spring JDBC의 경우에도 Java 코드에 SQL 쿼리문이 직접적으로 포함이 되어 있습니다.
이처럼 SQL 쿼리문이 직접적으로 포함이 되는 방식은 과거부터 많이 사용하던 방식이고, 현재도 사용이 되고 있긴 하지만 Java 진영에서는 SQL 중심의 기술에서 객체(Object) 중심의 기술로 지속적으로 이전을 하고 있는 추세라는 사실을 기억해 두면 좋을 것 같습니다.
객체(Object) 중심 기술
객체(Object) 중심 기술은 데이터를 SQL 쿼리문 위주로 생각하는 것이 아니라 모든 데이터를 객체(Object) 관점으로 바라보는 기술입니다.
즉, 객체(Object) 중심 기술은 데이터베이스에 접근하기 위해서 SQL 쿼리문을 직접적으로 작성하기보다는 데이터베이스의 테이블에 데이터를 저장하거나 조회할 경우, Java 객체(Object)를 이용해 애플리케이션 내부에서 이 Java 객체(Object)를 SQL 쿼리문으로 자동 변환 한 후에 데이터베이스의 테이블에 접근합니다.
이러한 객체(Object) 중심의 데이터 액세스 기술을 ORM(Object-Relational Mapping)이라고 합니다.
Java에서 대표적인 ORM 기술이 바로 JPA(Java Persistence API)입니다.
JPA를 사용하면 여러분들이 SQL 쿼리문을 직접적으로 다룰 일은 많지 않습니다.
물론 복잡한 조건의 데이터 조회를 위해 SQL 쿼리문을 사용기도하지만 그 사용 빈도수는 이 전보다 급격히 줄어듭니다.
JPA에 대해서는 뒤에서 자세히 학습할 예정이므로 구체적인 설명은 생략하도록 하겠습니다.
Spring Data JDBC란?
그렇다면 Spring Data JDBC는 무엇일까요?
뒤에서 학습하게 될 JPA의 경우, 기술 전체를 놓고 봤을 때 JPA의 기술적인 난이도와 복잡도는 꽤 높은 편이기 때문에 학습 곡선(Learning Curve) 역시 일정 부분에서는 꽤 가파른 편입니다.
반면에 Spring Data JDBC는 한마디로 심플합니다.
Spring Data JDBC는 JPA처럼 ORM 기술을 사용하지만 JPA의 기술적 복잡도를 낮춘 기술이기 때문에 상대적으로 학습 곡선이 가파르지 않습니다.
Spring Data JDBC vs JPA vs Spring Data JPA
그렇다면 Spring Data JDBC, JPA, Spring Data JPA 중에서 우리는 어떤 기술 위주로 학습을 해야 될까요?
결론은 '셋 다 배워야 한다'입니다.
우선 Spring Data JDBC 기술은 2018년에 1.0 버전이 처음 릴리스되었기 때문에 기술의 역사가 아직 짧은 편입니다. 따라서 현재도 기능 업그레이드가 꾸준히 이루어지고 있지만 아직까지는 JPA보다 상대적으로 적게 사용되고 있습니다.
하지만 애플리케이션의 규모가 상대적으로 크지 않고, 복잡하지 않을 경우에는 Spring Data JDBC가 뛰어난 생산성을 보여줄 거라 기대합니다.
그리고 Spring Data JDBC를 통해 기본적인 ORM의 개념과 Spring에서 Data에 접근하는 일관된 접근 방식을 먼저 접하게 되므로 뒤에서 학습하게 될 JPA와 Spring Data JPA를 이해하는데 꽤 많은 도움이 된다는 사실 역시 Spring Data JDBC를 학습해야 되는 이유 중에 하나라고 볼 수 있습니다.
JPA는 실무에서 가장 많이 사용하고 있는 기술이기 때문에 여러분들이 당연히 배워야 합니다.
Spring Data JPA는 Spring에서 JPA 기술을 편리하게 사용하기 위한 기술이기 때문에 JPA에 대한 선행 지식이 있어야 제대로 사용할 수 있습니다.
이 세 가지 기술들을 언제 다 익힐 수 있을까?
이 세 가지 기술들을 여러분들이 이번 코스 기간 동안 완벽하게 익히는 건 사실상 불가능합니다. 하지만 이 세 가지 기술들의 핵심 개념과 기본을 익힌 후에 여러분들이 스스로 더 많은 기능들을 습득할 수 있는 능력을 이번 코스 기간 동안 기를 수 있을 거라고 확신하기 때문에 너무 걱정하지 않았으면 하는 바람입니다.
어떤 기술이든지 간에 기본이 가장 중요하다는 사실 잊지 말길 바랍니다
Hello World 샘플 코드로 이해하는 Spring Data JDBC
Spring Data JDBC를 문장으로 장황하게 설명하기보다는 우선 실제로 동작하는 간단한 샘플 코드를 통해서 Spring Data JDBC의 기본 동작 방식을 이해해 보도록 하겠습니다.
Spring Data JDBC를 사용하기 위한 사전 준비
✔ 의존 라이브러리 추가
Spring Data JDBC를 사용하기 위해서는 코드 3-71과 같이 Spring Boot Starter를 추가해야 합니다.
dependencies {
...
...
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
runtimeOnly 'com.h2database:h2'
}[코드 3-71] build.gradle의 dependencies에 의존 라이브러리 추가
코드 3-71에서는 Spring Data JDBC를 사용하기 위해 ‘spring-boot-starter-data-jdbc’를 추가했습니다.
그리고 지금부터는 데이터베이스에서 데이터를 관리할 것이므로 개발 환경에서 손쉽게 사용할 수 있는 인메모리(In-memory) DB인 H2를 사용하기 위해 의존 라이브러리 설정에 추가했습니다.
인메모리(In-memory) DB란?
일반적으로 우리가 알고 있는 데이터베이스는 삭제를 하지 않는 이상 데이터베이스 서버를 내렸다가 다시 가동해도 데이터베이스 안에 데이터가 그대로 유지가 됩니다.
반면에 인메모리(In-memory) DB는 이름 그대로 메모리 안에 데이터를 저장하는 데이터베이스입니다.
여러분들이 알고 있다시피 메모리는 휘발성이기 때문에 컴퓨터 전원을 내렸다가 다시 올리면 메모리에 저장되어 있는 데이터는 모두 지워지게 됩니다.
이처럼 인메모리(In-memory) DB는 애플리케이션이 실행되는 동안에만 데이터를 저장하고 있기 때문에 애플리케이션 실행을 중지했다가 다시 실행시키면 인메모리(In-memory) DB안에 저장되어 있던 데이터는 모두 사라지게 됩니다.
인메모리(In-memory) DB를 사용하는 이유 그냥 MySQL이나 MariaDB 같은 데이터베이스를 PC에 설치하고 쓰면 되는 거 아니냐 라는 생각을 할 수 있을 텐데요.
물론 당연한 이야기이지만 운영 환경에서는 당연히 인메모리(In-memory) DB를 사용하지 않고, 사용해서도 안됩니다. 운영 환경에서의 데이터는 절대 지워지면 안 될 테니까요.
하지만 여러분들이 학습용이든 실무에서든 여러분의 PC에서 개발을 할 경우에는 인메모리(In-memory) DB를 사용하는 것이 애플리케이션의 테스트 측면에서 많은 이점을 가집니다.
개발을 진행하면서 작업한 코드에 대한 테스트는 꾸준히 진행을 해야 할 텐데, 테스트를 진행하기 위해서는 테스트에 필요한 데이터 이외에 나머지 쓸데없는 데이터는 테이블에 없는 것이 테스트의 정확도 면에서 유리하기 때문입니다.
그렇기 때문에 로컬 개발 환경에서는 테스트가 끝나고 나면 데이터베이스의 테이블에 남아있는 데이터는 깨끗이 비워져 있는 것이 좋습니다.
이런 이유 때문에 로컬 개발 환경에서는 인메모리(In-memory) DB를 주로 사용합니다. 애플리케이션을 실행해서 테스트를 진행하고 코드를 수정하는 작업을 반복할 때마다 데이터베이스의 초기 상태를 깨끗하게 유지할 수 있으니까요.
물론 Spring에서 지원하는 테스트 기능에서는 테스트가 끝나면 테스트에 사용한 데이터를 자동으로 지워주는 기능이 있지만 기본적으로 로컬 테스트 환경에서는 인메모리(In-memory) DB 사용을 권장한다라는 사실을 기억하길 바랍니다.
✔ application.yml 파일에 H2 Browser 활성화 설정 추가
Spring Boot Initializr를 통해 샘플 프로젝트를 생성하면 기본적으로 ‘src/main/resources’ 디렉토리 하단에 application.properties라는 비어 있는 파일이 보입니다.
Spring에서는 application.properties 또는 application.yml 파일을 통해 Spring에서 사용하는 다양한 설정 정보들을 입력할 수 있습니다.
.yml 파일은 애플리케이션의 설정 정보(프로퍼티)를 depth 별로 입력할 수 있는 더 나은 방법을 제공하기 때문에 application.properties의 파일 확장자를 application.yml로 변경하겠습니다.
파일을 선택한 후, [Shift + F6] 키를 누르면 파일 확장자를 손쉽게 바꿀 수 있습니다.(Windows, Mac 동일)
그리고 코드 3-72와 같이 H2 관련 설정을 추가합니다.
spring:
h2:
console:
enabled: true[코드 3-72] H2 기본 설정
코드 3-72와 같이 설정하면 웹 브라우저 상(H2 콘솔)에서 H2 DB에 접속한 후, 데이터베이스를 관리할 수 있습니다.
.yml(또는 yaml) 파일에 indent를 주어서 depth를 설정할 때에는 스페이스 바를 눌러서 indent를 설정해도 상관없지만 일반적으로는 Tab(탭) 키를 사용해서 일관성을 유지하는 것이 좋습니다.
✔ H2 DB 정상 동작 유무 확인
이제 H2 데이터베이스 연동이 잘 되었는지 확인해 봅시다.
여러분들이 git에서 clone한 학습용 템플릿 프로젝트를 실행할 경우 아래와 비슷한 로그가 출력이 되는 것을 볼 수 있습니다. (로그의 가로 출력 길이가 길어서 앞쪽의 불필요한 부분은 생략했으니 참고 바랍니다.)
오후 2:15:06: Executing ':Section3Week1JdbcApplication.main()'...
> Task :compileJava UP-TO-DATE
> Task :processResources
> Task :classes
> Task :Section3Week1JdbcApplication.main()
. ____ _ __ _ _
/\\\\ / ___'_ __ _ _(_)_ __ __ _ \\ \\ \\ \\
( ( )\\___ | '_ | '_| | '_ \\/ _` | \\ \\ \\ \\
\\\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.7.0)
No active profile set, falling back to 1 default profile: "default"
Bootstrapping Spring Data JDBC repositories in DEFAULT mode. // 데이터베이스와 관련된 로그
Finished Spring Data repository scanning in 10 ms. Found 0 JDBC repository interfaces. // 데이터베이스와 관련된 로그
Tomcat initialized with port(s): 8080 (http)
Starting service [Tomcat]
Starting Servlet engine: [Apache Tomcat/9.0.63]
Initializing Spring embedded WebApplicationContext
Root WebApplicationContext: initialization completed in 1830 ms
HikariPool-1 - Starting... // 데이터베이스와 관련된 로그
HikariPool-1 - Start completed. // 데이터베이스와 관련된 로그
H2 console available at '/h2-console'. Database available at 'jdbc:h2:mem:26d0d5d3-dcef-47f8-8e6b-67898bdcfbd0' // (1)
Tomcat started on port(s): 8080 (http) with context path ''
Started Section3Week1JdbcApplication in 3.018 seconds (JVM running for 3.423)Spring 애플리케이션이 출력한 로그들을 보면 이제 데이터베이스와 관련된 로그들이 출력된 것이 보입니다.
이 중에서 맨 마지막쯤에 (1)이라고 표기한 ‘H2 console available at '/h2-console'. Database available at
'jdbc:h2:mem:26d0d5d3-dcef-47f8-8e6b-67898bdcfbd0’ 라는 로그는 이제 H2 데이터베이스를 정상적으로 사용할 준비가 되었으며, 웹 브라우저로 접속해서 데이터베이스를 관리할 수 있음을 의미합니다.
이 정보를 이용해서 H2 데이터베이스에 접속해 보겠습니다.

[그림 3-35] H2 Browser 초기 화면
우리가 애플리케이션 로그에서 확인한 URL 컨텍스트인 ‘/h2-console’을 그림 3-35와 같이 복사해서 웹 브라우저에 주소를(localhost:8080/h2-console)를 입력합니다.
그리고 애플리케이션 로그에 출력된 ‘jdbc:h2:mem:26d0d5d3-dcef-47f8-8e6b-67898bdcfbd0’ 을 [JDBC URL]이라는 항목에 복사/붙여넣기 한 후, [Connect] 버튼을 클릭합니다.
[그림 3-36]과 같은 화면이 보인다면 H2 DB에 정상적으로 접속한 것입니다.

[그림 3-36] H2 Browser 로그인에 성공한 모습
이제 여러분들은 샘플 애플리케이션을 구현하고 테스트를 해보면서 H2 DB에 데이터가 잘 저장되었는지 등을 H2 콘솔을 통해서 확인할 수 있습니다.
✔ H2 DB 디폴트 설정의 문제점
그런데, H2 DB는 애플리케이션을 재시작할 때마다 애플리케이션 로그에 출력되는 JDBC URL이 매번 랜덤하게 바뀌기 때문에 매번 랜덤하게 변경된 JDBC URL을 다시 입력하는 것은 상당히 불편합니다.
이 문제는 application.yml 파일에 H2에 대한 추가 설정을 함으로써 해결할 수 있습니다.
이 문제를 해결하기 위한 추가 설정을 해봅시다.
✔ H2 DB 설정 추가
spring:
h2:
console:
enabled: true
path: /h2 # (1) Context path 변경
datasource:
url: jdbc:h2:mem:test # (2) JDBC URL 변경[코드 3-73] H2 추가 설정
코드 3-72에서의 H2 기본 설정에 두 가지 설정을 추가했습니다.
(1)에서는 H2 콘솔의 접속 URL Context path를 조금 더 간결하게 ‘/h2’로 설정했습니다.
(2)에서는 JDBC URL이 매번 랜덤하게 바뀌지 않도록 ‘jdbc:h2:mem:test’로 설정했습니다.
💡 아래는 프로퍼티의 들여쓰기(indent)를 헷갈려하는 분들이 이해하기 용이하도록 IntelliJ에서 확인한 application.yml 파일의 모습입니다.
프로퍼티마다 표시된 들여쓰기 수직 라인에 주의해서 작성을 하기 바랍니다.

