
[Spring MVC] JPA 기반 데이터 액세스 계층
Spring Data JDBC 학습을 진행하느라 수고 많았습니다.
Spring Data JDBC 학습을 통해서 여러분들은 ORM의 개념 그리고 Spring Data JDBC 기반의 기본적인 엔티티 설계 방법 및 Spring Data JDBC 사용법 등을 알게 되었을 거라고 생각합니다.
이번 시간부터는 JPA에 대한 학습을 진행해 보도록 하겠습니다.
JPA라는 기술만으로 따지자면 Spring Data JDBC보다 기술적인 난이도와 복잡도가 더 높은 게 사실입니다.
하지만 여러분들은 이미 Spring Data JDBC를 통해서 Spring에서 지원하는 ORM 기술에 조금은 익숙해져 있는 상태입니다.
따라서 여러분들이 Spring Data JDBC에 대해서 충분히 학습했다면 JPA에 대한 학습은 상대적으로 여유 있는 마음을 가지고 진행할 수 있을 거라고 생각합니다.
JPA는 여러분들이 Spring Data JPA를 사용하기 위한 기본이자 핵심 기술이기 때문에 이번 유닛에서 그 개념을 잘 이해해야지만 Spring Data JPA를 손쉽게 사용할 수 있습니다.
JPA에서 여러분들이 가장 어려워하는 부분은 아마도 Spring Data JDBC에서와 마찬가지로 엔티티 간의 연관 관계 매핑일 거라 생각합니다.
여러분들이 JPA 기반 엔티티 간의 연관 관계 매핑 방법에 익숙해질 수 있도록 최대한 쉬운 설명으로 여러분을 안내하겠습니다.
편안한 마음으로 잘 따라와 주길 바라봅니다.
[Spring MVC] JPA 학습을 위한 사전 준비 사항
이번 유닛에서는 순수하게 JPA 기술만 학습할 예정이기 때문에 이 전 시간까지 학습한 Controller, Service, DTO 등의 클래스 들은 필요 없습니다.
따라서 여러분들은 각 챕터에서 안내하는 가이드 대로 필요한 패키지와 클래스에 코드를 작성하면 되겠습니다.
- JPA 학습용 템플릿 프로젝트 복제
- 아래 github 링크에서 학습용 repository를 clone 합니다.
- IntelliJ IDE로 clone 받은 local repository 디렉토리의 프로젝트를 Open합니다.
- 학습을 진행하며 학습 내용에 따라 예제 코드를 타이핑해봅니다.
[Spring MVC] JPA 학습 참고용 레퍼런스 코드
이번 유닛에서 학습한 예제 코드는 아래 github에서 확인할 수 있습니다.
챕터에서 사용한 예제 코드는 챕터에 있는 코드들을 직접 타이핑해본 후, 학습 내용을 조금 더 구체적으로 이해하기 위한 용도로만 활용해 주세요.
- JPA 유닛에 사용한 예제 코드
한번 더 리마인드 해주세요!
복사/붙여 넣기 학습은 여러분들의 성장을 방해합니다.
학습 목표
- JPA가 무엇인지 이해할 수 있다.
- JPA의 동작방식을 이해할 수 있다.
- JPA 엔티티에 대한 매핑을 할 수 있다.
- JPA 기반의 엔티티 간 연관 관계를 매핑할 수 있다.
Chapter - JPA(Java Persistence API) 개요
이번 챕터에서는 순수하게 JPA 기술만 이용하여 JPA가 무엇인지 JPA의 동작은 어떻게 이루어 지는지 대해서 알아보도록 하겠습니다.
JPA의 기술은 굉장히 방대하고, 난이도가 있는 ORM 기술이지만 JPA의 핵심 개념을 이해한다면 결코 넘지 못할 산은 아니라고 생각합니다.
여러분들이 이번 챕터에서 실제로 JPA API를 코드로 타이핑해보고, 실행 결과를 눈으로 확인하면서 JPA 내부에서 일어나는 동작 방식을 대략적으로나마 이해할 수 있길 바라봅니다.
학습 목표
- JPA가 무엇인지 이해할 수 있다.
- JPA의 동작방식을 이해할 수 있다.
- JPA API의 기본 사용방법을 이해할 수 있다.
JPA(Java Persistence API)란?
JPA란?
JPA(Java Persistence API)는 Java 진영에서 사용하는 ORM(Object-Relational Mapping) 기술의 표준 사양(또는 명세, Specification)입니다.
표준 사양(또는 명세)이라는 의미는 다시 말하면 Java의 인터페이스로 사양이 정의되어 있기 때문에 JPA라는 표준 사양을 구현한 구현체는 따로 있다는 것을 의미합니다.
우리가 JPA를 학습한다라고 하면 JPA 표준 사양을 구현한 구현체에 대해서 학습한다라고 생각하면 되겠습니다.
Hibernate ORM
JPA 표준 사양을 구현한 구현체로는 Hibernate ORM, EclipseLink, DataNucleus 등이 있는데, 우리가 학습할 구현체는 바로 Hibernate ORM입니다.
Hibernate ORM은 JPA에서 정의해 둔 인터페이스를 구현한 구현체로써 JPA에서 지원하는 기능 이외에 Hibernate 자체적으로 사용할 수 있는 API 역시 지원하고 있습니다.
JPA는 Java Persistence API의 약자이지만 현재는 Jakarta Persistence라고도 불립니다.
JPA의 의미에 대해서 더 알아보고 싶다면 아래의 [심화 학습]을 참고하세요.
데이터 액세스 계층에서의 JPA 위치

[그림 3-49] 데이터 액세스 계층에서의 JPA 위치
데이터 액세스 계층에서 JPA는 [그림 3-49]와 같이 데이터 액세스 계층의 상단에 위치합니다.
데이터 저장, 조회 등의 작업은 JPA를 거쳐 JPA의 구현체인 Hibernate ORM을 통해서 이루어지며 Hibernate ORM은 내부적으로 JDBC API를 이용해서 데이터베이스에 접근하게 됩니다.
따라서 이번 챕터에서는 데이터 액세스 계층 상단에 위치한 JPA에서 지원하는 API를 사용해서 데이터베이스에 접근하는 방법을 학습하면 되는 것입니다.
JPA(Java Persistence API)에서 P(Persistence)의 의미
JPA라는 용어에서 유독 의미를 알 수 없는 단어가 바로 Persistence입니다.
Persistence는 영속성, 지속성이라는 뜻을 가지고 있습니다. 즉, 무언가를 금방 사라지지 않고 오래 지속되게 한다라는 것이 Persistence의 목적인 것입니다.
영속성 컨텍스트(Persistence Context)
그렇다면 JPA에서는 무얼 오래 지속되게 하는 것일까요?