이제 애플리케이션을 재가동하고, ‘localhost:8080/h2’로 접속한 뒤 [JDBC URL] 항목에 ‘jdbc:h2:mem:test’을 입력하고 [Connect] 버튼을 클릭하면 [그림 3-36]과 같이 접속이 될 것입니다.
Spring Boot에서는 appliation.properties 또는 application.yml 파일을 통해 굉장히 많은 설정 정보를 추가할 수 있습니다.
아직까지 우리에게 필요한 설정 정보(프로퍼티)가 많지 않지만 필요할 때마다 설정 정보(프로퍼티)를 추가하고 추가한 설정 정보에 대해서 설명을 하도록 하겠습니다.
Spring Boot에서 지원하는 설정 정보(프로퍼티)를 더 알아보고 싶다면 아래 심화 학습을 참고하세요.
Hello World 샘플 코드 구현
이제 Hello World 샘플 코드를 구현하기 위한 사전 준비는 끝났습니다.
클라이언트 쪽에서 “Hello, World” 문자열 데이터를 Request Body로 전송한 후에 Spring Data JDBC를 이용해서 이 “Hello, World” 문자열을 H2 데이터베이스에 저장해 보도록 합시다.
지금부터 구현하는 Hello World 샘플 코드 들은 기존에 구현되어 있는 커피 주문 샘플 애플리케이션 코드에 영향을 주지 않도록 ‘src/main/java/com/springboot’ 패키지 하위에 hello_world라는 패키지를 생성한 후, 이 hello_world 패키지 안에 Hello World 샘플 코드들을 작성하도록 하겠습니다.
Hello World 샘플 코드에서 구현해야 되는 클래스 또는 인터페이스는 다음과 같습니다.
- MessageDto(DTO 클래스)
- MessageController
- MessageMapper
- MessageService
- Message(엔티티 클래스)
- MessageRepository
사실 Message 엔티티 클래스까지는 우리가 여태껏 학습했기 때문에 구현의 어려움은 없을 거라 생각합니다.
아무튼 위 클래스 중에서 추가적인 설명이 필요한 부분은 MessageService, Message, MessageRepository입니다.
Hello World 샘플 코드에서는 서비스 계층의 MessageService 클래스와 데이터 액세스 계층의 MessageRepository 인터페이스를 어떻게 연동해서 데이터베이스에 데이터를 저장하는지 이해하는 것이 핵심 포인트라는 것을 기억하면서 아래 샘플 코드를 확인하기 바랍니다.
@Getter
public class MessagePostDto {
@NotBlank
private String message;
}[코드 3-74] MessagePostDto 클래스
클라이언트가 Request Body로 전달하는 “Hello, World” 문자열을 바인딩하는 DTO 클래스입니다.
여러분들이 이미 다 학습한 내용이므로 나머지 설명은 생략합니다.
@Getter
@Setter
public class MessageResponseDto {
private long messageId;
private String message;
}[코드 3-75] MessageResponseDto 클래스
Response에 사용할 DTO 클래스입니다.
역시 여러분들이 이미 알고 있는 내용들입니다.
@RequestMapping("/v1/messages")
@RestController
public class MessageController {
private final MessageService messageService;
private final MessageMapper mapper;
public MessageController(MessageService messageService,
MessageMapper mapper) {
this.messageService = messageService;
this.mapper = mapper;
}
@PostMapping
public ResponseEntity postMessage(
@Valid @RequestBody MessagePostDto messagePostDto) {
Message message =
messageService.createMessage(mapper.messageDtoToMessage(messagePostDto));
return ResponseEntity.ok(mapper.messageToMessageResponseDto(message));
}
}[코드 3-76] MessageController 클래스
클라이언트의 “Hello, World” 문자열 데이터를 전달받는 Controller 클래스입니다.
역시 여러분들이 이미 알고 있는 내용들입니다. 설명은 생략하겠습니다.
@Mapper(componentModel = "spring")
public interface MessageMapper {
Message messageDtoToMessage(MessagePostDto messagePostDto);
MessageResponseDto messageToMessageResponseDto(Message message);
}[코드 3-77] MessageMapper 인터페이스
DTO 클래스와 엔티티(Entity) 클래스를 매핑해 주는 Mapper 인터페이스입니다.
설명은 생략입니다.
import org.springframework.data.repository.CrudRepository;
public interface MessageRepository extends CrudRepository<Message, Long> {
}[코드 3-78] Message Repository 인터페이스
코드 3-78은 데이터 액세스 계층에서 데이터베이스와의 연동을 담당하는 Repository인 MessageRepository 인터페이스입니다.
인터페이스 내부에는 단 한 줄의 코드도 없는 아주 심플한 코드입니다.
특이한 것은 CrudRepository라는 인터페이스를 상속하고 있고, 이 CrudRepository의 제너릭 타입이 <Message, Long>으로 선언되어 있습니다.
CrudRepository는 데이터베이스에 CRUD(데이터 생성, 조회, 수정, 삭제) 작업을 진행하기 위해 Spring에서 지원해 주는 인터페이스입니다.
CrudRepository<Message, Long>와 같이 제너릭 타입을 지정해 줌으로써 Message 엔티티 클래스 객체에 담긴 데이터를 데이터베이스 테이블에 생성 또는 수정하거나 데이터베이스에서 조회한 데이터를 Message 엔티티 클래스로 변환할 수 있습니다.
<Message, Long>에서 Long은 Message 엔티티 클래스의 멤버 변수 중에 식별자를 의미하는 @Id라는 애너테이션이 붙어있는 멤버 변수의 데이터 타입입니다.
이 부분은 아래에서 다시 설명하도록 하겠습니다.
아무튼 짧은 한 줄짜리 MessageRepository 인터페이스 내부에 아무런 코드도 없지만 우리는 이 MessageRepository 인터페이스를 서비스 계층에서 DI를 통해 주입받은 후, 데이터베이스 작업을 위해 사용하게 됩니다.
@Service
public class MessageService {
// (1)
private final MessageRepository messageRepository;
public MessageService(MessageRepository messageRepository) {
this.messageRepository = messageRepository;
}
public Message createMessage(Message message) {
return messageRepository.save(message); // (2)
}
}[코드 3-79] MessageService 클래스
코드 3-78에서 정의한 MessageRepository 인터페이스는 코드 3-79 (1)과 같이 MessageService 클래스에서 DI를 통해 주입받은 후, (2)에서 Message 엔티티 클래스에 포함된 데이터를 데이터베이스에 저장하는 데 사용하고 있습니다.
그런데 우리가 앞에서 본 3-78의 MessageRepository 인터페이스 내부에는 별도로 구현한 메서드가 없는데도 불구하고 (2)에서는 messageRepository.save(message)와 같이 save() 메서드를 사용하고 있는 것을 볼 수 있습니다.
이 save() 메서드는 어디에 있는 걸까요?
바로 MessageRepository가 상속받은 CrudRepository에 이 save() 메서드가 정의되어 있습니다.
결론적으로 개발자가 데이터의 생성, 조회, 수정, 삭제 작업을 위한 별도의 코드를 구현하지 않아도 CrudRepository가 이 작업을 대신해 주는 역할을 합니다.
(2)에서는 데이터베이스에 데이터를 저장하고 난 후, 데이터베이스에 저장된 데이터를 다시 리턴해줍니다.
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.annotation.Id;
@Getter
@Setter
public class Message { // (1)
@Id // (2)
private long messageId;
private String message;
}[코드 3-80] Message 엔티티 클래스
Message 엔티티 클래스에서 설명할 내용은 두 가지입니다.
먼저 (1)의 Message라는 클래스 명은 데이터베이스의 테이블 명에 해당합니다.
그리고 (2)의 @Id 애너테이션을 추가한 멤버 변수는 해당 엔티티의 고유 식별자 역할을 하고, 이 식별자는 데이터베이스의 Primary key로 지정한 열에 해당됩니다.
이제 애플리케이션을 실행하고 클라이언트 쪽에서 요청을 전송해 보겠습니다.

[그림 3-37] “Hello, World” 메시지 전송 결과
기대했던 것과 달리 애플리케이션 쪽에서 에러가 발생했다는 응답을 받았습니다.
이유가 무엇인지 애플리케이션에 출력된 에러 로그를 확인해 보겠습니다.
at org.apache.tomcat.util.threads.ThreadPoolExecutor.runWorker...
at org.apache.tomcat.util.threads.ThreadPoolExecutor$Worker...
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable...
at java.base/java.lang.Thread.run(Thread.java:834) ~[na:na]
...
...
...
Caused by: org.springframework.jdbc.BadSqlGrammarException: PreparedStatementCallback;
bad SQL grammar [INSERT INTO "MESSAGE" ("MESSAGE") VALUES (?)]; // 여기
nested exception is org.h2.jdbc.JdbcSQLSyntaxErrorException: Table "MESSAGE" not found // 여기
(this database is empty); SQL statement:
INSERT INTO "MESSAGE" ("MESSAGE") VALUES (?) [42104-212]
at org.springframework.jdbc.support.SQLExceptionSubclassTranslator.doTranslate...
at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate..
at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate..
...
...애플리케이션이 출력한 긴 에러 로그 중에서 필요한 부분만 추려보았습니다.
에러 로그 중에서 중간에 Caused by: ~~~ 로 시작하는 부분을 확인하면 어디에 문제가 발생했는지 유추해 볼 수 있습니다.
문장 초반에는 SQL의 문법에 문제가 있다는 식의 표현이 보이지만 문장의 뒤 쪽으로 가면 데이터베이스가 비어있고, MESSAGE 테이블을 발견할 수 없다(Table "MESSAGE" not found)는 표현을 볼 수 있습니다.
에러 원인이 대충 무엇인지 이해가 되었을까요?
애플리케이션의 로직은 모두 구현해 놓고 정작 데이터를 저장할 테이블을 H2 DB에 생성하지 않았습니다.
마지막 작업으로 H2 DB에 테이블을 생성해 보도록 하겠습니다.
위 에러 로그 중에서 Casued by:~~ 로 시작하는 문장은 편의상 코드 박스 안에 모두 표시되도록 4개의 라인으로 편집을 했지만 실제로 애플리케이션 로그에서는 1개의 라인으로 표시가 됩니다.
여러분들이 애플리케이션에 어떤 문제가 발생했을 때, 문장의 초반에 나오는 에러 메시지만으로 판단하지 말고 문장의 끝까지 읽은 후에 정확힌 에러 내용을 파악하는 습관을 들이는 것이 좋습니다.
✔ H2 DB에 MESSAGE 테이블 생성
spring:
h2:
console:
enabled: true
path: /h2
datasource:
url: jdbc:h2:mem:test
sql:
init:
schema-locations: classpath*:db/h2/schema.sql // (1) 테이블 생성 파일 경로[코드 3-81] application.yml 파일에 추가된 DB 초기화 설정
Spring에서는 (1)과 같이 테이블 생성을 위한 SQL 문이 추가된 ‘schema’라는 파일명으로 .sql 파일의 경로를 지정해 주면 이 schema.sql 파일에 있는 스크립트를 읽어서 애플리케이션 실행 시, 데이터베이스에 테이블을 자동으로 생성해 줍니다.
그리고 인메모리 DB를 사용할 경우, 애플리케이션이 실행될 때마다 schema.sql 파일의 스크립트가 매번 실행된다는 사실 또한 기억하기 바랍니다.
‘schema.sql’ 파일은 ‘src/main/resources/db/h2’ 디렉토리 내에 위치해 있습니다.
CREATE TABLE IF NOT EXISTS MESSAGE (
message_id bigint NOT NULL AUTO_INCREMENT,
message varchar(100) NOT NULL,
PRIMARY KEY (message_id)
);[코드 3-82] schema.sql에 정의된 MESSAGE 테이블 생성 스크립트
코드 3-82에 정의된 스크립트에서 보다시피 ‘message_id’는 MESSAGE 테이블의 Primary key이고 AUTO_INCREMENT를 지정했기 때문에 데이터가 insert될 때마다 자동으로 증가됩니다.
즉, 이 말의 의미는 애플리케이션 쪽에서 데이터베이스에 데이터를 insert할 때 ‘message_id’ 열에 해당하는 값을 지정해주지 않아야 한다는 의미입니다.
MESSAGE 테이블은 코드 3-80의 Message 클래스 명과 매핑되고 ‘message_id’ 열은 Message 클래스의 messageId 멤버 변수와 매핑됩니다.
‘message’ 열은 예상했듯이 Message 클래스의 message 멤버 변수와 매핑됩니다.
ORM(Object-Relational Mapping)에서는 객체의 멤버 변수와 데이터베이스 테이블의 열이 대부분 1대1로 매핑이 됩니다.
지금은 조금 낯설게 느껴질 수 있겠지만 여러분들이 ORM을 사용하면 할수록 이러한 매핑 방식을 사용하는 것에 점차 익숙해질 거라고 생각합니다.
이제 애플리케이션을 다시 실행시키고, 클라이언트 쪽에서 다시 요청을 전송해 보겠습니다.

[그림 3-38] 테이블 생성 후, “Hello, World” 메시지 전송 결과
요청 전송의 응답 결과는 200 OK이고, 애플리케이션 쪽에서는 데이터베이스에 저장된 데이터를 리턴 받아 클라이언트 쪽에 Response Body로 전달해 주었습니다.
주목할 점은 요청 전송 시, Request Body에 messageId 값은 포함하지 않았는데, Response Body에는 messageId가 포함이 되었다는 사실입니다.
MESSAGE 테이블의 식별자(Primary key)인 ‘message_id’ 열에 AUTO_INCREMENT 설정이 되어 있으므로 ‘message_id’ 열에 값을 입력하지 않더라도 데이터가 저장될 때마다 자동으로 포함이 된다는 사실을 꼭 기억하기 바랍니다.
이제 H2 콘솔에 접속해서 MESSAGE 테이블에 데이터가 잘 저장되었는지 확인해 봅시다.

[그림 3-39] H2 콘솔에서 저장된 “Hello, Worl” 문자열 데이터를 확인하는 모습
[그림 3-39]와 같이 클라이언트 쪽에서 요청으로 전송한 메시지가 정상적으로 데이터베이스에 저장이 된 것을 확인할 수 있습니다.
Spring Data JDBC 적용 순서
Hello World 샘플 코드를 통해서 Spring Data JDBC를 어떻게 사용하는지 대략적으로 감이 올 거라 생각합니다.
마지막으로 코드 상에서 실제 어떤 순서대로 Spring Data JDBC 기술을 적용하면 좋을지 다시 한번 정리를 하겠습니다.
- build.gradle에 사용할 데이터베이스를 위한 의존 라이브러리를 추가합니다.
- application.yml 파일에 사용할 데이터베이스에 대한 설정을 합니다.
- ‘schema.sql’ 파일에 필요한 테이블 스크립트를 작성합니다.
- application.yml 파일에서 ‘schema.sql’ 파일을 읽어서 테이블을 생성할 수 있도록 초기화 설정을 추가합니다.
- 데이터베이스의 테이블과 매핑할 엔티티(Entity) 클래스를 작성합니다.
- 작성한 엔티티 클래스를 기반으로 데이터베이스의 작업을 처리할 Repository 인터페이스를 작성합니다.
- 작성된 Repository 인터페이스를 서비스 클래스에서 사용할 수 있도록 DI 합니다.
- DI 된 Repository의 메서드를 사용해서 서비스 클래스에서 데이터베이스에 CRUD 작업을 수행합니다.
핵심 포인트
- 데이터 액세스 기술의 유형은 크게 SQL 중심의 기술과 객체(Object) 중심의 기술로 나눌 수 있다.
- SQL 중심의 기술에는 mybatis, Spring JDBC 등이 있다.
- 객체(Object) 중심의 기술에는 JPA, Spring Data JDBC 등이 있다.
- JPA 같은 객체(Object) 중심의 기술을 ORM(Object-Relational Mapping) 기술이라고 한다.
- 인메모리(In-memory) DB는 애플리케이션이 실행된 상태에서만 데이터를 저장하고 애플리케이션 실행이 중지되면 인메모리 DB 역시 실행이 중지되어 저장된 데이터가 사라진다.
- Spring에서 지원하는 CrudRepository 인터페이스는 CRUD에 대한 기본적인 메서드를 정의하고 있기 때문에 별도의 CRUD 기능을 개발자가 직접 구현할 필요가 없다.
- application.properties 또는 application.yml 파일의 설정 정보 등록을 통해 데이터베이스 설정, 데이터베이스의 초기화 설정 등의 다양한 설정을 할 수 있다.
- application.yml 방식은 중복되는 프로퍼티의 입력을 줄여주기 때문에 application.properties 방식보다 더 선호되는 추세이다.
- 엔티티(Entity) 클래스 이름은 데이터베이스 테이블의 이름에 매핑되고, 엔티티 클래스 각각의 멤버 변수는 데이터베이스 테이블의 열에 매핑된다.
- 엔티티 클래스의 멤버 변수에 @Id 애너테이션을 추가하면 데이터베이스 테이블의 기본키(Primary key) 열과 매핑된다.
심화 학습
- 이번 챕터에서 설명한 Hello World 샘플 코드를 반드시 직접 타이핑해보면서 Spring Data JDBC의 기본 동작 방법을 이해해보세요.
- 인메모리(In-memory) DB에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- H2 콘솔 사용법에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- application.properties 또는 application.yml에 사용할 수 있는 설정 정보를 더 알아보고 싶다면 아래 링크를 참고하세요.
[기본] Spring Data JDBC 기반의 도메인 엔티티 및 테이블 설계
이 전 챕터에서 Spring Data JDBC를 사용한 Hello World 샘플 코드를 학습하면서 Spring Data JDBC의 대략적인 사용 방법을 살펴보았습니다.
이번 챕터에서는 우리가 지금까지 학습하면서 구현한 커피 주문 샘플 애플리케이션에 Spring Data JDBC 기반의 데이터 액세스 계층을 연동하기 위한 사전 준비를 해보도록 하겠습니다.
Spring Data JDBC 기반의 데이터 액세스 계층을 연동하기 위해 우리가 제일 먼저 해야 될 일은 바로 데이터베이스의 테이블과 도메인 엔티티 클래스의 설계입니다.
이번 챕터부터 데이터베이스에서 데이터가 관리되기 때문에 코드 구현에 있어서도 많은 변화가 있습니다.
특히 이 전 챕터까지는 Spring MVC에서 사용하는 기술 습득에 중점을 두었기 때문에 커피 주문 기능은 미흡한 부분이 많은 게 사실입니다.
이 부분 역시 이번 시간부터 개선을 해보도록 하겠습니다.
DDD(Domain Driven Design)란?
Spring Data JDBC에 대한 학습에서 DDD(Domain Driven Design)라는 용어를 언급해서 의아해 할 수도 있을 거라 생각합니다.
하지만 [DI를 통한 서비스 계층 ↔ API 계층 연동 챕터]에서 DDD에 대해 언급을 한 적이 있다는 사실을 기억하는 분들도 있을 거라 생각합니다.
- DDD(Domain Driven Design)는 우리말로 도메인 주도 설계 정도로 해석할 수 있는데, 용어의 의미 그대로 도메인 위주의 설계 기법을 의미합니다.
그런데 성능, 생산성, 안정성 면에서 뛰어난 애플리케이션을 만들기 위해 가장 중요한 영역인 애플리케이션의 설계는 구현보다 더 어렵습니다.
그래서 오래전부터 많은 사람들이 어떻게 하면 좀 더 나은 애플리케이션을 잘 설계할 수 있을까라고 고민한 결과물 중 하나가 바로 DDD(Domain Driven Design)입니다.
DDD 자체는 굉장히 뛰어난 설계 및 구현 기법이라 생각하지만 DDD의 개념을 완벽히 이해하는 것이 쉽지 않기 때문에 많은 학습과 설계 경험이 필요하다고 생각합니다.
그런데 Spring Data JDBC라는 기술이 DDD와 밀접한 관련이 있기 때문에, Spring Data JDBC에서 사용하는 DDD에 대한 기본 개념 정도는 이해하고 있어야 됩니다.
이 부분을 지금부터 간단하게 살펴보도록 하겠습니다.
Spring Data JDBC 기술을 잘 사용하기 위해서는 DDD에 대한 기본적인 개념 이해가 선행되어야 하며, 구현은 그다음이라고 생각합니다.
도메인(Domain)이란?
도메인(Domain)에 대해서는 [아키텍처란?] 챕터에서 언급을 이미 했는데 언급한 내용을 다시 한번 가져와 보도록 하겠습니다.
도메인(Domain)이란?
애플리케이션 개발에서 흔하게 사용하는 도메인이란 용어는 주로 비즈니스적인 어떤 업무 영역과 관련이 있습니다.
예를 들어, 여러분들이 새로운 배달 주문 앱을 만들어야 한다면 고객과 음식점, 배달원, 그리고 카드사 또는 은행 등 배달 주문 앱을 구현하기 위해 필요한 업무들을 자세히 알면 알수록 퀄리티가 높은 애플리케이션을 만들 가능성이 높습니다.
즉, 고객이 음식을 주문하는 과정, 주문받은 음식을 처리하는 과정, 조리된 음식을 배달하는 과정 등의 도메인 지식(Domain Knowledge)들을 서비스 계층에서 비즈니스 로직으로 구현해야 하는 것입니다.
도메인이 무엇인지 이해가 되었을까요? 그래도 잘 이해가 안 된다면 그냥 아래 문장만 기억을 하고 있으면 될 것 같습니다.
“도메인이란 용어 자체는 한 마디로 우리가 실제로 현실 세계에서 접하는 업무의 한 영역이다”
애그리거트(Aggregate)란?
이제 새로운 용어가 등장했습니다.
처음 들으면 앵그리 버드가 생각날 것만 같은 이 애그리거트(Aggregate)는 무엇을 의미하는지 살펴보도록 하겠습니다.
먼저 앞에서 잠깐 언급한 배달 주문 앱에서 필요한 업무 즉, 도메인에는 무엇이 있는지 그림으로 정리를 해보겠습니다.

[그림 3-40] 배달 주문 앱의 도메인
[그림 3-40]에서는 배달 주문 앱에서 필요한 업무 도메인을 대략적으로 뽑아보았습니다.
그냥 우리가 상식 선에서 배달 주문 앱을 이용할 때 어떤 기능들이 있을까, 그 기능들은 어떤 업무인 걸까 이 정도 수준으로 생각을 해본 것입니다.
고객이 음식을 주문하고, 배송을 받고 배송받은 음식을 먹는 서비스를 이용하려면 기본적으로 \[그림 3-40] 정도의 도메인만 있으면 될 것입니다.
그럼 이제 [그림 3-40]의 배달 주문 앱에 필요한 도메인을 조금 세분화해보겠습니다.

[그림 3-41] 배달 주문 앱의 도메인 세분화
[그림 3-41]에서는 배달 주문 앱의 도메인 영역을 구체적인 하위 수준의 도메인으로 세분화했습니다.
[그림 3-41]에서 회원, 주문, 음식, 결제는 상위 수준의 도메인이고, 이 상위 수준의 도메인 하위에 있는 각각의 정보들을 하위 수준의 도메인이라고 부를 수 있습니다.
자, 그럼 이제 애그리거트(Aggregate)가 무엇인지 알아보겠습니다.
- 애그리거트(Aggregate)란 [그림 3-41]과 같이 비슷한 업무 도메인들의 묶음을 말합니다.
[그림 3-41]에서의 애그리거트(Aggregate)는 총 네 개가 됩니다.
편의상 회원 애그리거트, 주문 애그리거트, 음식 애그리거트, 결제 애그리거트라고 부를 수 있습니다.
말로 장황하게 설명하면 애그리거트(Aggregate)는 어려운 개념이지만 애그리거트(Aggregate)는 한마디로 비슷한 범주의 연관된 업무들을 하나로 그룹화해놓은 그룹이라고 생각하면 조금 더 이해가 쉬울 것 같습니다.
애그리거트 루트(Aggregate Root)란?
DDD와 관련된 용어 중에서 한 가지만 더 살펴보고 복잡한 DDD에서 벗어나도록 합시다.
애그리거트는 이제 이해가 되었을 거라고 생각합니다.
그렇다면 애그리거트 루트(Aggregate Root)는 무엇일까요?
[그림 3-41]에서 정의한 네 개의 애그리거트 안에는 1개 이상의 도메인들이 있는데, 각각의 애그리거트에는 해당 애그리거트를 대표하는 도메인이 존재합니다.
이처럼 하나의 애그리거트를 대표하는 도메인을 DDD에서는 애그리거트 루트(Aggregate Root)라고 합니다.
비유를 통한 애그리거트 루트 예
1, 2, 3동으로 구성 된 아파트가 있는데, 각 동에는 각 동을 대표해서 일을 하는 동대표가 1명씩 있습니다.
동에 거주하는 입주민을 대표해서 의견도 전달하고, 주거 환경도 개선하는 등 해당 동에 관련된 일은 동대표를 거쳐서 이루어지는 경우가 많습니다.
애그리거트 루트로 비유하자면 동대표가 바로 애그리거트 루트인 셈입니다.
이처럼 애그리거트 루트(Aggregate Root)를 어떤 특정 집단이나 그룹의 대표라고 생각하면 이해가 조금 더 수월할 것 같습니다.
✔ 애그리거트 루트(Aggregate Root) 선정 기준
그렇다면 애그리거트 내의 도메인들 중에서 어떤 도메인을 애그리거트 루트(Aggregate Root)로 선정해야 할까요?
곰곰이 생각해 보면 [그림 3-41]의 각 애그리거트 내의 도메인들 중에서 다른 모든 도메인들과 직간접적으로 연관이 되어 있는 도메인들을 발견할 수 있습니다.
- 회원 애그리거트의 경우, ‘회원 포인트’가 얼마인지 알려면 해당 포인트를 가지는 ‘회원 정보’를 알아야 합니다. 즉, ‘회원 정보’ 도메인이 애그리거트 루트가 됩니다.
- 주문 애그리거트의 경우, ‘주문 정보’가 다른 모든 도메인과 직접적으로 관련이 있습니다. 즉 ‘주문 정보’ 도메인이 애그리거트 루트가 됩니다.
데이터베이스의 테이블 간 관계로 보자면, 애그리거트 루트는 부모 테이블이 되고, 애그리거트 루트가 아닌 다른 도메인들은 자식 테이블이 되는 셈입니다.
즉, 애그리거트 루트(Aggregate Root)의 기본키 정보를 다른 도메인들이 외래키 형태로 가지고 있다고 볼 수 있습니다.
관계형 데이터베이스에서 A 테이블의 기본키를 B 테이블이 가지고 있다면 A는 부모 테이블이 되고, B는 자식 테이블이 됩니다. B인 자식 테이블이 가지고 있는 A 테이블의 기본키를 외래키라고 합니다.

[그림 3-42] 배달 주문 앱의 애그리거트 루트(Aggregate Root)
[그림 3-42]는 각 애그리거트의 애그리거트 루트(Aggregate Root)를 표시한 모습입니다.
샘플 애플리케이션 도메인 엔티티 및 테이블 설계
그럼 이제 우리가 구현하고 있는 커피 주문 샘플 애플리케이션을 Spring Data JDBC의 기술을 잘 사용할 수 있도록 도메인 엔티티의 구성을 변경해 보겠습니다.
도메인에서 애그리거트 루트 찾기

[그림 3-43] 커피 주문 샘플 애플리케이션의 도메인 엔티티 모델
[그림 3-43]은 우리가 이번 챕터에서 Spring Data JDBC를 이용해서 구현해야 할 커피 주문 샘플 애플리케이션의 도메인 모델입니다.
우리가 구현하는 커피 주문 샘플 애플리케이션은 학습용이기 때문에 결제, 배송과 같은 도메인은 필요하지 않습니다. 따라서 굉장히 심플한 도메인 모델로 설계되었습니다.
✔ 변경된 요구 사항
그리고 이 전 챕터까지는 기술의 이해를 위해 한 명의 회원이 하나의 커피만 주문한다라고 가정하고 학습을 진행했지만 이번 챕터부터는 한 명의 회원이 하나 이상의 커피를 주문할 수 있는 요구 사항이 반영되기 때문에 [그림 3-43]과 같은 도메인 모델이 도출되었습니다.
세 개의 애그리거트(Aggregate)가 정의 되었고, 각 애그리거트((Aggregate)마다 애그리거트 루트(Aggregate Root)가 결정된 것을 볼 수 있습니다.
[그림 3-42] 애그리거트 루트를 찾은 배달 주문 앱 도메인의 축소판이기 때문에 애그리거트 루트를 찾는 것은 어렵지 않을 거라 생각합니다.
애그리거트 간의 관계
각 애그리거트 간의 관계는 1과 N(1 이상)으로 표시했습니다.
- 회원 정보(Member)와 주문 정보(Orders)의 관계(1 대 N)
- 한 명의 회원은 여러 번 주문을 할 수 있습니다.
- 주문 정보(Orders)와 커피 정보의 관계(N 대 N)
- 하나의 주문은 여러 종류의 커피를 가질 수 있습니다.
- 하나의 커피는 여러 건의 주문에 속할 수 있습니다.
- N 대 N의 관계는 일반적으로 1 대 N, N 대 1의 관계로 재 설계 되기 때문에 아래와 같이 변경됩니다.
- 주문 정보(Orders)와 주문 커피 정보(Order_Coffee): 1 대 N
- 주문 커피 정보(Order_Coffee)와 커피 정보(Coffee): N 대 1
엔티티 클래스 간의 관계
이제 이 애그리거트를 기준으로 도메인 엔티티 클래스 간의 관계를 클래스 다이어그램을 통해 구체적으로 표현해 보겠습니다.

[그림 3-44] 커피 주문 샘플 애플리케이션의 도메인 엔티티 클래스 다이어그램
[그림 3-44]는 커피 주문 샘플 애플리케이션의 도메인 엔티티 클래스의 관계를 클래스 다이어그램으로 표현한 것입니다.
각각의 엔티티 클래스를 간단하게 살펴보겠습니다.
- 회원(Member) 엔티티 클래스
- Member 클래스와 Order의 관계는 1 대 N의 관계이기 때문에 Member 클래스에 List<Order>가 추가되었습니다.
- 한 명의 회원은 여러 건의 주문을 할 수 있습니다. 따라서 하나의 Member 클래스에 여러 건의 주문이 포함된 List<Order>를 멤버 변수로 추가했습니다.
데이터베이스 테이블 간의 관계는 외래키를 통해 맺어지지만 클래스 간의 관계는 객체의 참조를 통해 맺어진다는 사실을 기억하기 바랍니다.
- 주문(Order) 엔티티 클래스
- Order 클래스와 Coffee 클래스는 N 대 N의 관계를 가지기 때문에 N 대 N의 관계를 1 대 N의 관계로 만들어주는 List<OrderCoffee>를 멤버 변수로 추가했습니다.
- 커피(Coffee) 엔티티 클래스
- Coffee클래스와 Order 클래스는 N 대 N의 관계를 가지기 때문에 N 대 N의 관계를 1 대 N의 관계로 만들어주는 List<OrderCoffee>를 멤버 변수로 추가했습니다.
- 주문_커피(OrderCoffee) 테이블
- Order 클래스와 Coffee 클래스가 N 대 N 관계이므로 두 클래스의 관계를 각각 1 대 N의 관계로 만들어주기 위한 OrderCoffee 클래스가 추가되었습니다.
- 주문하는 커피가 한 잔 이상일 수 있기 때문에 quantity(주문 수량) 멤버 변수를 추가했습니다.
이 외에 추가적으로 더 필요한 멤버 변수들이 있지만 필요하다면 학습을 진행하면서 그때그때 추가하도록 하겠습니다.
‘도대체 애그리거트(Aggregat)를 왜 구분하고, 애그리거트 루트(Aggregate Root)는 왜 찾는 거며, 엔티티 클래스 간의 관계를 왜 정의하는 거야?’ 라고 생각할 수 있습니다.
이유는 여러분들이 지금 ORM 기반의 데이터 액세스 기술인 Spring Data JDBC를 학습하고 있기 때문입니다.
ORM(Object-Relational Mapping)은 말 그대로 객체와 테이블을 매핑하는 기술이기 때문에 앞에서 했던 것처럼 클래스 간의 연관 관계를 찾을 수밖에 없습니다.
특히나 애그리거트 루트(Aggregate Root)는 Spring Data JDBC가 DDD와 밀접한 관련이 있기 때문에 여러분들이 Spring Data JDBC 기술을 사용하기 위해서는 도메인 모델을 잘 정의하고 애그리거트 루트(Aggregate Root)를 찾아야 합니다.
이 애그리거트 루트(Aggregate Root)를 통해 프로그래밍 코드 상에서의 구현 방법이 달라지는데, 이 부분은 이어지는 챕터에서 샘플 애플리케이션을 구현하며 다시 설명하겠습니다.
마지막으로 도메인 엔티티 간의 관계를 기준으로 데이터베이스의 테이블을 설계해 봅시다.
데이터베이스 테이블 설계