ORM은 객체(Object)와 데이터베이스 테이블의 매핑을 통해 엔티티 클래스 객체 안에 포함된 정보를 테이블에 저장하는 기술입니다.
JPA에서는 테이블과 매핑되는 엔티티 객체 정보를 영속성 컨텍스트(Persistence Context)라는 곳에 보관해서 애플리케이션 내에서 오래 지속되도록 합니다.
그리고 이렇게 보관된 엔티티 정보는 데이터베이스 테이블에 데이터를 저장, 수정, 조회, 삭제하는 데 사용됩니다.
영속성 컨텍스트(Persistence Context)를 그림으로 표현하면 [그림 3-50]과 같습니다.

[그림 3-50] 그림으로 표현한 영속성 컨텍스트(Persistence Context)
[그림 3-50]과 같이 영속성 컨텍스트에는 1차 캐시라는 영역과 쓰기 지연 SQL 저장소라는 영역이 있습니다.
JPA API 중에서 엔티티 정보를 영속성 컨텍스트에 저장(persist)하는 API를 사용하면 영속성 컨텍스트의 1차 캐시에 엔티티 정보가 저장됩니다.
그럼 실제로 JPA에서 지원하는 API를 사용해서 영속성 컨텍스트에 엔티티를 저장해 보도록 하겠습니다.
JPA API로 영속성 컨텍스트 이해하기
✔ JPA API를 사용하기 위한 사전 준비
- build.gradle 설정
여러분이 github에서 clone 받은 템플릿 프로젝트에는 JPA를 사용하기 위한 의존 라이브러리가 코드 3-107과 같이 build.gradle에 추가되어 있습니다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa' // (1)
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}[코드 3-107] spring-boot-starter-data-jpa 설정 추가
(1)과 같이 spring-boot-starter-data-jpa를 추가하면 기본적으로 Spring Data JPA 기술을 포함해서 JPA API를 사용할 수 있습니다.
Spring Data JPA가 아닌 JPA API만 사용하고 싶다면 JPA 관련 의존 라이브러리를 별도로 추가해야 되지만 여러분들이 설정의 복잡함을 경험하는 것보다는 JPA API의 동작을 손쉽게 확인하는 것이 주목적이기 때문에 JPA만 별도로 설정을 하는 방법은 건너뛰도록 하겠습니다.
- JPA 설정(application.yml)
spring:
h2:
console:
enabled: true
path: /h2
datasource:
url: jdbc:h2:mem:test
jpa:
hibernate:
ddl-auto: create # (1) 스키마 자동 생성
show-sql: true # (2) SQL 쿼리 출력[코드 3-108] JPA 설정 추가
코드 3-108에서는 (1), (2)와 같이 두 가지 설정을 application.yml에 추가했습니다.
(1)과 같이 설정을 추가해 주면 우리가 JPA에서 사용하는 엔티티 클래스를 정의하고 애플리케이션 실행 시, 이 엔티티와 매핑되는 테이블을 데이터베이스에 자동으로 생성해 줍니다.
즉, Spring Data JDBC에서는 schema.sql 파일을 이용해 테이블 생성을 위한 스키마를 직접 지정해 주어야 했지만 JPA에서는 (1)의 설정을 추가하면 JPA가 자동으로 데이터베이스에 테이블을 생성해 줍니다.
ddl-auto 설정에 대해서 더 알아보고 싶다면 아래 \[심화 학습]을 참고하세요.
(2)와 같이 설정을 추가해 주면 JPA의 동작 과정을 이해하기 위해 JPA API를 통해서 실행되는 SQL 쿼리를 로그로 출력해 줍니다.
우리는 이 SQL 쿼리를 통해서 JPA 동작 과정을 조금 더 쉽게 이해할 수 있을 것입니다.
- 샘플 코드 실행을 위한 Configuration 클래스 생성
package com.springboot.basic;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
// (1)
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
// (2)
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
// (3) 이 곳에 학습할 코드를 타이핑합니다.
};
}
}[코드 3-109] 샘플 코드 타이핑을 위한 JpaBasicConfig 클래스
코드 3-109의 (1)과 같이 특정 클래스에 @Configuration 애너테이션을 추가하면 Spring에서 Bean 검색 대상인 Configuration 클래스로 간주해서 (2)와 같이 @Bean 애너테이션이 추가된 메서드를 검색한 후, 해당 메서드에서 리턴하는 객체를 Spring Bean으로 추가해 줍니다.
코드 3-109의 (3)과 같이 CommandLineRunner 객체를 람다 표현식으로 정의해 주면 애플리케이션 부트스트랩 과정이 완료된 후에 이 람다 표현식에 정의한 코드를 실행해 줍니다.
우리는 이곳에 JPA API를 사용해서 코드를 작성하고 애플리케이션을 실행시켜서 JPA의 동작 과정을 살펴보도록 하겠습니다.
이제 JPA를 이용해서 코드를 작성해 봅시다.
✔ 영속성 컨텍스트에 엔티티 저장
import lombok.Getter;
import javax.persistence.*;
@Getter
@Setter
@NoArgsConstructor
@Entity // (1)
public class Member {
@Id // (2)
@GeneratedValue // (3)
private Long memberId;
private String email;
public Member(String email) {
this.email = email;
}
}[코드 3-110] JPA 동작 확인을 위한 Member 엔티티 클래스 (com/codestates/entity/Member.java)
코드 3-110은 JPA에서 사용하기 위한 Member 엔티티 클래스입니다.
여러분들이 Spring Data JDBC를 이미 학습했기 때문에 @Entity 애너테이션과 @Id 애너테이션을 붙이는 이유를 짐작하고 있을 것입니다.
맞습니다. @Entity 애너테이션과 @Id 애너테이션을 추가해 주면 JPA에서 해당 클래스를 엔티티 클래스로 인식합니다.
(3)의 @GeneratedValue 애너테이션은 식별자를 생성해 주는 전략을 지정할 때 사용합니다. @GeneratedValue 애너테이션에 대해서는 다음 챕터에서 자세히 설명하도록 하겠습니다.
지금은 식별자에 해당하는 멤버 변수에 @GeneratedValue 애너테이션을 추가하면 데이터베이스 테이블에서 기본키가 되는 식별자를 자동으로 설정해 준다 정도로만 알고 있으면 되겠습니다.
package com.springboot.basic;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaBasicConfig {
private EntityManager em;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) { // (1)
this.em = emFactory.createEntityManager(); // (2)
return args -> {
example01();
};
}
private void example01() {
Member member = new Member("hgd@gmail.com");
// (3)
em.persist(member);
// (4)
Member resultMember = em.find(Member.class, 1L);
System.out.println("Id: " + resultMember.getMemberId() + ", email: " +
resultMember.getEmail());
}
}[코드 3-111] 영속성 컨텍스트 Member 객체를 저장하는 예제
코드 3-111은 우리가 정의한 Member 엔티티 클래스의 객체를 JPA의 영속성 컨텍스트에 저장하는 예제 코드입니다.
- JPA의 영속성 컨텍스트는 EntityManager 클래스에 의해서 관리되는데 이 EntityManager 클래스의 객체는 (1)과 같이 EntityManagerFactory 객체를 Spring으로부터 DI 받을 수 있습니다.
- (2)와 같이 EntityManagerFactory의 createEntityManager() 메서드를 이용해서 EntityManager 클래스의 객체를 얻을 수 있습니다. 이제 이 EntityManager 클래스의 객체를 통해서 JPA의 API 메서드를 사용할 수 있습니다.
- (3)과 같이 persist(member) 메서드를 호출하면 영속성 컨텍스트에 member 객체의 정보들이 저장됩니다.
- (4)에서는 영속성 컨텍스트에 member 객체가 잘 저장되었는지 find(Member.class, 1L) 메서드로 조회하고 있습니다.
- find() 메서드의 파라미터 설명
- 첫 번째 파라미터는 조회할 엔티티 클래스의 타입입니다.
- 두 번째 파라미터는 조회할 엔티티 클래스의 식별자 값입니다.
- find() 메서드의 파라미터 설명
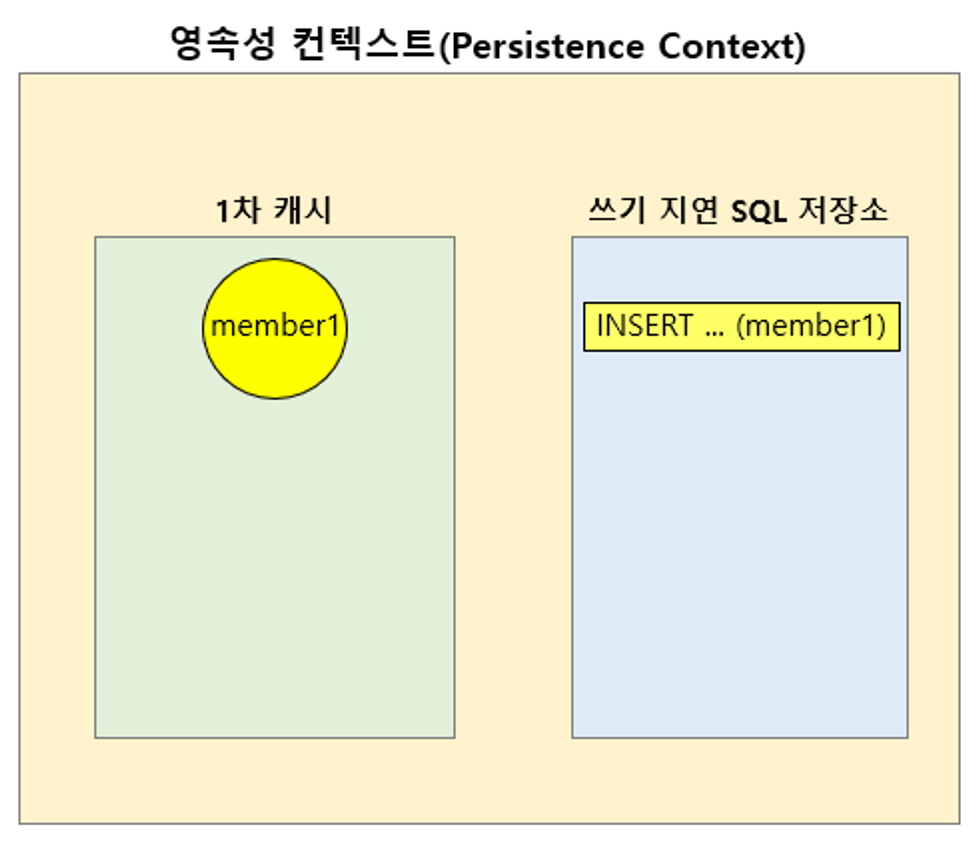
[그림 3-51] 코드 3-111을 실행했을 때의 영속성 컨텍스트(Persistence Context) 상태
[그림 3-51]은 코드 3-111을 실행했을 때의 영속성 컨텍스트의 상태입니다.
em.persist(member)를 호출하면 \[그림 3-51]과 같이 1차 캐시에 member 객체가 저장되고, 이 member 객체는 쓰기 지연 SQL 저장소에 INSERT 쿼리 형태로 등록이 됩니다.
Hibernate: drop table if exists member CASCADE
Hibernate: drop table if exists orders CASCADE
Hibernate: drop sequence if exists hibernate_sequence
Hibernate: create sequence hibernate_sequence start with 1 increment by 1
Hibernate: create table member (member_id bigint not null,
email varchar(255), primary key (member_id))
Hibernate: create table orders (order_id bigint not null,
created_at timestamp, primary key (order_id))
Hibernate: call next value for hibernate_sequence
**Id: 1, email: hgd@gmail.com**코드 3-111의 출력 결과를 보면 ID가 1인 Member의 email 주소를 영속성 컨텍스트에서 조회하고 있는 것을 확인할 수 있습니다.
member 객체 정보를 출력하는 라인 위쪽 로그에서 JPA가 내부적으로 테이블을 자동 생성하고, 테이블의 기본키를 할당해 주는 것을 확인할 수 있습니다.
그런데, em.persist(member)를 호출할 경우, 영속성 컨텍스트에 member 객체를 저장하지만 실제 테이블에 회원 정보를 저장하지는 않습니다.
실제 로그에도 insert 쿼리가 보이지 않습니다.
✔ 영속성 컨텍스트와 테이블에 엔티티 저장
그럼 이 member 정보를 실제 테이블에 저장해 보겠습니다.
package com.springboot.basic;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
// (1)
this.tx = em.getTransaction();
return args -> {
example02();
};
}
private void example02() {
// (2)
tx.begin();
Member member = new Member("hgd@gmail.com");
// (3)
em.persist(member);
// (4)
tx.commit();
// (5)
Member resultMember1 = em.find(Member.class, 1L);
System.out.println("Id: " + resultMember1.getMemberId() + ", email: " + resultMember1.getEmail());
// (6)
Member resultMember2 = em.find(Member.class, 2L);
// (7)
System.out.println(resultMember2 == null);
}
}[코드 3-112] 영속성 컨텍스트와 테이블에 Member 객체를 저장하는 예제
코드 3-112에서는 member 객체를 영속성 콘텍스트뿐만 아니라 데이터베이스의 테이블에도 저장하고 있습니다.
- (1)에서는 EntityManager를 통해서 Transaction 객체를 얻습니다. JPA에서는 이 Transaction 객체를 기준으로 데이터베이스의 테이블에 데이터를 저장합니다.