[그림 3-45] 커피 주문 샘플 애플리케이션의 테이블 설계
[그림 3-45]는 커피 주문 샘플 애플리케이션의 도메인 엔티티 클래스 간의 관계를 토대로 만든 데이터베이스의 테이블 설계입니다.
도메인 엔티티 클래스 간의 관계는 객체의 참조로 이루어지지만 테이블 간의 관계는 여러분이 이미 알고 있는 외래키(Foreign key) 참조로 이루어집니다.
각 테이블의 열은 엔티티 클래스의 멤버 변수와 매핑되므로 설명은 생략하겠습니다.
주문 테이블의 이름이 ‘ORDER’가 아니라 ‘ORDERS’인 이유
이미 눈치챈 분들도 있겠지만 ‘ORDER’는 SQL 쿼리문에서 테이블의 로우(Row)를 정렬하기 위해 사용하는 ‘ORDER BY’라는 예약어에 사용되기 때문에 테이블이 생성될 때 에러를 발생할 수 있습니다.
자, 이제 Spring Data JDBC를 적용하기 위한 설계가 끝났습니다.
이제 이 설계를 토대로 이제껏 학습을 진행하면서 만들어왔던 커피 주문 애플리케이션에 Spring Data JDBC를 적용해 볼까요? ^^
핵심 포인트
- DDD(Domain Driven Design, 도메인 주도 설계)는 도메인 위주의 설계 기법이다.
- 도메인(Domain)이란?
- 애플리케이션 개발에서 사용하는 도메인이란 용어는 주로 비즈니스적인 어떤 업무 영역과 관련이 있다.
- 애플리케이션을 구현하기 위해 필요한 업무들을 자세히 알면 알수록 퀄리티가 높은 애플리케이션을 만들 가능성이 높다.
- 비즈니스 업무 영역을 의미하는 도메인 지식(Domain Knowledge)들을 서비스 계층에서 비즈니스 로직으로 구현해야 한다.
- 애그리거트(Aggregate)와 애그리거트 루트(Aggregate Root)는 DDD에서 사용되는 용어이다.
- 애그리거트(Aggregate)란 비슷한 업무의 하위 수준 도메인들의 묶음을 의미한다.
- 애그리거트 내의 대표 도메인을 DDD에서는 애그리거트 루트(Aggregate Root)라고 한다.
- 애그리거트 루트의 선정 기준
- 각 애그리거트 내의 도메인들 중에서 다른 모든 도메인들과 직간접적으로 연관이 되어 있는 도메인이 애그리거트 루트가 된다.
- 데이터베이스 테이블 간의 관계는 외래키를 통해 맺어지지만 클래스끼리 관계는 객체의 참조를 통해 관계가 맺어진다.
심화 학습
- DDD(Domain Driven Design)에 대해서 더 알아보고 싶다면 아래 링크를 다시 한번 더 참고하세요. 아래 링크는 [DI를 통한 서비스 계층 ↔ API 계층 연동 챕터]에서도 확인할 수 있습니다.
- 애그리거트(Aggregate)에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
[기본] Spring Data JDBC를 통한 데이터 액세스 계층 구현(1) - 도메인 엔티티 클래스 정의
Spring Data JDBC라는 기술을 커피 주문 샘플 애플리케이션의 데이터 액세스 계층에 적용하기 위해 이 전 챕터에서 데이터베이스 테이블 및 도메인 엔티티에 대한 설계를 해보았습니다.
이제 설계한 대로 엔티티 클래스를 코드로 정의할 차례입니다.
이번 챕터와 다음 챕터까지는 굉장히 많은 코드들이 추가 및 변경되었고, 설명해야 되는 내용도 꽤 많습니다.
따라서 우리가 이 전 챕터에서 설계한 도메인 엔티티 클래스 다이어그램과 테이블을 우리가 구현할 코드와 비교해 가면서 확인해야 될 경우가 많을 것으로 생각되므로, 이 전 챕터에서 설계한 도메인 엔티티 클래스 다이어그램과 테이블을 챕터 상단에 포함시켜서 여러분들이 편하게 확인할 수 있도록 하겠습니다.
엔티티 설계 확인

[그림 3-46] 커피 주문 샘플 애플리케이션의 도메인 엔티티 클래스 다이어그램
[그림 3-46]은 우리가 설계한 커피 주문 샘플 애플리케이션의 도메인 엔티티 클래스 다이어그램입니다.
코드 구현 전, 기억해야 될 내용은 다음과 같습니다.
- Member 클래스와 Order 클래스는 1 대 N의 관계이다.
- 1에 해당되는 Member 클래스는 N에 해당되는 Order 클래스의 객체를 참조할 수 있도록 List<Order>를 멤버 변수로 가진다.
- Order 클래스와 Coffee 클래스는 N 대 N의 관계이므로, 1 대 N과 N 대 1의 관계로 변환되었다.
- 1에 해당되는 Order 클래스는 N에 해당되는 OrderCoffee 클래스의 객체를 참조할 수 있도록 List<OrderCoffee>를 멤버 변수로 가진다.
- 1에 해당되는 Coffee 클래스는 N에 해당되는 OrderCoffee 클래스의 객체를 참조할 수 있도록 List<OrderCoffee>를 멤버 변수로 가진다.
테이블 설계 확인

[그림 3-47] 커피 주문 샘플 애플리케이션의 테이블 설계
[그림 3-47]은 우리가 설계한 커피 주문 샘플 애플리케이션의 테이블 설계 다이어그램입니다.
역시 코드 구현 전, 기억해야 될 내용은 다음과 같습니다.
- MEMBER 테이블과 ORDERS 테이블은 1 대 N의 관계이다.
- 1에 해당되는 MEMBER 테이블과 N에 해당되는 ORDERS 테이블은 ORDERS에 추가된 member_id 외래키(Foreign key)로 조인할 수 있다.
- ORDERS 테이블과 COFFEE 테이블은 N 대 N의 관계이므로, 1 대 N과 N 대 1의 관계로 변환되었다.
- 1에 해당되는 ORDERS 테이블과 N에 해당되는 ORDER_COFFEE 테이블은 ORDER_COFFEE 테이블에 추가된 order_id 외래키(Foreign key)로 조인할 수 있다.
- 1에 해당되는 COFFEE 테이블과 N에 해당되는 ORDER_COFFEE 테이블은 ORDER_COFFEE 테이블에 추가된 coffee_id 외래키(Foreign key)로 조인할 수 있다.
Java에서 테이블의 외래키(Foreign key)를 표현하는 일반적인 방법: 클래스의 객체 참조 리스트(List<T\>)
테이블 간의 관계는 외래키라는 연결 요소가 있어서 직관적입니다. 그런데 클래스들 간에는 외래키라는 연결 요소가 없습니다. 대신에 클래스들은 객체 간에 참조가 가능하기 때문에 이 객체 참조를 사용해서 외래키의 기능을 대신합니다.
ORM(Object-Relational Mapping)에서 가장 헷갈리는 것들 중에 하나가 바로 외래키를 객체 참조로 표현하는 것입니다.
MEMBER 테이블/ORDERS 테이블과 Member 클래스/Order 클래스를 비교해 보세요.
MEMBER 테이블은 member_id를 ORDERS 테이블의 외래키로 지정하면 됩니다. 그러면 ORDERS 테이블의 데이터를 조회할 수 있습니다. 테이블 간에 조인(join)을 하면 되니까요.
그런데 Member 클래스는 외래키 자체가 없습니다. 테이블이 아니라 클래스이니까요. 그렇다면 Member 클래스가 Order 클래스의 데이터를 조회하려면?
맞습니다. 객체 참조가 있으면 됩니다.
그런데 왜 List<Order> 이냐고요? 여러분이 카페에 가면 커피를 여러 번 주문할 수 있듯이 Member 클래스 역시 Order 클래스의 객체를 여러 개 가질 수 있습니다. 여러 개의 객체는 어떻게 표현할 수 있을까요? List, Set 같은 컬렉션을 사용해서 표현할 수 있습니다.
이해가 되었을 거라 생각합니다. 하지만 지금은 이해되어도 시간이 지나면 다시 헷갈릴 수 있습니다. 이 헷갈림을 헷갈리지 않게 하는 방법은?
연습을 통해서 익숙해지는 수밖에 없습니다.
Spring Data JDBC에서의 애그리거트(Aggregate) 객체 매핑
테이블의 관계와 도메인 엔티티 클래스 간의 관계를 이해했으니 이제 거침없이 구현을 하면 됩니다.
데이터베이스 테이블의 경우 우리가 설계한 대로 테이블 스키마를 사용해서 테이블을 생성하면 됩니다.
그런데 문제는 도메인 엔티티 클래스입니다.
우리가 설계한 도메인 엔티티 클래스 간의 관계는 잘 설계된 게 맞지만 Spring Data JDBC를 사용하기 위해서는 우리가 설계한 도메인 엔티티 클래스의 관계를 DDD(Domain Driven Design, 도메인 주도 설계)의 애그리거트(Aggregate) 매핑 규칙에 맞게 한번 더 변경할 필요가 있습니다.
이 전 챕터에서 DDD의 애그리거트(Aggregate)와 애그리거트 루트(Aggregate Root)를 설명한 이유가 바로 여기에 있습니다.
이제 애그리거트 매핑 규칙에 맞게 우리가 설계한 도메인 엔티티 다이어그램을 변경해 보도록 하겠습니다.
애그리거트 객체 매핑 규칙
애그리거트의 객체 매핑 규칙은 공식 문서를 살펴봐도 ‘아.. 규칙이 이렇구나..’라고 명확하게 이해가 되지 않습니다.
그래서 여러분들이 조금 더 쉽게 이해할 수 있도록 애그리거트 객체 매핑 규칙의 핵심만 다음과 같이 정리를 했습니다.
문장으로 된 아래 규칙들을 읽어도 여러분이 이해하지 못할 가능성이 높습니다.
이 경우, 이어지는 엔티티 클래스의 구현 코드를 확인한 후, 다시 돌아와서 읽으면 이해가 될 가능성이 높습니다.
그래도 이해가 되지 않는다면 구현 코드와 매핑 규칙을 번갈아 가면서 반복해서 확인하길 바랍니다.
(1) 모든 엔티티 객체의 상태는 애그리거트 루트를 통해서만 변경할 수 있다.
(2) 하나의 동일한 애그리거트 내에서의 엔티티 객체 참조
- 동일한 하나의 애그리거트 내에서는 엔티티 간에 객체로 참조한다.
(3) 애그리거트 루트 대 애그리거트 루트 간의 엔티티 객체 참조
- 애그리거트 루트 간의 참조는 객체 참조 대신에 ID로 참조한다.
- 1대1 또는 1대N 관계일 때 테이블 간의 외래키 방식과 동일하다.
- N대 N 관계일 때는 외래키 방식인 ID 참조와 객체 참조 방식이 함께 사용된다.
(1) 번 규칙은 DDD에서 사용하는 중요한 핵심 규칙입니다.
이 말의 의미를 조금 더 잘 이해하기 위해서는 이 전 챕터에서 정의한 애그리거트 간의 관계 그림을 다시 볼 필요가 있겠네요. 복습이라고 생각하고 한번 더 보겠습니다.

[그림 3-48] 배달 주문 앱의 애그리거트 루트(Aggregate Root) 예
이 전 챕터에서 학습했던 배달 주문 앱의 애그리거트 루트를 통해서 (1) 번 규칙을 이해해 보도록 하겠습니다.
회원 애그리거트의 경우, 애그리거트 루트는 회원 정보라는 엔티티 클래스가 될 것입니다.
여러분들도 잘 알다시피 비용을 지불하고 주문을 하면 주문한 만큼 회원 포인트를 얻게 됩니다.
이때 프로그래밍적으로는 회원의 포인트를 업데이트해주어야 하는데 회원 포인트라는 엔티티를 직접적으로 접근하지 말고 반드시 ‘회원 정보’라는 애그리거트 루트를 통해서 ‘회원 포인트’ 엔티티에 접근한 뒤, 포인트의 상태를 변경한다는 것이 바로 (1) 번 규칙의 핵심입니다.
주문 애그리거트 역시 마찬가지입니다.
‘주문 정보’ 애그리거트 루트 이외에 다른 엔티티의 상태를 변경하려면 ‘주문 정보’ 애그리거트 루트를 거쳐서 엔티티의 상태를 변경해야 합니다.
결과적으로 애그리거트 루트를 통해서 나머지 엔티티에 접근한다는 것은 어떤 식으로든 애그리거트 루트가 나머지 모든 엔티티에 대한 객체를 직간접적으로 참조할 수 있다는 의미입니다.
왜 애그리거트 루트를 통해서만 나머지 엔티티의 상태를 변경해야 할까요?
이유는 당연히 DDD와 관련이 있습니다.
예를 들어서 여러분이 음식을 주문한 이후에 주소를 잘못 입력해서 배달 주소 정보를 다시 변경하는 경우를 생각해 봅시다.
이때, ‘배달 주소 정보’라는 엔티티에 직접적으로 접근해서 주소 정보를 바꾸어 버리면 주소 정보를 변경할 수 없는 상태에도 주소 정보를 변경할 수 있게 되어버립니다.
이를테면 음식이 이미 다 만들어져서 처음에 잘못 입력한 주소 정보로 배달을 하는 중인데, 배달 주소를 바꾼다고 배달 업체가 변경된 주소로 배달을 하지는 않을 것입니다. 이 경우에는 음식점에 직접 전화해서 수동으로 변경 사항을 요청해야 할 것입니다.
즉, ‘배달 주소 정보’라는 엔티티에 직접 접근해서 주소 정보를 변경하게 되면 ‘음식이 다 만들어지기 전까지만 주소 정보를 변경할 수 있다’라는 규칙을 무시하고 상태를 변경하는 것이 되기 때문에 이런 도메인 규칙에 대한 일관성이 깨집니다.
따라서 항상 ‘주문 정보’라는 애그리거트 루트를 먼저 거쳐서 ‘음식이 이미 다 만들어졌는지 아직 조리 중인지’ 등의 규칙을 잘 검증한 후에 검증에 통과하면 ‘배달 주소 정보’ 엔티티의 상태를 업데이트하도록 해서 도메인 규칙의 일관성을 유지하도록 하는 것입니다.
우리가 애플리케이션 전체를 DDD 방식으로 설계하고 구현하는 것은 아니기때문에 DDD에 대해서 더 자세한 내용을 지금 알지 못해도 상관없습니다.
다만, 애그리거트와 애그리거트 루트를 잘 찾을 수 있는 연습을 한다면 여러분들이 미래에 Spring Data JDBC를 사용하든 Spring Data JPA를 사용하든 DDD 기반의 애플리케이션을 설계하는데 있어서 큰 도움이 될거라 확신합니다.
(2) 번 규칙은 우리가 이미 알고 있는 엔티티 간에는 객체로 참조한다라는 규칙과 같습니다.
단, (2) 번 규칙은 동일한 애그리거트 내의 엔티티끼리 참조할 경우에만 적용되는 규칙입니다.
(3) 번 규칙의 핵심은 애그리거트 루트 간에 객체로 참조하지 않고, 테이블에 외래키를 추가하듯이 참조하고자 하는 애그리거트 루트의 ID를 참조 값으로 멤버 변수에 추가하는 것입니다.
하지만 1대 N일 경우와 N대 N일 경우의 방식이 조금 다릅니다.
애그리거트 간의 매핑 규칙은 문장으로 쉽게 이해되지 않을 가능성이 높기 때문에 코드를 구현하면서 구체적으로 이해해 보도록 하겠습니다.