- JPA에서는 (2)와 같이 Transaction을 시작하기 위해서 tx.begin() 메서드를 먼저 호출해 주어야 합니다.
- (3)에서 member 객체를 영속성 컨텍스트에 저장합니다.
- (4)와 같이 tx.commit()을 호출하는 시점에 영속성 컨텍스트에 저장되어 있는 member 객체를 데이터베이스의 테이블에 저장합니다.
- (5)에서 em.find(Member.class, 1L)을 호출하면 (3)에서 영속성 컨텍스트에 저장한 member 객체를 1차 캐시에서 조회합니다. 1차 캐시에 member 객체 정보가 있기 때문에 별도로 테이블에 SELECT 쿼리를 전송하지 않습니다.
- (6)에서 em.find(Member.class, 2L)를 호출해서 식별자 값이 2L인 member 객체를 조회합니다. 하지만 영속성 컨텍스트에는 식별자 값이 2L인 member 객체는 존재하지 않기 때문에 (7)의 결과는 true가 됩니다. (6)에서는 영속성 컨텍스트에서 식별자 값이 2L인 member 객체가 존재하지 않기 때문에 테이블에 직접 SELECT 쿼리를 전송합니다. (실행 결과 로그에서 확인할 수 있습니다.)

[그림 3-52] 코드 3-112를 실행했을 때의 영속성 컨텍스트(Persistence Context) 상태
[그림 3-52]는 코드 3-112를 실행했을 때의 영속성 컨텍스트의 상태입니다.
tx.commit()을 했기 때문에 member에 대한 INSERT 쿼리는 실행되어 쓰기 지연 SQL 저장소에서 사라집니다.
Hibernate: drop table if exists member CASCADE
Hibernate: drop table if exists orders CASCADE
Hibernate: drop sequence if exists hibernate_sequence
Hibernate: create sequence hibernate_sequence start with 1 increment by 1
Hibernate: create table member (member_id bigint not null, email varchar(255),
primary key (member_id))
Hibernate: create table orders (order_id bigint not null, created_at timestamp,
primary key (order_id))
Hibernate: call next value for hibernate_sequence
Hibernate: insert into member (email, member_id) values (?, ?)
Id: 1, email: hgd@gmail.com
// (1)
**Hibernate: select member0_.member_id as member_i1_0_0_,
member0_.email as email2_0_0_ from member member0_ where member0_.member_id=?**
true코드 3-112의 실행 결과를 보면 (1)에서 SELECT 쿼리가 실행된 것을 볼 수 있습니다.
이 SELECT 쿼리를 통해 코드 3-112의 (6)에서 em.find(Member.class, 2L)로 조회를 했는데 식별자 값이 2L에 해당하는 member2 객체가 영속성 컨텍스트의 1차 캐시에 없기 때문에 추가적으로 테이블에서 한번 더 조회한다는 것을 알 수 있습니다.
✅
위 두 개의 샘플 코드에서 기억해야 할 내용은 다음과 같습니다.
- em.persist()를 호출하면 영속성 컨텍스트의 1차 캐시에 엔티티 클래스의 객체가 저장되고, 쓰기 지연 SQL 저장소에 INSERT 쿼리가 등록된다.
- tx.commit()을 하는 순간 쓰기 지연 SQL 저장소에 등록된 INSERT 쿼리가 실행되고, 실행된 INSERT 쿼리는 쓰기 지연 SQL 저장소에서 제거된다.
- em.find()를 호출하면 먼저 1차 캐시에서 해당 객체가 있는지 조회하고, 없으면 테이블에 SELECT 쿼리를 전송해서 조회한다.
✔ 쓰기 지연을 통한 영속성 컨텍스트와 테이블에 엔티티 일괄 저장
package com.springboot.basic;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
example03();
};
}
private void example03() {
tx.begin();
Member member1 = new Member("hgd1@gmail.com");
Member member2 = new Member("hgd2@gmail.com");
em.persist(member1); // (1)
em.persist(member2); // (2)
tx.commit(); // (3)
}
}[코드 3-113] 쓰기 지연을 통한 Member 객체 저장 예제
코드 3-113에서는 (1), (2)에서 각각 member1과 member2 객체를 영속성 컨텍스트에 저장하고 있습니다.

[그림 3-53] 코드 3-113에서 tx.commit() 전의 영속성 컨텍스트(Persistence Context) 상태
[그림 3-53]은 코드 3-113에서 tx.commit()이 실행되기 직전의 영속성 컨텍스트 상태를 표현한 것입니다.
보다시피 tx.commit()을 하기 전까지는 em.persist()를 통해 쓰기 지연 SQL 저장소에 등록된 INSERT 쿼리가 실행이 되지 않습니다.
따라서 테이블에 데이터가 저장이 되지 않습니다.

[그림 3-54] 코드 3-113에서 tx.commit() 후의 영속성 컨텍스트(Persistence Context) 상태
[그림 3-54]는 코드 3-113에서 tx.commit()이 실행된 직후의 영속성 컨텍스트 상태를 표현한 것입니다.
보다시피 tx.commit()이 실행된 이후에는 쓰기 지연 SQL 저장소에 등록된 INSERT 쿼리가 모두 실행되고 실행된 쿼리는 제거됩니다.
따라서 테이블에 데이터가 저장됩니다.
코드 3-113의 실행 결과는 다음과 같습니다.
Hibernate: drop table if exists member CASCADE
Hibernate: drop table if exists orders CASCADE
Hibernate: drop sequence if exists hibernate_sequence
Hibernate: create sequence hibernate_sequence start with 1 increment by 1
Hibernate: create table member (member_id bigint not null, email varchar(255), primary key (member_id))
Hibernate: create table orders (order_id bigint not null, created_at timestamp, primary key (order_id))
Hibernate: call next value for hibernate_sequence
Hibernate: call next value for hibernate_sequence
// (1)
Hibernate: insert into member (email, member_id) values (?, ?)
Hibernate: insert into member (email, member_id) values (?, ?)코드 3-113의 실행 결과를 보면 (1)과 같이 쓰기 지연 SQL 저장소에 저장된 INSERT 쿼리가 실행이 된 것을 확인할 수 있습니다.
✔ 영속성 컨텍스트와 테이블에 엔티티 업데이트
이번에는 테이블에 이미 저장되어 있는 데이터를 JPA를 이용해서 어떻게 업데이트할 수 있는지 보겠습니다.
package com.springboot.basic;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
example04();
};
}
private void example04() {
tx.begin();
em.persist(new Member("hgd1@gmail.com")); // (1)
tx.commit(); // (2)
tx.begin();
Member member1 = em.find(Member.class, 1L); // (3)
member1.setEmail("hgd1@yahoo.co.kr"); // (4)
tx.commit(); // (5)
}
}[코드 3-114] 엔티티 변경 감지를 통한 Member 객체 업데이트 예제
코드 3-114에서는 이미 테이블에 저장된 데이터의 정보를 업데이트하는 방법을 보여주고 있습니다.