[그림 3-49] 커피 주문 샘플 애플리케이션의 도메인 엔티티 모델
마지막으로 [그림 3-49]는 이 전 챕터에서 설계한 커피 주문 샘플 애플리케이션의 도메인 엔티티 모델입니다.
[그림 3-49]의 애그리거트와 애그리거트 루트를 잘 숙지하고 있길 바랍니다.
이제 도메인 엔티티 설계 다이어그램, 테이블 설계 다이어그램, 애그리거트 간의 매핑 규칙, 도메인 엔티티 모델을 토대로 커피 주문 샘플 애플리케이션의 도메인 엔티티 클래스를 먼저 구현해 보겠습니다.
엔티티 구현
✔ Member 클래스와 Order 클래스의 애그리거트 루트 매핑
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.annotation.Id;
@Getter
@Setter
public class Member {
// (1)
@Id
private Long memberId;
private String email;
private String name;
private String phone;
}[코드 3-83] Member 엔티티 클래스 (Member.java)
Member 클래스는 Spring Data JDBC의 엔티티이므로 (1)과 같이 memberId 멤버 변수에 @Id 애너테이션을 붙여 식별자로 지정했습니다.
이제 이 Member 클래스는 데이터베이스 테이블에서 MEMBER 테이블과 매핑됩니다.
...
import com.springboot.member.entity.Member;
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.Table;
...
...
@Getter
@Setter
@Table("ORDERS") // (1)
public class Order {
// (2)
@Id
private long orderId;
// (3) 테이블 외래키처럼 memberId를 추가해서 참조하도록 한다.
private long memberId;
...
...
}[코드 3-84] Order 엔티티 클래스 (Order.java)
코드 3-84는 Order 클래스 코드의 일부입니다.
Member 클래스와 Order 클래스 간 매핑 규칙 설명을 위한 코드 외에 나머지 코드는 우선 생략했습니다. 나머지 코드들은 기능을 추가하면서 추가적으로 설명하도록 하겠습니다.
(1)과 같이 @Table 애너테이션을 추가하지 않으면 기본적으로 클래스명이 테이블의 이름과 매핑됩니다. 하지만 앞에서 설명했듯이 ‘Order’라는 단어는 SQL 쿼리문에서 사용하는 예약어이기 때문에 (1)과 같이 @Table(”ORDERS”)와 같이 테이블 이름을 변경했습니다.
(2)
Order 클래스 역시 Spring Data JDBC의 엔티티이므로 (1)과 같이 memberId 멤버 변수에 @Id 애너테이션을 붙여 식별자로 지정했습니다. 이제 Order 클래스는 ORDERS 테이블과 매핑됩니다.
(3)
Member 클래스는 회원 애그리거트의 루트입니다.
그리고 Order 클래스는 주문 애그리거트의 루트입니다.
Member 클래스와 Order 클래스는 1대 N의 관계입니다.
애그리거트 간의 매핑 규칙 (3) 번에서 애그리거트 루트와 애그리거트 루트 간에는 객체로 직접 참조하는 것이 아니라 ID로 참조한다고 했습니다.
코드 3-84에서 Order 클래스에 long meberId를 외래키처럼 추가했습니다.
코드 3-84의 (3)과 같이 long memberId로 외래키를 표현했는데 Spring Data JDBC에서는 AggregateReference 라는 클래스를 이용해 private AggregateReference<Member, Long> memberId; 와 같이 외래키를 표현할 수도 있습니다.
이렇게 하면 코드를 통해 명시적으로 애그리거트 루트 간의 참조를 표현하기 때문에 코드 가독성이 좋아진다는 장점이 있습니다.
단, memberId 필드가 원시타입이 아닌 객체 참조 타입이므로 OrderMapper에서 DTO와 Entity 같의 변환에 추가 작업이 필요할 수 있습니다.
✅ 1대 N 관계의 애그리거트 루트 간 ID 참조는 AggregateReference 클래스로 한번 감싸주는 방법으로 구현할 수 있음을 기억하세요!
✔ Order 클래스와 Coffee 클래스의 애그리거트 루트 매핑
이제 Order 클래스와 Coffee 클래스를 매핑해 보도록 하겠습니다.
두 클래스 모두 애그리거트의 루트입니다.
그런데 Order 클래스와 Coffee 클래스는 N대 N의 관계입니다.
애그리거트 매핑 규칙에서 (3) 번인 애그리거트 루트와 애그리거트 루트 간에는 객체로 직접 참조하는 것이 아니라 ID로 참조한다가 적용되지만 N대 N의 관계이기 때문에 1대 N의 관계인 Member 클래스, Order 클래스와는 조금 다르게 매핑이 됩니다.
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.annotation.Id;
@Getter
@Setter
public class Coffee {
// (1)
@Id
private long coffeeId;
private String korName;
private String engName;
private int price;
private String coffeeCode; // (2) 추가된 열
}[코드 3-85] Coffee 엔티티 클래스 (Coffee.java)
코드 3-85는 Coffee 클래스의 코드입니다.
(1)
Coffee 클래스 역시 Spring Data JDBC의 엔티티이므로 (1)과 같이 coffeeId 멤버 변수에 @Id 애너테이션을 붙여 식별자로 지정했습니다. 이제 Coffee 클래스는 COFFEE 테이블과 매핑됩니다.
(2)
(2)와 같이 Coffee의 중복 등록을 체크하기 위해 필요한 coffeeCode 멤버 변수만 추가되었을 뿐 크게 달라진 건 없습니다.
package com.springboot.order.entity;
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.MappedCollection;
import org.springframework.data.relational.core.mapping.Table;
import java.time.LocalDateTime;
import java.util.LinkedHashSet;
import java.util.Set;
@Getter
@Setter
@Table("ORDERS")
public class Order {
@Id
private long orderId;
// 테이블 외래키처럼 memberId를 추가한다.
private long memberId;
// (1)
@MappedCollection(idColumn = "ORDER_ID")
private Set<OrderCoffee> orderCoffees = new LinkedHashSet<>();
...
...
}[코드 3-86] Order와 Coffee 클래스의 애그리거트 루트 매핑
코드 3-86에서는 Order 엔티티 클래스와 Coffee 엔티티 클래스를 매핑하기 위한 코드가 (1)과 같이 추가되었습니다.
(1)
Order 클래스는 애그리거트 루트입니다.
Coffee 클래스는 애그리거트 루트입니다.
그런데 두 클래스는 N대 N 관계입니다. 따라서 애그리거트 매핑 규칙 (3) 번 규칙이 적용되지만 N대 N이기 때문에 1대1, 1대 N과 같이 ID 값을 참조하지만 조금 다른 방식을 적용합니다.
우선 Order 클래스와 Coffee 클래스가 N대 N 관계이기 때문에 N대 N 관계를 1대 N, N대1 관계로 풀어줄 엔티티가 중간에 하나 필요합니다.
그 엔티티 클래스가 바로 (1)에 있는 OrderCoffee라는 클래스입니다.
이 OrderCoffee 클래스는 [그림 3-48]의 주문 애그리거트에 포함된 ‘주문커피정보’ 엔티티의 역할을 하는데 중요한 건 이 엔티티가 Order 클래스와 동일한 애그리거트에 있다는 것입니다.
동일한 애그리거트 내에서는 객체 참조를 사용합니다(애그리거트 매핑 규칙 (2) 번).
그래서 Set<OrderCoffee>를 통해 Order 클래스와 ‘주문커피정보’ 엔티티 역할을 하는 OrderCoffee 클래스와 1대 N의 관계를 만들 수 있습니다.
✅ @MappedCollection 애너테이션의 역할
@MappedCollection(idColumn = "ORDER_ID", keyColumn = "ORDER_COFFEE_ID")
private Set<OrderCoffee> orderCoffees = new LinkedHashSet<>();
코드 3-86의 (1)에 추가한 @MappedCollection(idColumn = "ORDER_ID", keyColumn = "ORDER_COFFEE_ID") 은 엔티티 클래스 간에 연관 관계를 맺어주는 정보를 의미합니다.
뒤에서 바로 나오지만 OrderCoffee 클래스는 ORDER_COFFEE 테이블과 매핑되는 엔티티 클래스입니다.
ORDER_COFFEE 테이블의 열 중에서 ORDERS 테이블과 관계를 맺어주는 역할을 하는 열은 무엇인가요?
바로 ORDERS 테이블의 기본키를 외래키로 가지는 열입니다. ORDER_COFFEE에서 외래키 역할을 하는 열명은? ORDER_ID입니다.
⭐ idColumn 이처럼 ‘idColumn’ 애트리뷰트는 자식 테이블에 추가되는 외래키에 해당되는 열명을 지정합니다.
ORDERS 테이블의 자식 테이블은 ORDER_COFFEE 테이블이고 이 ORDER_COFFEE 테이블은 ORDERS 테이블의 기본키인 ORDER_ID 열의 값을 외래키로 가집니다.
그래서 ‘idColumn’의 값이 ‘ORDER_ID’인 것입니다.
⭐ keyColumnkeyColumn 애트리뷰트는 외래키를 포함하고 있는 테이블의 기본키 열명을 지정합니다.
ORDERS 테이블의 자식 테이블인 ORDER_COFFEE 테이블의 기본키는 ORDER_COFFEE_ID 이므로, keyColumn의 값이 ‘ORDER_COFFEE_ID’인 것입니다.
Spring Data JDBC에서 @MappedCollection(idColumn = "") 은 JPA의 @OneToMany(mappedBy="") 속성만큼이나 이해하기 어려운 개념입니다.
우선 이것 한 가지만 기억하기 바랍니다. 테이블 간에 관계를 만들어주는 주체는 무엇인가?
무엇일까요?
바로 외래키입니다.
@MappedCollection(idColumn = "") 에는 바로 외래키에 해당하는 열명을 적어주면 됩니다.
나중에 JPA의 학습 때 다시 설명하겠지만 JPA에서도 테이블 간에 연관관계를 맺게 해주는 주체가 외래키이므로 mappedBy 애트리뷰트의 값은 이 외래키의 열명에 해당하는 객체의 필드명을 적어주면 되는 것입니다
이제 OrderCoffee 클래스와 Coffee 클래스 간에 N대1의 관계만 만들면 됩니다.
package com.springboot.order.entity;
import lombok.Builder;
import lombok.Getter;
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.Table;
@Getter
@Builder
@Table("ORDER_COFFEE") // (1)
public class OrderCoffee {
@Id
private long orderCoffeeId;
private long coffeeId; // (2)
private int quantity; // (3)
}[코드 3-87] OrderCoffee 엔티티 클래스 (OrderCoffee.java)
코드 3-87은 OrderCoffee 엔티티 클래스의 코드입니다.
(1)
(1)과 같이 @Table 애너테이션을 추가하지 않으면 기본적으로 클래스명이 테이블의 이름과 매핑됩니다. 코드 3-87에서는 (1)과 같이 @Table("ORDER_COFFEE")와 같이 테이블 이름을 변경했습니다.
(2)
OrderCoffee 클래스는 주문 애그리거트 내에 있는 엔티티 클래스입니다.
COFFEE 클래스는 커피 애그리거트 내에 있는 엔티티 클래스이자 애그리거트 루트입니다.
따라서 애그리거트 간의 매핑 규칙을 따르기 때문에 Member 클래스와 Order 클래스에서 했던 것처럼 coffeeId를 외래키처럼 추가합니다.
Member와 Order는 memberId 필드를 Order에 추가하면 되니 어렵지 않을거라 생각합니다.
그런데 N대 N의 관계는 꽤나 복잡해 보입니다. 단계적인 설명이 더 어렵게 느껴졌을지 모르지만 단순하게 생각하길 바랍니다.
✅ 기억하세요!
- N대 N의 관계를 —> 1대 N, N대 1의 관계로 변경
- 1대 N, N대 1의 관계를 OrderCoffee 같이 중간에서 ID를 참조하게 해주는 클래스를 통해 다시 1대 N대1의 관계로 변경
✔ Order 클래스의 멤버 변수 추가
import com.springboot.member.entity.Member;
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.MappedCollection;
import org.springframework.data.relational.core.mapping.Table;
import java.time.LocalDateTime;
import java.util.LinkedHashSet;
import java.util.Set;
@Getter
@Setter
@Table("ORDERS")
public class Order {
@Id
private long orderId;
// 테이블 외래키처럼 memberId를 추가한다.
private long memberId;
@MappedCollection(idColumn = "ORDER_ID")
private Set<OrderCoffee> orderCoffees = new LinkedHashSet<>();
// (1)
private OrderStatus orderStatus = OrderStatus.ORDER_REQUEST;
// (2)
private LocalDateTime createdAt = LocalDateTime.now();
// (3)
public enum OrderStatus {
ORDER_REQUEST(1, "주문 요청"),
ORDER_CONFIRM(2, "주문 확정"),
ORDER_COMPLETE(3, "주문 완료"),
ORDER_CANCEL(4, "주문 취소");
@Getter
private int stepNumber;
@Getter
private String stepDescription;
OrderStatus(int stepNumber, String stepDescription) {
this.stepNumber = stepNumber;
this.stepDescription = stepDescription;
}
}
}[코드 3-88] Order 엔티티 클래스 (Order.java)
코드 3-88은 Order 클래스의 전체 코드입니다. 이 중에서 엔티티 매핑 관련 코드 이외에 추가된 코드를 간단히 살펴보도록 하겠습니다.
(1) 주문 상태 정보
(1)은 주문 상태 정보를 나타내는 멤버 변수이며, OrderStatus enum타입입니다.
주문 정보가 저장될 때 기본 값은 ORDER_REQUEST (주문 요청)입니다.
(2) 주문 등록 시간
(2)는 주문이 등록되는 시간 정보를 나타내는 멤버 변수이며, LocalDateTime 타입입니다.
(3) OrderStatus enum
주문의 상태를 나타내는 enum입니다. 총 네 개의 주문 상태를 가지고 있습니다.
OrderStatus enum이 Order 클래스의 멤버로 포함이 되어 있는 이유는 OrderStatus는 주문을 위한 전용 상태 값으로 사용할 수 있기 때문입니다.
만약 OrderStatus가 다른 기능에서도 사용할 가능성이 있다면 클래스 외부로 분리시킬 수 있겠지만 현재로서는 특별히 그럴 이유가 없기 때문에 Order 클래스의 멤버로 존재하는 것이 적절하다고 생각합니다.
✔ 테이블 생성 스크립트 추가
마지막으로 src/main/resources/db/h2/schema.sql ’ 파일에 테이블 생성 스크립트를 추가해서 애플리케이션 실행 시, 테이블이 생성되도록 합니다.
CREATE TABLE IF NOT EXISTS MEMBER (
MEMBER_ID bigint NOT NULL AUTO_INCREMENT,
EMAIL varchar(100) NOT NULL UNIQUE,
NAME varchar(100) NOT NULL,
PHONE varchar(100) NOT NULL,
PRIMARY KEY (MEMBER_ID)
);
CREATE TABLE IF NOT EXISTS COFFEE (
COFFEE_ID bigint NOT NULL AUTO_INCREMENT,
KOR_NAME varchar(100) NOT NULL,
ENG_NAME varchar(100) NOT NULL,
PRICE int NOT NULL,
COFFEE_CODE char(3) NOT NULL,
PRIMARY KEY (COFFEE_ID)
);
CREATE TABLE IF NOT EXISTS ORDERS (
ORDER_ID bigint NOT NULL AUTO_INCREMENT,
MEMBER_ID bigint NOT NULL,
ORDER_STATUS varchar(20) NOT NULL,
CREATED_AT datetime NOT NULL,
PRIMARY KEY (ORDER_ID),
FOREIGN KEY (MEMBER_ID) REFERENCES MEMBER(MEMBER_ID)
);
CREATE TABLE IF NOT EXISTS ORDER_COFFEE (
ORDER_COFFEE_ID bigint NOT NULL AUTO_INCREMENT,
ORDER_ID bigint NOT NULL,
COFFEE_ID bigint NOT NULL,
QUANTITY int NOT NULL,
PRIMARY KEY (ORDER_COFFEE_ID),
FOREIGN KEY (ORDER_ID) REFERENCES ORDERS(ORDER_ID),
FOREIGN KEY (COFFEE_ID) REFERENCES COFFEE(COFFEE_ID)
);[코드 3-89] 커피 주문 샘플 애플리케이션의 테이블 생성 스크립트 (schema.sql)
일반적으로 로컬 환경에서 개발 시, 인메모리(In-memory) DB를 사용하지 않는다면 테스트가 용이하도록 애플리케이션 실행 시, 모든 테이블을 DROP 했다가 다시 생성할 필요가 있습니다.
그런데 우리는 인메모리(In-memory) DB를 사용하기 때문에 애플리케이션을 중지하고 재가동하면 테이블 자체가 메모리에서 사라지므로 별도의 테이블 DROP 과정은 필요 없다는 사실을 기억하면 좋을 것 같습니다.
이제 엔티티 클래스에 대한 정의가 끝났습니다.
다음 챕터에서 서비스 클래스와 데이터 액세스 계층의 리포지토리(Repository) 클래스를 구현해 보도록 하겠습니다.
핵심 포인트
- 테이블 간의 관계는 외래키를 통해서 이루어지며, 클래스들 간의 관계는 해당 클래스의 객체 참조를 통해서 이루어진다.
- AggregateReference 클래스는 다른 애그리거트 루트 간의 참조 역할을 한다.
- AggregateReference 클래스는 테이블의 외래키처럼 다른 객체의 ID 값을 참조할 수 있도록 해준다.
- 애그리거트 객체 매핑 규칙
- 모든 엔티티 객체의 상태는 애그리거트 루트를 통해서만 변경할 수 있다.
- 하나의 동일한 애그리거트 내에서의 엔티티 객체 참조
- 동일한 하나의 애그리거트 내에서는 엔티티 간에 객체로 참조한다.
- 애그리거트 루트 대 애그리거트 루트 간의 엔티티 객체 참조
- 애그리거트 루트 간의 참조는 객체 참조 대신에 ID로 참조한다.
- 즉, 테이블 간의 외래키 방식과 동일하다.
- AggregateReference 를 사용함으로써 애그리거트 루트 간의 참조를 명시적으로 표현할 수 있다.
- 애그리거트 루트 간의 참조는 객체 참조 대신에 ID로 참조한다.
심화 학습
- AggregateReference에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- @MappedCollection에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
[기본] Spring Data JDBC를 통한 데이터 액세스 계층 구현(2) - 서비스, 리포지토리 구현
지난 챕터에서 커피 주문 샘플 애플리케이션 Spring Data JDBC 기술을 사용하기 위해 도메인 엔티티 클래스에 대한 정의를 했습니다.
이제 이 도메인 엔티티 클래스를 이용해 서비스 클래스와 리포지토리(Repository) 클래스를 구현해 봅시다.
서비스 클래스가 리포지토리 클래스를 사용하는 입장이기 때문에 리포지토리(Repository) 인터페이스에 대해서 먼저 설명하는 것이 여러분들의 이해를 도울 것 같습니다.
Spring Data JDBC, Spring Data JPA에서는 데이터 액세스 계층에서 데이터베이스와 상호작용하는 역할을 하는 인터페이스를 리포지토리(Repository)라고 합니다.
이 리포지토리(Repository)라는 용어는 DDD(Domain Driven Design, 도메인 주도 설계)에서 사용하는 용어입니다.
리포지토리(Repository) 인터페이스 정의
커피 주문을 하기 위해서는 회원 정보, 커피 정보, 주문 정보가 모두 필요하므로 이 세 개 정보를 모두 저장 및 조회할 수 있도록 각각의 리포지토리 인터페이스를 정의해 보겠습니다.
✔ MemberRepository 인터페이스 코드
import com.springboot.member.entity.Member;
import org.springframework.data.repository.CrudRepository;
import java.util.Optional;
// (1)
public interface MemberRepository extends CrudRepository<Member, Long> {
// (2)
Optional<Member> findByEmail(String email);
}[코드 3-90] MemberRepository 인터페이스(MemberRepository.java)
코드 3-90은 MemberRepository 인터페이스의 코드입니다.
Spring Data JDBC에서는 CrudRepository라는 인터페이스를 제공해주고 있으며, 이 CrudRepository의 기능을 사용하기 위해서 MemberRepository가 CrudRepository를 상속하고 있습니다.
우리는 이 CrudRepository 인터페이스를 통해서 편리하게 데이터를 데이터베이스의 테이블에 저장, 조회, 수정, 삭제할 수 있습니다.
✔ MemberRepository 코드 설명
- (1)의 CrudRepository<Member, Long>에서 Member는 Member 엔티티 클래스를 가리키며, Long은 Member 엔티티 클래스에서 @Id 애너테이션이 붙은 멤버 변수의 타입을 가리킵니다.
- (2)는 Spring Data JDBC에서 지원하는 쿼리 메서드(Query Method) 정의를 이용한 데이터 조회 메서드를 정의했습니다.(2)에서 정의한 쿼리 메서드(Query Method)는 내부적으로 아래의 SQL 쿼리문으로 변환되어 데이터베이스의 MEMBER 테이블에 질의를 보냅니다.(2)의 쿼리 메서드는 이미 테이블에 등록된 이메일 주소가 있는지 확인하기 위한 용도로 사용합니다.
- SELECT "MEMBER"."NAME" AS "NAME", "MEMBER"."PHONE" AS "PHONE", "MEMBER"."EMAIL" AS "EMAIL", "MEMBER"."MEMBER_ID" AS "MEMBER_ID" FROM "MEMBER" **WHERE "MEMBER"."EMAIL" = ?
- ✅ Spring Data JDBC에서는 ‘find + By + SQL 쿼리문에서 WHERE 절의 열명 + (WHERE 절 열의 조건이 되는 데이터) ’ 형식으로 쿼리 메서드(Query Method)를 정의하면 조건에 맞는 데이터를 테이블에서 조회합니다. (2)에서는 email 열을 WHERE 절의 조건으로 지정해서 MEMBER 테이블에서 하나의 row를 조회하겠다고 정의했습니다.
- (2)의 리턴값으로 SQL 질의를 통한 결과 데이터를 Member 엔티티 클래스의 객체로 지정했습니다. 주목할 부분은 Spring Data JDBC에서는 Optional을 지원하기 때문에 리턴값을 Optional로 래핑 할 수 있다는 사실을 기억하길 바랍니다.
- 이처럼 리턴값에 Optional을 사용하면 서비스 클래스에서 이 Optional을 이용해 코드를 좀 더 효율적이면서 간결하게 구성할 수 있습니다.
쿼리 메서드(Query Method)
Spring Data JDBC에서는 쿼리 메서드를 이용해서 SQL 쿼리문을 사용하지 않고 데이터베이스에 질의를 할 수 있습니다.
기본적인 사용법은 ‘find + By + SQL 쿼리문에서 WHERE 절의 열명 + (WHERE 절 열의 조건이 되는 데이터) ’ 형식이며, WHERE 절의 조건 열을 여러 개 지정하고 싶다면 ‘And’를 사용하면 됩니다.
예를 들어 EMAIL 열과 NAME 열을 조건으로 지정하고 싶다면, findByEmailAndName(String email, String name)과 같이 쿼리 메서드를 정의하면 됩니다.
✅ 주의해야 되는 부분은 findByxxxx에서 사용하는 열명은 내부적으로는 테이블의 열명으로 변경되지만 Spring JDBC 입장에서는 엔티티 클래스를 바라보고 작업을 하기 때문에 반드시 엔티티 클래스의 멤버 변수명을 적어주어야 한다는 것입니다.
만약 Member 엔티티 클래스에 firstName이라는 멤버 변수가 있고, 테이블에 있는 FIRST_NAME이라는 열명과 매핑이 된다고 가정할 경우, 쿼리메서드는 findByFirstName이 되어야지 findByFIRST_NAME이 되어서는 안 된다는 의미입니다.
이런 규칙이 헷갈린다면 엔티티 클래스의 멤버 변수명과 테이블 열명을 일치시키는 것이 가장 좋지만 두 단어 이상 조합이 될 경우 일반적으로 Java에서는 Carmel Case 표기법을 사용하고 테이블 열명은 언더스코어( _ ) 표기법을 사용하는 경우가 많음을 참고하기 바랍니다.
쿼리 메서드에 대한 더 자세한 내용은 아래 [심화 학습]을 참고하세요.
✔ CoffeeRepository 인터페이스 코드
import com.springboot.coffee.entity.Coffee;
import org.springframework.data.jdbc.repository.query.Query;
import org.springframework.data.repository.CrudRepository;
import java.util.Optional;
public interface CoffeeRepository extends CrudRepository<Coffee, Long> {
// (1)
Optional<Coffee> findByCoffeeCode(String coffeeCode);
// (2)
@Query("SELECT * FROM COFFEE WHERE COFFEE_ID = :coffeeId")
Optional<Coffee> findByCoffee(Long coffeeId);
}[코드 3-91] CoffeeRepository 인터페이스(CoffeeRepository.java)
코드 3-91은 CoffeeRepository 인터페이스의 코드입니다.
✔ CoffeeRepository 코드 설명
- (1)은 WHERE 절에서 COFFEE_CODE를 조건으로 질의하게 해주는 쿼리 메서드입니다.
- (2)에서는 COFFEE 테이블에 질의하기 위해 @Query라는 애너테이션을 사용했습니다.@Query에 작성된 쿼리문에서 :coffeeId는 findByCoffeeId(Long coffeeId)의 coffeeId 변수 값이 채워지는 동적 쿼리 파라미터(named parameter)입니다.
- @Query 애너테이션은 쿼리 메서드명을 기준으로 SQL 쿼리문을 생성하는 것이 아니라 개발자가 직접 쿼리문을 작성해서 질의를 할 수 있도록 해줍니다.
@Query 애너테이션을 이용하면 SQL 쿼리문을 직접 작성할 수 있기 때문에 복잡한 쿼리문의 경우 @Query 애너테이션을 이용해서 직접 쿼리문을 작성할 수 있습니다.
하지만 단순한 쿼리의 경우 Spring Data JDBC에서 지원하는 Query Method를 정의해서 사용하는 것이 간결한 코드 유지와 생산성 면에서 바람직하다고 생각합니다.
코드 3-91 (2)의 경우 여러분들에게 쿼리로 작성하는 방법이 있다는 것을 보여주기 위해서 쿼리문을 직접 작성한 것이고, 실제로는 CrudRepository 인터페이스에 내장되어 있는 findById(ID id)를 사용하면 됩니다.
findById(ID id)는 테이블에서 기본키를 WHERE절의 조건으로 지정해 데이터를 조회할 수 있는 편리한 쿼리메서드입니다.
✔ OrderRepository 인터페이스 코드
import com.springboot.order.entity.Order;
import org.springframework.data.repository.CrudRepository;
public interface OrderRepository extends CrudRepository<Order, Long> {
}[코드 3-92] OrderRepository 인터페이스(OrderRepository.java)
코드 3-92는 OrderRepository 인터페이스의 코드입니다.
보다시피 앞에서 보았던 MemberRepository나 CoffeeRepository에는 작성된 쿼리 메서드가 있었는데 OrderRepository는 작성된 쿼리메서드가 없습니다.
코드 3-92처럼 이렇게 코드 없이 비워둘 거면 뭐 하러 작성하냐라고 생각하는 분들이 있을지도 모르지만 OrderRepository 인터페이스는 CrudRepository 인터페이스를 상속하기 때문에 CrudRepository에 이미 정의되어 있는 기본 쿼리메서드를 서비스 클래스에서 사용할 수 있습니다.
서비스(Service) 클래스 구현
서비스 클래스는 Spring Data JDBC 기술이 적용된 Repository 인터페이스를 사용하도록 메서드의 코드가 모두 수정되었습니다.
설명할 내용들이 상당히 많지만 여러분들이 천천히 잘 따라올 거라 믿습니다.
✔ MemberService 코드
@Service
public class MemberService {
private MemberRepository memberRepository;
// (1) MemberRepository DI
public MemberService(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
public Member createMember(Member member) {
// (2) 이미 등록된 이메일인지 검증
verifyExistsEmail(member.getEmail());
// (3) 회원 정보 저장
return memberRepository.save(member);
}
public Member updateMember(Member member) {
// (4) 존재하는 회원인지 검증
Member findMember = findVerifiedMember(member.getMemberId());
// (5) 이름 정보와 휴대폰 번호 정보 업데이트
Optional.ofNullable(member.getName())
.ifPresent(name -> findMember.setName(name));
Optional.ofNullable(member.getPhone())
.ifPresent(phone -> findMember.setPhone(phone));
// (6) 회원 정보 업데이트
return memberRepository.save(findMember);
}
// (7) 특정 회원 정보 조회
public Member findMember(long memberId) {
return findVerifiedMember(memberId);
}
public List<Member> findMembers() {
// (8) 모든 회원 정보 조회
return (List<Member>) memberRepository.findAll();
}
public void deleteMember(long memberId) {
Member findMember = findVerifiedMember(memberId);
// (9) 특정 회원 정보 삭제
memberRepository.delete(findMember);
}
// (10) 이미 존재하는 회원인지를 검증
public Member findVerifiedMember(long memberId) {
Optional<Member> optionalMember =
memberRepository.findById(memberId);
Member findMember =
optionalMember.orElseThrow(() ->
new BusinessLogicException(ExceptionCode.MEMBER_NOT_FOUND));
return findMember;
}
// (11) 이미 등록된 이메일 주소인지 검증
private void verifyExistsEmail(String email) {
Optional<Member> member = memberRepository.findByEmail(email);
if (member.isPresent())
throw new BusinessLogicException(ExceptionCode.MEMBER_EXISTS);
}
}[코드 3-93] MemberService(MemberService.java)
코드 3-93은 MemberRepository 인터페이스를 이용하도록 수정된 MemberService 클래스의 코드입니다.
- MemberRepository 인터페이스를 이용해야 되므로 (1)과 같이 생성자를 통해 MemberRepository 인터페이스를 DI 받습니다.
- ✅ 그런데 신기한 건 우리가 MemberRepository 인터페이스는 정의했지만 인터페이스의 구현 클래스는 별도로 구현을 한 적이 없습니다. 이 MemberRepository 인터페이스의 구현 클래스는 누가 구현을 하는 걸까요? 바로 Spring Data JDBC에서 내부적으로 Java의 리플렉션 기술과 Proxy 기술을 이용해서 MemberRepository 인터페이스의 구현 클래스 객체를 생성해 줍니다.
- (2)에서는 회원 정보를 저장하기 전에 테이블에 이미 등록된 이메일인지 여부를 검증하기 위해 (11)의 verifyExistsEmail(String email) 메서드를 사용하고 있습니다.✅ (2)와 같이 비즈니스 로직에서 어떤 검증이 필요한 로직은 (11)의 verifyExistsEmail(String email)와 같이 별도의 로직으로 추출해서 검증 메서드에 검증을 해달라고 요청하는 것이 코드의 간결성과 가독성을 향상하는 기본적인 방법 중 하나입니다.
- 다른 누군가가 이 코드를 보면서 유지보수를 하게 된다면 코드 상에서의 비즈니스 로직이 어떤 식으로 이루어지는지 직관적으로 알 수 있습니다.
- (11)의 verifyExistsEmail(String email) 메서드에서는 MemberRepository에 정의되어 있는 findByEmail() 쿼리 메서드로 이메일에 해당하는 회원이 있는지를 조회합니다. findByEmail() 쿼리 메서드의 리턴값이 Optional이기 때문에 isPresent()를 통해 결과 값이 존재한다면 예외를 던지도록 구현했습니다.
- (2)에서 이메일에 대한 검증이 끝났으므로, (3)에서 회원 정보를 저장합니다.
- (4)에서는 회원 정보를 수정하기 전에 수정하려는 회원 정보가 테이블에 존재하는지 여부를 검증하고 있습니다.
- (5)에서는 회원 존재 여부 검증에 통과한 회원이라면 이름과 주소 정보를 setter 메서드를 통해 변경합니다.이처럼 멤버 변수 값이 null일 경우에는 Optional.of()가 아닌 Optional.ofNullable()을 이용해서 null 값을 허용할 수 있습니다.수정할 값이 있다면(name 또는 phone 멤버 변수의 값이 null이 아니라면) ifPresent() 메서드 내의 코드가 실행이 되고, 수정할 값이 없다면 (name 또는 phone 멤버 변수의 값이 null이라면) 아무 동작도 하지 않습니다.
- 따라서 값이 null이더라도 NullPointerException이 발생하지 않고, 다음 메서드인 ifPresent() 메서드를 호출할 수 있습니다.
- ✅ Optional.ofNullable(…)을 사용하는 이유 파라미터로 전달받은 member 객체는 클라이언트 쪽에서 사용자가 이름 정보나 휴대폰 정보를 선택적으로 수정할 수 있기 때문에 name 멤버 변수가 null일 수 도 있고, phone 멤버 변수가 null일 수도 있습니다.
- (6)에서는 name 또는 phone 멤버 변수의 수정된 값이 적용되어 테이블에서 회원 정보를 업데이트합니다.반면에 @Id 애너테이션이 추가된 엔티티 클래스의 멤버 변수 값이 0 또는 null이 아니라면 이미 테이블에 존재하는 데이터라고 판단하여 테이블에 update 쿼리를 전송합니다.
- 따라서 이미 테이블에 존재하는 회원 정보를 테이블에서 조회한 findMember 객체에서 name 또는 phone 멤버 변수만 setter 메서드로 값을 변 경하는 방식을 이용해서 테이블에 update 쿼리를 보내게 됩니다.
- ✅ Spring Data JDBC에서는 @Id 애너테이션이 추가된 엔티티 클래스의 멤버 변수 값이 0 또는 null이면 신규 데이터라고 판단하여 테이블에 insert 쿼리를 전송합니다.
- (7)에서는 memberId에 해당하는 특정 회원을 조회합니다.
- (8)에서는 테이블에 존재하는 모든 회원 정보를 조회합니다. findAll() 메서드의 리턴값이 Iterable<T>이기 때문에 List<Member>로 캐스팅했습니다.
- (9)에서는 특정 회원 정보를 삭제합니다.
- ✅ (9)에서는 학습을 위해 회원 정보 자체를 테이블에서 삭제했지만 실무에서는 테이블의 데이터 자체를 삭제하기보다는 MEMBER_STATUS 같은 열을 두어 상태 값만 변경한다는 것을 기억하길 바랍니다. 회원의 회원 가입 상태를 ‘가입’, ‘휴면’, ‘탈퇴’ 등의 상태 정보로 나누어서 관리하는 것이 바람직합니다. 엔티티의 상태를 관리하는 부분은 Order 엔티티에서 설명했으므로 참고하기 바랍니다.
- (10)은 이미 존재하는 회원인지를 검증한 후, 검증된 회원 정보를 리턴해주는 기능을 합니다. optionalMember.orElseThrow(() -> new BusinessLogicException(ExceptionCode.MEMBER_NOT_FOUND));에서 orElseThorow()는 optionalMember 객체가 null 이 아니라면 해당 객체를 리턴하고 null이라면 예외를 던집니다.
- (11)은 이미 등록된 이메일이 존재하는지를 검증해 주는 기능을 합니다.
✔ CoffeeService 코드
import com.springboot.coffee.CoffeeRepository;
import com.springboot.coffee.entity.Coffee;
import com.springboot.exception.BusinessLogicException;
import com.springboot.exception.ExceptionCode;
import com.springboot.order.entity.Order;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
@Service
public class CoffeeService {
private CoffeeRepository coffeeRepository;
public CoffeeService(CoffeeRepository coffeeRepository) {
this.coffeeRepository = coffeeRepository;
}
public Coffee createCoffee(Coffee coffee) {
// (1) 커피 코드를 대문자로 변경
String coffeeCode = coffee.getCoffeeCode().toUpperCase();
// 이미 등록된 커피 코드인지 확인
verifyExistCoffee(coffeeCode);
coffee.setCoffeeCode(coffeeCode);
return coffeeRepository.save(coffee);
}
public Coffee updateCoffee(Coffee coffee) {
// 조회하려는 커피가 검증된 커피인지 확인(존재하는 커피인지 확인 등)
Coffee findCoffee = findVerifiedCoffee(coffee.getCoffeeId());
Optional.ofNullable(coffee.getKorName())
.ifPresent(korName -> findCoffee.setKorName(korName));
Optional.ofNullable(coffee.getEngName())
.ifPresent(engName -> findCoffee.setEngName(engName));
Optional.ofNullable(coffee.getPrice())
.ifPresent(price -> findCoffee.setPrice(price));
return coffeeRepository.save(findCoffee);
}
public Coffee findCoffee(long coffeeId) {
return findVerifiedCoffeeByQuery(coffeeId);
}
// (2) 주문에 해당하는 커피 정보 조회
public List<Coffee> findOrderedCoffees(Order order) {
return order.getOrderCoffees()
.stream()
.map(orderCoffee -> findCoffee(orderCoffee.getCoffeeId()))
.collect(Collectors.toList());
}
public List<Coffee> findCoffees() {
return (List<Coffee>) coffeeRepository.findAll();
}
public void deleteCoffee(long coffeeId) {
Coffee coffee = findVerifiedCoffee(coffeeId);
coffeeRepository.delete(coffee);
}
public Coffee findVerifiedCoffee(long coffeeId) {
Optional<Coffee> optionalCoffee = coffeeRepository.findById(coffeeId);
Coffee findCoffee =
optionalCoffee.orElseThrow(() ->
new BusinessLogicException(ExceptionCode.COFFEE_NOT_FOUND));
return findCoffee;
}
private void verifyExistCoffee(String coffeeCode) {
Optional<Coffee> coffee = coffeeRepository.findByCoffeeCode(coffeeCode);
if(coffee.isPresent())
throw new BusinessLogicException(ExceptionCode.COFFEE_CODE_EXISTS);
}
private Coffee findVerifiedCoffeeByQuery(long coffeeId) {
Optional<Coffee> optionalCoffee = coffeeRepository.findByCoffee(coffeeId);
Coffee findCoffee =
optionalCoffee.orElseThrow(() ->
new BusinessLogicException(ExceptionCode.COFFEE_NOT_FOUND));
return findCoffee;
}
}[코드 3-94] CoffeeService(CoffeeService .java)
코드 3-94는 CoffeeRepository 인터페이스를 이용하도록 수정된 CoffeeService 클래스의 코드입니다.
- (1)에서는 영문으로 구성된 커피 코드(CoffeeCode)를 대문자로 변경하고 있습니다.결과적으로 (1)은 사용자가 대소문자에 신경 쓰지 않고 입력할 수 있도록 사용자 편의성을 높여주는 기능을 합니다.
- 커피 코드의 경우는 클라이언트 쪽에서 사용자가 대소문자를 가리지 않고 입력하더라도 (1)에서 일괄적으로 대문자로 변경하도록 했습니다.
- (2)는 주문한 커피 정보를 조회하는 메서드입니다.✅ (2)의 findOrderedCoffees(Order order) 메서드의 리턴값은 OrderResponseDto 클래스에 포함되는데 이 부분은 뒤에서 다시 설명하도록 하겠습니다.
- Order 객체는, memberId와 orderStatus 값만 얻을 수 있지 실제 회원이 주문한 커피 정보는 얻을 수 없습니다. 따라서 getOrderCoffees()를 통해서 주문한 구체적인 커피 정보를 얻어와야 합니다.
나머지 코드들은 MemberService 코드에서 설명한 내용과 같은 형식의 코드 구성이기 때문에 별도의 설명은 생략하도록 하겠습니다.
✔ OrderService 코드
import com.springboot.coffee.service.CoffeeService;
import com.springboot.exception.BusinessLogicException;
import com.springboot.exception.ExceptionCode;
import com.springboot.member.service.MemberService;
import com.springboot.order.entity.Order;
import com.springboot.order.repository.OrderRepository;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
@Service
public class OrderService {
final private OrderRepository orderRepository;
final private MemberService memberService;
final private CoffeeService coffeeService;
public OrderService(OrderRepository orderRepository,
MemberService memberService,
CoffeeService coffeeService) {
this.orderRepository = orderRepository;
this.memberService = memberService;
this.coffeeService = coffeeService;
}
public Order createOrder(Order order) {
// (1) 회원이 존재하는지 확인
memberService.findVerifiedMember(order.getMemberId());
// (2) 커피가 존재하는지 조회해야 됨
order.getOrderCoffees()
.stream()
.forEach(orderCoffee -> {
coffeeService.findVerifiedCoffee(orderCoffee.getCoffeeId());
});
return orderRepository.save(order);
}
public Order findOrder(long orderId) {
return findVerifiedOrder(orderId);
}
public List<Order> findOrders() {
return (List<Order>) orderRepository.findAll();
}
// (3)
public void cancelOrder(long orderId) {
Order findOrder = findVerifiedOrder(orderId);
int step = findOrder.getOrderStatus().getStepNumber();
// (4) OrderStatus의 step이 2미만일 경우(ORDER_CONFIRM)에만 주문취소가 되도록한다.
if (step >= 2) {
throw new BusinessLogicException(ExceptionCode.CANNOT_CHANGE_ORDER);
}
// (5)
findOrder.setOrderStatus(Order.OrderStatus.ORDER_CANCEL);
orderRepository.save(findOrder);
}
private Order findVerifiedOrder(long orderId) {
Optional<Order> optionalOrder = orderRepository.findById(orderId);
Order findOrder =
optionalOrder.orElseThrow(() ->
new BusinessLogicException(ExceptionCode.ORDER_NOT_FOUND));
return findOrder;
}
}[코드 3-95] OrderService(OrderService .java)
코드 3-95는 OrderRepository 인터페이스를 이용하도록 수정된 OrderService 클래스의 코드입니다.
- 주문 정보가 저장되기 전에는 주문 정보에 포함된 회원이 존재하는 회원인지 (1)과 같이 검증할 필요가 있습니다.
- 또한 주문하려는 커피 정보 역시 테이블에 존재하는지 (2)와 같이 검증해 주어야 합니다.
- 주문하려는 커피가 존재하는지 여부는 (2)와 같이 order.getOrderCoffees()를 통해서 Set<OrderCoffee>를 가져온 후, Java의 Stream으로 각각의 coffeeId를 얻은 후에 findVerifiedCoffee(orderCoffee.getCoffeeId()) 메서드를 통해 coffeeId에 해당하는 커피 정보가 유효한지 검증합니다.
- (3)에서는 주문 정보를 취소합니다.
- 일반적으로 커피 주문이 확정되면 커피 주문을 취소할 수 없어야 될 것입니다. 커피 주문 확정이라는 상태는 이미 커피를 만들고 있을 테니까요.
- 따라서 (4)와 같이 OrderStatus가 주문 요청(ORDER_REQUEST) 단계를 넘어가면 주문 정보를 변경할 수 없도록 하며, 주문 요청(ORDER_REQUEST) 단계까지만 (5)와 같이 주문을 취소할 수 있도록 합니다.
나머지 코드들은 MemberService, CoffeeService 클래스에서 살펴본 코드들이므로 설명은 생략하겠습니다.
기타 이번 챕터에서 수정된 코드
서비스 클래스와 리포지토리 클래스 이외에도 서비스 클래스를 사용하는 Controller 클래스, 이와 연관된 DTO 클래스, Mapper 인터페이스 등도 수정된 부분이 존재합니다.
✔ CoffeePostDto 코드
@Getter
public class CoffeePostDto {
@NotBlank
private String korName;
@NotBlank
@Pattern(regexp = "^([A-Za-z])(\\\\s?[A-Za-z])*$",
message = "커피명(영문)은 영문이어야 합니다(단어 사이 공백 한 칸 포함). 예) Cafe Latte")
private String engName;
@Range(min= 100, max= 50000)
private int price;
@NotBlank
@Pattern(regexp = "^([A-Za-z]){3}$",
message = "커피 코드는 3자리 영문이어야 합니다.")
private String coffeeCode;
}[코드 3-95-1] 커피 코드가 추가된 CoffeePostDto(OrderPostDto.java)
커피 코드가 추가되었습니다. 커피 코드는 커피라는 상품의 고유 식별 코드를 의미합니다.
✔ OrderController 코드
package com.springboot.order.controller;
import com.springboot.coffee.service.CoffeeService;
import com.springboot.order.dto.OrderPostDto;
import com.springboot.order.dto.OrderResponseDto;
import com.springboot.order.entity.Order;
import com.springboot.order.mapper.OrderMapper;
import com.springboot.order.service.OrderService;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.util.UriComponentsBuilder;
import javax.validation.Valid;
import javax.validation.constraints.Positive;
import java.net.URI;
import java.util.List;
import java.util.stream.Collectors;
import static java.util.Comparator.comparing;
@RestController
@RequestMapping("/v10/orders")
@Validated
public class OrderController {
private final static String ORDER_DEFAULT_URL = "/v10/orders"; // (1) Default URL 경로
private final OrderService orderService;
private final OrderMapper mapper;
private final CoffeeService coffeeService;
public OrderController(OrderService orderService,
OrderMapper mapper,
CoffeeService coffeeService) {
this.orderService = orderService;
this.mapper = mapper;
this.coffeeService = coffeeService;
}
@PostMapping
public ResponseEntity postOrder(@Valid @RequestBody OrderPostDto orderPostDto) {
Order order = orderService.createOrder(mapper.orderPostDtoToOrder(orderPostDto));
// (2) 등록된 주문(Resource)에 해당하는 URI 객체
URI location =
UriComponentsBuilder
.newInstance()
.path(ORDER_DEFAULT_URL + "/{order-id}")
.buildAndExpand(order.getOrderId())
.toUri(); // "/v10/orders/{order-id}"
return ResponseEntity.created(location).build(); // (3) HTTP 201 Created status
}
@GetMapping("/{order-id}")
public ResponseEntity getOrder(@PathVariable("order-id") @Positive long orderId){
Order order = orderService.findOrder(orderId);
// (4) 주문한 커피 정보를 가져오도록 수정
return new ResponseEntity<>(
mapper.orderToOrderResponseDto(coffeeService, order),
HttpStatus.OK);
}
@GetMapping
public ResponseEntity getOrders() {
List<Order> orders = orderService.findOrders();
// (5) 주문한 커피 정보를 가져오도록 수정
List<OrderResponseDto> response =
orders
.stream()
.map(order -> mapper.orderToOrderResponseDto(coffeeService, order))
.collect(Collectors.toList());
return new ResponseEntity<>(response, HttpStatus.OK);
}
@DeleteMapping("/{order-id}")
public ResponseEntity cancelOrder(@PathVariable("order-id") @Positive long orderId){
orderService.cancelOrder(orderId);
return new ResponseEntity<>(HttpStatus.NO_CONTENT);
}
}[코드 3-96] Spring Data JDBC 적용으로 인해 수정된 OrderController(OrderController.java)
- postOrder() 핸들러 메서드의 수정 내용 설명
- 우리가 이 전 유닛까지는 데이터베이스를 연동하지 않았기 때문에 주문 정보 등록 시, OrderController에서 OrderService의 createOrder(order)를 호출해 등록할 주문을 전달하고, 이렇게 전달한 Order 객체를 createOrder(order)의 리턴 값으로 그대로 리턴하도록 했습니다.
- 그런데 이제는 상황이 다릅니다. 등록할 주문 정보는 데이터베이스에 저장이 되고, ORDER 테이블에 하나의 row로 저장이 됩니다. 즉, ORDER_ID라는 고유한 식별자(기본키)를 가지는 진정한 주문 정보로써의 역할을 하게 됩니다.
- 일반적으로 클라이언트 측에서 백엔드 애플리케이션 측에 어떤 리소스(회원 정보, 커피 정보, 주문 정보 등)의 등록을 요청할 경우, 백엔드 애플리케이션은 해당 리소스를 데이터베이스에 저장한 후 요청한 리소스가 성공적으로 저장되었음을 알리는 201 Created HTTP Status를 response header에 추가해서 클라이언트 측에 응답으로 전달합니다.
- 클라이언트 측에서는 response header에 포함된 리소스의 위치 정보(Location)를 얻은 후에 해당 리소스의 URI로 다시 요청을 전송해서 리소스의 정보를 얻어옵니다.
- (1)에서 리소스(주문 정보)의 디폴트 URL을 정의합니다.
- (2)에서 UriComponentsBuilder를 이용해 등록된 리소스(주문 정보)의 위치 정보인 URI 객체를 생성합니다.
- (3)에서 ResponseEntity.*created*(location).build();를 이용해 응답 객체를 리턴합니다.
- ResponseEntity.*created*(location) 메서드는 내부적으로 201 Created HTTP Status를 response header에 추가하고, 별도의 response body는 포함하지 않습니다.