- 먼저 (1)에서 member 객체를 영속성 컨텍스트의 1차 캐시에 저장합니다.
- (2)에서 tx.commit()을 호출해서 영속성 컨텍스트의 쓰기 지연 SQL 저장소에 등록된 INSERT 쿼리를 실행합니다.
- (3)과 같이 (2)에서 테이블에 저장된 member 객체를 영속성 컨텍스트의 1차 캐시에서 조회합니다. 테이블에서 조회하는 것이 아닙니다. 영속성 컨텍스트의 1차 캐시에 이미 저장된 객체가 있기 때문에 영속성 컨텍스트에서 조회한다는 사실을 기억하기 바랍니다.
- (4)에서 setter 메서드로 이메일 정보를 변경합니다. 여기서 중요한 사실은 em.update() 같은 JPA API가 있을 것 같지만 (4)와 같이 setter 메서드로 값을 변경하기만 하면 업데이트 로직은 완성이 된 것입니다.
- (5)에서 tx.commit()을 실행하면 쓰기 지연 SQL 저장소에 등록된 UPDATE 쿼리가 실행이 됩니다.
Hibernate: drop table if exists member CASCADE
Hibernate: drop table if exists orders CASCADE
Hibernate: drop sequence if exists hibernate_sequence
Hibernate: create sequence hibernate_sequence start with 1 increment by 1
Hibernate: create table member (member_id bigint not null, email varchar(255),
primary key (member_id))
Hibernate: create table orders (order_id bigint not null, created_at timestamp,
primary key (order_id))
Hibernate: call next value for hibernate_sequence
Hibernate: insert into member (email, member_id) values (?, ?)
// (1)
**Hibernate: update member set email=? where member_id=?**코드 3-114의 실행 결과를 보면 UPDATE 쿼리가 실행이 된 것을 확인할 수 있습니다.
UPDATE 쿼리가 실행이 되는 과정
코드 3-114와 같이 setter 메서드로 값을 변경만 해도 tx.commit() 시점에 UPDATE 쿼리가 실행이 되는 이유는 무엇일까요?
영속성 컨텍스트에 엔티티가 저장될 경우에는 저장되는 시점의 상태를 그대로 가지고 있는 스냅샷을 생성합니다.
그 후 해당 엔티티의 값을 setter 메서드로 변경한 후, tx.commit()을 하면 변경된 엔티티와 이 전에 이미 떠 놓은 스냅샷을 비교한 후, 변경된 값이 있으면 쓰기 > 지연 SQL 저장소에 UPDATE 쿼리를 등록하고 UPDATE 쿼리를 실행합니다.
✔ 영속성 컨텍스트와 테이블의 엔티티 삭제
package com.springboot.basic;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
example05();
};
}
private void example05() {
tx.begin();
em.persist(new Member("hgd1@gmail.com")); // (1)
tx.commit(); //(2)
tx.begin();
Member member = em.find(Member.class, 1L); // (3)
em.remove(member); // (4)
tx.commit(); // (5)
}
}[코드 3-115] Member 객체 삭제 예제
코드 3-115에서는 이미 테이블에 저장된 데이터를 삭제하는 방법을 보여주고 있습니다.
- 먼저 (1)에서 Member 클래스의 객체를 영속성 컨텍스트의 1차 캐시에 저장합니다.
- (2)에서 tx.commit()을 호출해서 영속성 컨텍스트의 쓰기 지연 SQL 저장소에 등록된 INSERT 쿼리를 실행합니다.
- (2)에서 테이블에 저장된 Member 클래스의 객체를 (3)과 같이 영속성 컨텍스트의 1차 캐시에서 조회합니다.
- (4)에서 em.remove(member)을 통해 영속성 컨텍스트의 1차 캐시에 있는 엔티티를 제거를 요청합니다.
- (5)에서 tx.commit()을 실행하면 영속성 컨텍스트의 1차 캐시에 있는 엔티티를 제거하고, 쓰기 지연 SQL 저장소에 등록된 DELETE 쿼리가 실행이 됩니다.
EntityManager의 flush() API
예제코드에서 살펴보지는 않았지만 우리가 예제 코드에서 사용한 tx.commit() 메서드가 호출되면 JPA 내부적으로 em.flush() 메서드가 호출되어 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영한다는 사실을 기억하기 바랍니다.
핵심 포인트
- JPA(Java Persistence API)는 Java 진영에서 사용하는 ORM(Object-Relational Mapping) 기술의 표준 사양(또는 명세, Specification)이다.
- Hibernate ORM은 JPA에서 정의해 둔 인터페이스를 구현한 구현체로써 JPA에서 지원하는 기능 이외에 Hibernate 자체적으로 사용할 수 있는 API 역시 지원하고 있다.
- JPA에서는 테이블과 매핑되는 엔티티 객체 정보를 영속성 컨텍스트(Persistence Context)에 보관해서 애플리케이션 내에서 오래 지속되도록 한다.
- 영속성 컨텍스트 관련 JPA API
- em.persist()를 사용해서 엔티티 객체를 영속성 컨텍스트에 저장할 수 있다.
- 엔티티 객체의 setter 메서드를 사용해서 영속성 컨텍스트에 저장된 엔티티 객체의 정보를 업데이트할 수 있다.
- em.remove()를 사용해서 엔티티 객체를 영속성 컨텍스트에서 제거할 수 있다.
- em.flush()를 사용해서 영속성 컨텍스트의 변경 사항을 테이블에 반영할 수 있다.
- tx.commit()을 호출하면 내부적으로 em.flush()가 호출된다.
심화 학습
- JPA의 의미에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- JPA의 생명주기(lifecycle)에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- Hibernate ORM의 API 문서를 더 읽어보고 싶다면 아래 링크를 참고하세요.
- Spring Boot에서 JPA 엔티티를 테이블로 자동 생성해 주는 ddl-auto 기능에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
Chapter - JPA 엔티티(Entity) 매핑과 연관 관계 매핑
이번 챕터에서는 단일 엔티티 클래스와 테이블 간의 매핑 기법을 먼저 학습합니다.
그리고 이어서 엔티티 간의 연관 관계가 무엇인지, 엔티티 간의 연관 관계를 어떻게 맺을 수 있는지를 학습하게 됩니다.
엔티티 간의 연관 관계는 JPA 학습에서 가장 중요한 부분이며, 가장 어려운 파트 중 하나입니다.
따라서 연관 관계의 모든 것을 이해하기보다는 가장 기초적인 연관 관계를 맺는 방법과 실제로 실무에서 자주 쓰는 연관 관계 위주로 학습을 진행할 예정입니다.