[그림 3-49-1] 등록된 주문 정보의 Location 정보가 response header에 포함된 모습
[그림 3-49-1]은 postOrder() request를 전송할 경우의 response의 모습입니다. 보다시피 201 Created HTTP Status이고, 등록된 주문 정보의 위치 정보가 Location header에 포함되어 있습니다.
⭐ 백엔드 애플리케이션 측에 리소스를 등록할 경우에는 등록된 리소스의 정보를 응답으로 리턴할 필요가 없다는 사실을 기억하기 바랍니다.
- 그 외 (4), (5)에서는 주문한 커피 정보가 OrderResponseDto에 포함되도록 수정되었습니다.
- CoffeeService 객체를 CoffeeMapper 매핑 메서드의 파라미터로 넘겨줌으로써 내부적으로 주문한 커피 정보를 OrderResponseDto에 포함시킬 수 있습니다.
MemberController와 CoffeeController의 수정된 코드는 OrderController와 로직 자체는 동일하므로, 자세한 코드 변경 사항은 레퍼런스 코드(https://github.com/Lucky-kor/be-reference-spring-data-jdbc)를 확인 바랍니다.
✔ OrderPostDto 코드
@Getter
@AllArgsConstructor
public class OrderPostDto {
@Positive
private long memberId;
// (1) 여러 잔의 커피를 주문할 수 있도록 수정
@Valid
private List<OrderCoffeeDto> orderCoffees;
}[코드 3-97] Spring Data JDBC 적용으로 인해 수정된 OrderPostDto(OrderPostDto.java)
(1)과 같이 여러 잔의 커피를 주문할 수 있도록 수정되었습니다. List안에 포함된 객체에 대한 유효성 검증을 위해서는 (1)과 같이 @Valid 애너테이션을 추가해 주면 됩니다.
✔ OrderCoffeeDto 클래스 추가
@Getter
@AllArgsConstructor
public class OrderCoffeeDto {
@Positive
private long coffeeId;
@Positive
private int quantity;
}[코드 3-98] Spring Data JDBC 적용으로 인해 추가된 OrderCoffeeDto(OrderCoffeeDto.java)
OrderCoffeeDto 클래스는 여러 잔의 커피 정보를 주문하기 위해 추가된 DTO 클래스입니다.
✔ OrderCoffeeResponseDto 코드 추가
@Getter
@AllArgsConstructor
public class OrderCoffeeResponseDto {
private long coffeeId;
private String korName;
private String engName;
private int price;
private int quantity;
}[코드 3-98-1] Spring Data JDBC 적용으로 인해 추가된 OrderCoffeeResponseDto(OrderCoffeeResponseDto.java)
OrderCoffeeResponseDto 클래스는 주문한 여러 잔의 커피 정보를 응답으로 제공하기 위해 추가된 DTO 클래스입니다.
✔ OrderResponseDto 코드
import com.springboot.coffee.dto.CoffeeResponseDto;
import com.springboot.order.entity.Order;
import lombok.Getter;
import lombok.Setter;
import java.time.LocalDateTime;
import java.util.List;
@Getter
@Setter
public class OrderResponseDto {
private long orderId;
private long memberId;
private Order.OrderStatus orderStatus;
private List<OrderCoffeeResponseDto> orderCoffees;
private LocalDateTime createdAt;
}[코드 3-99] Spring Data JDBC 적용으로 인해 수정된 OrderResponseDto(OrderResponseDto.java)
OrderResponseDto 클래스는 아래와 같은 기능이 추가되어 수정되었습니다.
- 주문한 여러 건의 커피 정보를 응답으로 전송할 수 있도록 변경
- 주문 시간과 주문 상태를 응답으로 전송할 수 있도록 변경
✔ OrderMapper 코드
import com.springboot.coffee.entity.Coffee;
import com.springboot.coffee.entity.OrderCoffee;
import com.springboot.coffee.service.CoffeeService;
import com.springboot.order.dto.OrderCoffeeResponseDto;
import com.springboot.order.entity.Order;
import com.springboot.order.dto.OrderPostDto;
import com.springboot.order.dto.OrderResponseDto;
import org.mapstruct.Mapper;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
@Mapper(componentModel = "spring")
public interface OrderMapper {
// 수정되었음.
default Order orderPostDtoToOrder(OrderPostDto orderPostDto) {
Order order = new Order();
// (1)
order.setMemberId(orderPostDto.getMemberId());
// (2)
Set<OrderCoffee> orderCoffees = orderPostDto.getOrderCoffees()
.stream()
.map(orderCoffeeDto ->
// (2-1)
OrderCoffee.builder()
.coffeeId(orderCoffeeDto.getCoffeeId())
.quantity(orderCoffeeDto.getQuantity())
.build())
.collect(Collectors.toSet());
order.setOrderCoffees(orderCoffees);
return order;
}
default OrderResponseDto orderToOrderResponseDto(CoffeeService coffeeService,
Order order) {
// (3)
long memberId = order.getMemberId();
// (4)
List<OrderCoffeeResponseDto> orderCoffees =
orderCoffeesToOrderCoffeeResponseDtos(coffeeService, order.getOrderCoffees());
OrderResponseDto orderResponseDto = new OrderResponseDto();
orderResponseDto.setOrderCoffees(orderCoffees);
orderResponseDto.setMemberId(memberId);
orderResponseDto.setCreatedAt(order.getCreatedAt());
orderResponseDto.setOrderId(order.getOrderId());
orderResponseDto.setOrderStatus(order.getOrderStatus());
// TODO 주문에 대한 더 자세한 정보로의 변환은 요구 사항에 따라 다를 수 있습니다.
return orderResponseDto;
}
default List<OrderCoffeeResponseDto> orderCoffeesToOrderCoffeeResponseDtos(
CoffeeService coffeeService,
Set<OrderCoffee> orderCoffees) {
// (5)
return orderCoffees.stream()
.map(orderCoffee -> {
// (5-1)
Coffee coffee = coffeeService.findCoffee(orderCoffee.getCoffeeId());
return new OrderCoffeeResponseDto(coffee.getCoffeeId(),
coffee.getKorName(),
coffee.getEngName(),
coffee.getPrice(),
orderCoffee.getQuantity());
}).collect(Collectors.toList());
}
}[코드 3-100] Spring Data JDBC 적용으로 인해 수정된 OrderMapper(OrderMapper.java)
OrderMapper 인터페이스는 DTO와 Entity 클래스 간의 복잡한 매핑 절차로 인해 기존에 MapStruct가 엔티티 클래스와 DTO 클래스를 대신 매핑해 주던 방식에서 개발자가 직접 매핑 작업 코드를 구현하는 것으로 변경되었습니다.
✔ OrderMapper 코드 설명
- OrderMapper의 경우, DTO와 Entity 간의 매핑 작업이 복잡하기 때문에 우리가 서비스 계층에서 배웠던 Mapsturct의 매핑 방식 중에서 개발자가 직접 매핑 로직을 구현하는 직접 매핑 방식을 사용하고 있습니다.
- orderPostDtoToOrder(OrderPostDto orderPostDto)
- orderPostDtoToOrder() 메서드는 등록하고자 하는 커피 주문 정보(OrderPostDto)를 Order 엔티티 클래스의 객체로 변환하는 역할을 합니다.
- (1) 에서는 orderPostDto에 포함된 memberId를 Order 클래스의 memberId에 할당해 줍니다.
- (2)에서는 orderPostDto에 포함된 주문한 커피 정보인 List<OrderCoffeeDto> orderCoffees를 Java의 Stream을 이용해 Order 클래스의 Set<OrderCoffee> orderCoffees으로 변환하고 있습니다.
- (2-1)에서는 OrderCoffee 클래스에 @Builder 애너테이션이 적용되어 있으므로 lombok에서 지원하는 빌더 패턴을 사용할 수 있습니다.
- 따라서 빌더 패턴을 이용해 List<OrderCoffeeDto> orderCoffees에 포함된 주문한 커피 정보를 OrderCoffee의 필드에 추가하고 있습니다.
- 빌더 패턴을 사용하는 것은 필수는 아닙니다. 빌더 패턴을 사용하든 new 키워드로 객체를 생성하든 상관없지만 빌더 패턴의 사용 예를 보여주기 위해 빌더 패턴을 사용했다는 것을 참고하기 바랍니다.
- 빌더 패턴에 대한 내용은 아래 [심화 학습]을 참고해 주세요.
- orderToOrderResponseDto(CoffeeService coffeeService, Order order)
- orderToOrderResponseDto()는 데이터베이스에서 조회한 Order 객체를 OrderResponseDto 객체로 변환해 주는 역할을 합니다.
- 먼저 (3)에서는 Order의 memberId 필드 값을 얻습니다.
- (4)에서는 주문한 커피의 구체적인 정보를 조회하기 위해 orderToOrderCoffeeResponseDto(coffeeService, order.getOrderCoffees());를 호출합니다.
- order.getOrderCoffees()의 리턴 값은 Set<OrderCoffee> orderCoffees이고, 이 orderCoffees에는 커피명이나 가격 같은 구체적인 커피 정보가 포함된 것이 아니기 때문에 데이터베이스에서 구체적인 커피 정보를 조회하는 추가 작업을 수행해야 합니다.
- orderCoffeesToOrderCoffeeResponseDtos(CoffeeService coffeeService, Set<OrderCoffee> orderCoffees)
- orderCoffeesToOrderCoffeeResponseDtos()는 데이터베이스에서 커피의 구체적인 정보를 조회한 후, OrderCoffeeResponseDto에 커피 정보를 채워 넣는 역할을 합니다.
- (5)에서는 파라미터로 전달받은 orderCoffees를 Java의 Stream을 이용해 데이터베이스에서 구체적인 커피 정보를 조회한 후, OrderCoffeeResponseDto로 변환하는 작업을 하고 있습니다.
- (5-1)에서 파라미터로 전달받은 coffeeService 객체를 이용해 coffeeId에 해당하는 Coffee를 조회하고 있습니다.
✔ ExceptionCode 클래스
public enum ExceptionCode {
MEMBER_NOT_FOUND(404, "Member not found"),
MEMBER_EXISTS(409, "Member exists"),
COFFEE_NOT_FOUND(404, "Coffee not found"),
COFFEE_CODE_EXISTS(409, "Coffee Code exists"),
ORDER_NOT_FOUND(404, "Order not found"),
CANNOT_CHANGE_ORDER(403, "Order can not change"),
NOT_IMPLEMENTATION(501, "Not Implementation");
@Getter
private int status;
@Getter
private String message;
ExceptionCode(int code, String message) {
this.status = code;
this.message = message;
}
}[코드 3-101] Spring Data JDBC 적용으로 인해 수정된 ExceptionCode(ExceptionCode.java)
구현한 커피 주문 샘플 애플리케이션 실행
여러분들이 서비스 클래스와 리포지토리 클래스를 모두 작성했다면 커피 주문 샘플 애플리케이션을 직접 실행해서 데이터베이스에 저장이 잘 되는지 확인해 볼 수 있습니다.
샘플 애플리케이션 실행 후, 아래와 같은 순서대로 테스트를 진행합니다.
- 회원 정보를 등록합니다.
{
"email": "hgd@gmail.com",
"name": "홍길동",
"phone": "010-1234-5555"
}[코드 3-102] 등록할 샘플 회원 정보
코드 3-102의 회원 정보를 Postman을 이용해서 데이터베이스에 등록하세요.
- 커피 정보를 등록합니다.
{
"korName": "카라멜 라떼",
"engName": "Caramel Latte",
"price": 4500,
"coffeeCode": "CRL"
}[코드 3-103] 등록할 샘플 커피 정보1
{
"korName": "바닐라 라떼",
"engName": "Vanilla Latte",
"price": 5000,
"coffeeCode": "VNL"
}[코드 3-104] 등록할 샘플 커피 정보2
- 등록한 회원 정보로 등록한 커피 정보를 주문합니다.
앞에서 회원 정보와 커피 정보를 등록했다면 응답 데이터에서 등록한 회원의 memberId와 등록한 커피의 coffeeId를 각각 확인할 수 있습니다.
{
"memberId": 1,
"orderCoffees":[
{
"coffeeId": 1,
"quantity": 2
},
{
"coffeeId": 2,
"quantity": 1
}
]
}[코드 3-105] 등록한 회원으로 등록한 커피를 주문하는 샘플 주문 정보
코드 3-105의 커피 주문 정보를 Postman을 이용해서 데이터베이스에 등록하세요.
정상적으로 주문이 되었다면 \[그림 3-49-2]와 같이 headers 탭에서 Location 정보를 확인할 수 있습니다.

[그림 3-49-2] 등록된 주문 정보의 Location 정보가 response header에 포함된 모습
커피 주문 시, memberId나 coffeeId 같은 단순한 숫자를 요청으로 보낸다는 것이 어색할지도 모르겠습니다.
하지만 실제 프로젝트라면 사용자가 화면이 있는 프론트엔드(Frontend) 애플리케이션을 이용해서 여러분들이 만든 샘플 애플리케이션의 요청 URI를 내부적으로 이용하여 회원 가입, 카페 주인의 커피 등록, 손님의 커피 목록 조회 및 커피 주문 등의 작업에 coffeeId, memberId 같은 식별자가 대부분 사용된다는 사실을 기억하면 좋을 것 같습니다.
핵심 포인트
- Spring Data JDBC의 CrudRepository 인터페이스를 상속하면 CrudRepository에서 제공하는 CRUD 메서드를 사용할 수 있다.
- Spring Data JDBC에서는 SQL 쿼리를 대신하는 다양한 쿼리 메서드(Query Method) 작성을 지원한다.
- Spring Data JDBC에서 지원하는 쿼리 메서드의 정의가 어렵다면 @Query 애너테이션을 이용해서 SQL 쿼리를 직접 작성할 수 있다.
- 회원 정보, 커피 정보 등의 리소스를 데이터베이스에 Insert할 경우 이미 Insert 된 리소스인지 여부를 검증하는 로직이 필요하다.
- Optional을 이용하면 데이터 검증에 대한 로직을 간결하게 작성할 수 있다.
- 복잡한 DTO 클래스와 엔티티 클래스의 매핑은 Mapper 인터페이스에 default 메서드를 직접 구현해서 개발자가 직접 매핑 로직을 작성해 줄 수 있다.
심화 학습
- Spring Data JDBC에서 사용할 수 있는 쿼리 메서드를 더 알아보고 싶다면 아래 링크를 참고하세요.
- 빌더 패턴과 lombok에서 지원하는 @Builder 애너테이션에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.