이번 챕터를 통해서 JPA의 엔티티 연관 관계 매핑에 대한 내용을 여러분들 것으로 만들 수 있길 기대해 봅니다.
학습 목표
- JPA 엔티티에 대한 매핑을 할 수 있다.
- JPA 기반의 엔티티 간 연관 관계를 매핑할 수 있다.
[기본] 엔티티 매핑
JPA를 이용해 데이터베이스의 테이블과 상호 작용(데이터 저장, 수정, 조회, 삭제 등) 하기 위해 제일 먼저 해야 되는 작업은 바로 데이터베이스의 테이블과 엔티티 클래스 간의 매핑 작업입니다.
여러분들이 Spring Data JDBC 학습을 통해 테이블 매핑, 기본키 매핑, 열 매핑 등에 대한 기본 개념은 어느 정도 익숙해졌을 거라 생각합니다.
이번 시간에는 JPA에서 사용되는 매핑 애너테이션을 이용해 데이터베이스의 단일 테이블과 엔티티 클래스 간의 매핑 작업을 해보도록 하겠습니다.
엔티티 매핑 작업은 크게 객체와 테이블 간의 매핑, 기본키 매핑, 필드(멤버 변수)와 열 간의 매핑, 엔티티 간의 연관 관계 매핑 등으로 나눌 수 있습니다.
엔티티 간의 연관 관계 매핑은 JPA에서 가장 이해하기 어려우면서 가장 중요한 파트이기 때문에 이어지는 별도의 챕터에서 자세히 다룰 예정입니다.
이번 시간에는 엔티티 간의 관계에 대해서는 잠시 생각을 접어두고 단일 엔티티 매핑에 대한 학습에 집중해 주세요.
❗❗❗ 주의 사항 학습 콘텐츠에서는 여러분들이 엔티티 클래스를 단계적으로 이해할 수 있도록 레퍼런스 코드 상에서 동일한 이름의 엔티티 클래스라도 패키지를 다르게 구성하였습니다.
즉, 레퍼런스 코드 상에는 동일한 이름의 엔티티 클래스(Member, Coffee, Order)가 여러 개 있을 수 있지만 여러분이 콘텐츠에 있는 코드를 직접 타이핑할 경우에는 이름이 중복되는 클래스가 있으면 안 된다는 사실을 명심하고 학습에 임해주길 바랍니다.
엔티티와 테이블 간의 매핑
package com.springboot.entity_mapping.single_mapping.table;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table
public class Member {
@Id
private Long memberId;
}
[코드 3-116] 엔티티와 테이블 간의 매핑
코드 3-116에서는 @Entity 매핑 애너테이션을 이용해 엔티티 클래스와 테이블을 매핑했습니다.
코드 3-116과 같이 클래스 레벨에 @Entity 애너테이션을 붙이면 JPA 관리 대상 엔티티가 됩니다.
✔ @Entity 애너테이션 설명
- 애트리뷰트
- name
- 엔티티 이름을 설정할 수 있습니다.
- name 애트리뷰트를 설정하지 않으면 기본값으로 클래스 이름을 엔티티 이름으로 사용합니다.
- name
package com.springboot.entity_mapping.single_mapping.table;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity(name = "USERS") // (1)
@Table(name = "USERS") // (2)
public class Member {
@Id
private Long memberId;
}[코드 3-117] 엔티티 이름 변경 예
코드 3-117의 (1), (2)와 같이 name 애트리뷰트를 사용해서 엔티티 이름과 테이블 이름을 변경할 수 있습니다.
✔ @Table 애너테이션 설명
- 애트리뷰트
- name
- 테이블 이름을 설정할 수 있습니다.
- name 애트리뷰트를 설정하지 않으면 기본값으로 클래스 이름을 테이블 이름으로 사용합니다.
- @Table 애너테이션은 옵션이며, 추가하지 않을 경우 클래스 이름을 테이블 이름으로 사용합니다.
- 주로 테이블 이름이 클래스 이름과 달라야 할 경우에 추가합니다.
- name
✅ 주의 사항
- @Table 애너테이션은 옵션이지만 @Entity 애너테이션과 @Id 애너테이션은 필수입니다.
- @Entity 애너테이션과 @Id 애너테이션은 함께 사용하세요.
- 만약에 @Entity 애너테이션만 추가하고 식별자 역할을 하는 필드(멤버 변수)에 @Id 애너테이션을 추가하지 않으면 다음과 같은 에러가 발생합니다.
- Caused by: org.hibernate.AnnotationException: No identifier specified for entity: com.springboot.entity_mapping.single_mapping.Member
- 만약에 @Entity 애너테이션만 추가하고 식별자 역할을 하는 필드(멤버 변수)에 @Id 애너테이션을 추가하지 않으면 다음과 같은 에러가 발생합니다.
- 파라미터가 없는 기본 생성자는 필수로 추가해 주세요.
- Spring Data JPA의 기술을 적용할 때 기본 생성자가 없는 경우 에러가 발생하는 경우가 있기 때문에 기본 생성자는 습관적으로 추가하는 것이 좋습니다.
- 중복되는 엔티티 클래스가 없고, 테이블 이름이 클래스 이름과 같을 경우에는 @Entity 애너테이션과 @Table 애너테이션에 name 애트리뷰트를 지정하지 않고, 클래스 이름으로 사용하는 게 권장됩니다.
기본키 매핑
데이터베이스의 테이블에 기본키 설정은 필수라고 할 수 있습니다.
JPA에서는 기본적으로 @Id 애너테이션을 추가한 필드가 기본 키 열이 되는데, JPA에서는 이러한 기본 키를 어떤 방식으로 생성해 줄지에 대한 다양한 전략을 지원합니다.
JPA에서 지원하는 기본키 생성 전략은 다음과 같습니다.
- 기본키 직접 할당
- 애플리케이션 코드 상에서 기본키를 직접 할당해주는 방식입니다.
- 기본키 자동 생성
- IDENTITY
- 기본키 생성을 데이터베이스에 위임하는 전략입니다.
- 데이터베이스에서 기본키를 생성해 주는 대표적인 방식은 MySQL의 AUTO_INCREMENT 기능을 통해 자동 증가 숫자를 기본키로 사용하는 방식이 있습니다.
- SEQUENCE
- 데이터베이스에서 제공하는 시퀀스를 사용해서 기본키를 생성하는 전략입니다.
- TABLE
- 별도의 키 생성 테이블을 사용하는 전략입니다.
- IDENTITY
이번 코스에서는 기본 키 생성 전략 중 TABLE 전략에 대한 설명은 하지 않습니다. TABLE 전략은 키 생성 전용 TABLE을 별도로 만들어야 되고, 키를 조회하고 업데이트하는 쿼리를 추가적으로 전송해야 하기 때문에 성능면에서 좋은 선택은 아닙니다.
TABLE 전략이 궁금한 분들은 아래 링크를 참고하세요. https://docs.jboss.org/hibernate/orm/5.6/userguide/html_single/Hibernate_User_Guide.html#identifiers-generators-table
✔ 기본키 직접 할당 전략
package com.springboot.entity_mapping.single_mapping.id.direct;
@NoArgsConstructor
@Getter
@Entity
public class Member {
@Id // (1)
private Long memberId;
public Member(Long memberId) {
this.memberId = memberId;
}
}[코드 3-118] 기본키 직접 할당 엔티티
단순히 코드 3-118의 (1)과 같이 @Id 애너테이션만 추가하면 기본적으로 기본키 직접 할당 전략이 적용됩니다.
[코드 3-119] 기본키 직접 할당 예
package com.springboot.entity_mapping.single_mapping.id.direct;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaIdDirectMappingConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaSingleMappingRunner(EntityManagerFactory emFactory){
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
tx.begin();
em.persist(new Member(1L)); // (1)
tx.commit();
Member member = em.find(Member.class, 1L);
System.out.println("# memberId: " + member.getMemberId());
};
}
}[코드 3-119] 기본키 직접 할당 예
코드 3-119에서는 (1)과 같이 기본키를 직접 할당해서 엔티티를 저장합니다.
만약 (1)에서 기본키 없이 엔티티를 저장하면 아래와 같은 에러 메시지를 출력합니다.
Caused by: javax.persistence.PersistenceException: org.hibernate.id.IdentifierGenerationException: ids for this class must be manually assigned before calling save(): … …
✔ IDENTITY 전략
package com.springboot.entity_mapping.single_mapping.id.identity;
@NoArgsConstructor
@Getter
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // (1)
private Long memberId;
public Member(Long memberId) {
this.memberId = memberId;
}
}[코드 3-120] IDENTITY 기본키 생성 전략 설정
IDENTITY 기본키 생성 전략을 설정하려면 코드 3-120과 같이 @GeneratedValue 애너테이션의 strategy 애트리뷰트의 값을 GenerationType.IDENTITY로 지정해 주면 됩니다.
IDENTITY 전략은 데이터베이스에서 기본키를 대신 생성해 준다고 했습니다.
실제로 기본키를 자동 생성해 주는지 확인해 봅시다.
package com.springboot.entity_mapping.single_mapping.id.identity;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaIdIdentityMappingConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaSingleMappingRunner(EntityManagerFactory emFactory){
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
tx.begin();
em.persist(new Member());
tx.commit();
Member member = em.find(Member.class, 1L);
System.out.println("# memberId: " + member.getMemberId());
};
}
}[코드 3-121] IDENTITY 기본키 생성 전략을 통한 엔티티 저장 예
코드 3-121에서는 Member 엔티티에 IDENTITY 전략이 적용되었기 때문에 Member 엔티티에 별도의 기본키 값을 할당하지 않았습니다.
애플리케이션을 실행해서 코드 3-121의 결과를 확인해 보겠습니다.
Hibernate: drop table if exists member CASCADE
Hibernate: create table member (member_id bigint generated by default as identity, primary key (member_id))
// (1)
Hibernate: insert into member (member_id) values (default)
# memberId: 1실행 결과를 보면 MEMBER 테이블에 데이터를 저장하고, 기본키 값이 자동으로 생성되어 조회가 정상적으로 된 것을 확인할 수 있습니다.
✔ SEQUENCE 전략
package com.springboot.entity_mapping.single_mapping.id.sequence;
@NoArgsConstructor
@Getter
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE) // (1)
private Long memberId;
public Member(Long memberId) {
this.memberId = memberId;
}
}[코드 3-122] SEQUENCE 기본키 생성 전략 설정
SEQUENCE 전략을 사용하기 위해서는 @GeneratedValue(strategy = GenerationType.SEQUENCE)를 지정하면 됩니다.
SEQUENCE 전략은 데이터베이스 시퀀스를 이용한다고 했습니다.
GenerationType.SEQUENCE로 설정했을 때, JPA가 어떤 식으로 동작하는지 확인해 보겠습니다.
package com.springboot.entity_mapping.single_mapping.id.sequence;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaIdIdSequenceMappingConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaSingleMappingRunner(EntityManagerFactory emFactory){
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
tx.begin();
em.persist(new Member()); // (1)
Member member = em.find(Member.class, 1L);
System.out.println("# memberId: " + member.getMemberId());
tx.commit();
};
}
}[코드 3-123] SEQUENCE 기본키 생성 전략을 통한 엔티티 저장 예
코드 3-123 역시 (1)과 같이 Member 엔티티 객체를 생성하면서 별도의 기본키 값을 전달하지 않았습니다.
하지만 SEQUENCE 전략을 사용하도록 지정했으므로 엔티티가 영속성 컨텍스트에 저장되기 전에 데이터베이스가 시퀀스에서 기본키에 해당하는 값을 제공할 것입니다.
예상대로 동작하는지 실행 결과를 보겠습니다.
Hibernate: drop table if exists member CASCADE
Hibernate: drop sequence if exists hibernate_sequence
// (1)
Hibernate: create sequence hibernate_sequence start with 1 increment by 1
Hibernate: create table member (member_id bigint not null, primary key (member_id))
// (2)
Hibernate: call next value for hibernate_sequence
# memberId: 1
Hibernate: insert into member (member_id) values (?)실행 결과를 보면 (1)에서 데이터베이스에 시퀀스를 생성합니다.
(2)에서 Member 엔티티를 영속성 컨텍스트에 저장하기 전에 데이터베이스에서 시퀀스 값을 조회하는 것을 볼 수 있습니다.
이 시퀀스 값은 Member 엔티티의 memberId 필드에 할당됩니다.
✔ AUTO 전략
마지막으로 @Id 필드에 @GeneratedValue(strategy = GenerationType.AUTO)를 지정하면 JPA가 데이터베이스의 Dialect에 따라서 적절한 전략을 자동으로 선택합니다.
Dialect는 표준 SQL 등이 아닌 특정 데이터베이스에 특화된 고유한 기능을 의미합니다. 만일 JPA가 지원하는 표준 문법이 아닌 특정 데이터베이스에 특화된 기능을 사용할 경우 Dialect가 처리해 줍니다.
Dialect에 대해서 더 알아보고 싶다면 아래 [심화 학습]을 참고하세요.
필드(멤버 변수)와 열 간의 매핑
앞에서 엔티티와 테이블, 그리고 기본키에 대한 매핑을 살펴보았으니 마지막으로 엔티티 필드(멤버 변수)와 테이블 열 간의 매핑을 통해 엔티티 매핑을 완성해 보겠습니다.
단순히 멤버 변수 레벨에서 사용할 수 있는 애너테이션을 차례차례 설명하는 것보다는 우리가 Spring Data JDBC에서 사용했던 Member, Coffee, Order 엔티티 클래스에 하나씩 애너테이션을 추가해 보면서 해당 애너테이션의 기능이 무엇인지 확인하는 것이 여러분들의 머릿속에 더 오래 기억될 거라 생각합니다.
Member 엔티티 클래스 필드와 열 간의 매핑
package com.springboot.entity_mapping.single_mapping.column;
@NoArgsConstructor
@Getter
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long memberId;
// (1)
@Column(nullable = false, updatable = false, unique = true)
private String email;
...
...
public Member(String email) {
this.email = email;
}
}[코드 3-124] email 필드(멤버 변수)에 열 매핑 애너테이션 추가(Member.java)
- (1)에서 사용한 @Column 애너테이션은 필드와 열을 매핑해 주는 애너테이션입니다. 그런데 만약 @Column 애너테이션이 없고, 필드만 정의되어 있다면 JPA는 기본적으로 이 필드가 테이블의 열과 매핑되는 필드라고 간주하게 됩니다. 또한, @Column 애너테이션에 사용되는 애트리뷰트의 값은 디폴트 값이 모두 적용됩니다.
- 애트리뷰트
- nullable
- 열에 null 값을 허용할지 여부를 지정합니다.
- 디폴트 값은 true입니다.
- email 주소는 일반적으로 회원 정보에서 ID로 많이 사용되며, 따라서 필수 항목이기 때문에 nullable 값을 false로 지정했습니다.
- updatable
- 열 데이터를 수정할 수 있는지 여부를 지정합니다.
- 디폴트 값은 true입니다.
- 여기서는 email 주소가 사용자 ID 역할을 한다고 가정하고 한번 등록되면 수정이 불가능하도록 하기 위해서 updatable 값을 false로 지정했습니다.
- unique
- 하나의 열에 unique 유니크 제약 조건을 설정합니다.
- 디폴트 값은 false입니다.
- email의 경우 고유한 값이어야 하므로 unique 값을 true로 지정했습니다.
- nullable
- 애트리뷰트
✅ @Column 애너테이션이 생략되었거나 애트리뷰트가 기본값을 사용할 경우 주의 사항
int나 long 같은 원시 타입일 경우, @Column 애너테이션이 생략되면 기본적으로 nullable=false입니다.
그런데 예를 들어서 개발자가 int price not null이라는 조건으로 열을 설정하길 원하는데 nullable에 대한 명시적인 설정 없이 단순히 @Column 애너테이션만 추가하면 nullable=true가 기본값이 되기 때문에 테이블에는 int price not null로 열이 설정되는 것이 아니라 int price와 같이 설정이 될 것입니다.
따라서 개발자가 의도하는 바가 int price not null일 경우에는 @Column(nullable=false)라고 명시적으로 지정하든가 아예 @Column 애너테이션 자체를 사용하지 않는 것이 권장됩니다.
그럼 email 필드가 설정한 대로 동작하는지 테스트를 해보도록 하겠습니다.
package com.springboot.entity_mapping.single_mapping.column;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaColumnMappingConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaSingleMappingRunner(EntityManagerFactory emFactory){
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
// testEmailNotNull(); // (1)
// testEmailUpdatable(); // (2)
// testEmailUnique(); // (3)
};
}
private void testEmailNotNull() {
tx.begin();
em.persist(new Member());
tx.commit();
}
private void testEmailUpdatable() {
tx.begin();
em.persist(new Member("hgd@gmail.com"));
Member member = em.find(Member.class, 1L);
member.setEmail("hgd@yahoo.co.kr");
tx.commit();
}
private void testEmailUnique() {
tx.begin();
em.persist(new Member("hgd@gmail.com"));
em.persist(new Member("hgd@gmail.com"));
tx.commit();
}
}[코드 3-125] email 필드 열 설정 동작 테스트
코드 3-125는 email 필드의 설정이 잘 동작하는지 확인하기 위한 테스트 코드입니다.
(1)의 testEmailNotNull() 메서드는 email 필드에 아무 값도 입력하지 않고 데이터를 저장하고 있습니다.
우리가 설정한 email 필드는 nullable=false이기 때문에 에러가 발생해야 합니다.
(2)의 testEmailUpdatable() 메서드는 이미 등록한 email 주소를 다시 수정하고 있습니다.
우리가 설정한 email 필드는 updatable=false이기 때문에 이미 등록한 email 주소는 수정되지 않아야 합니다.
(3)의 testEmailUnique() 메서드는 이미 등록된 emial 주소를 한번 더 등록하고 있습니다.
우리가 설정한 email 필드는 unique=true이기 때문에 에러가 발생해야 합니다.
이제 주석 처리 되어 있는 (1), (2), (3)을 (1)부터 차례대로 하나씩만 주석 해제 한 상태에서 애플리케이션을 실행해보고 결과를 확인해 보도록 하겠습니다.
✔ (1)의 메서드를 호출한 결과
java.lang.IllegalStateException: Failed to execute CommandLineRunner
...
...
Caused by: javax.persistence.PersistenceException:
org.hibernate.PropertyValueException:
not-null property references a null or transient value :
com.codestates.entity_mapping.single_mapping.column.Member.email
...
...nullable=false 즉, null이 아닌 입력 값이 있어야 하는데 존재하지 않기 때문에 PropertyValueException을 래핑 한 PersistenceException이 발생했으므로 nullable=false 설정은 정상적으로 동작했습니다.
✔ (2)의 메서드를 호출한 결과
Hibernate: insert into member (member_id, email) values (default, ?)
INSERT 쿼리가 발생했지만 UPDATE 쿼리가 발생하지 않았습니다.
따라서 updatable=false 설정이 정상적으로 동작했습니다.
✔ (3)의 메서드를 호출한 결과
`java.lang.IllegalStateException: Failed to execute CommandLineRunner`
`Caused by: javax.persistence.PersistenceException: `
org.hibernate.exception.ConstraintViolationException: could not execute statement
Caused by: org.hibernate.exception.ConstraintViolationException:
could not execute statement
Caused by: org.h2.jdbc.JdbcSQLIntegrityConstraintViolationException:
Unique index or primary key violation:
"PUBLIC.UK_MBMCQELTY0FBRVXP1Q58DN57T_INDEX_8 ON PUBLIC.MEMBER(EMAIL NULLS FIRST) VALUES
( /* 1 */ 'hgd@gmail.com' )"; SQL statement:
insert into member (member_id, email) values (default, ?) [23505-212]
unique = true 즉, email 주소는 고유한 값이어야 하는데, 동일한 email 주소가 INSERT 되면서 JdbcSQLIntegrityConstraintViolationException, ConstraintViolationException, PersistenceException이 래핑 되어 순차적으로 전파되었습니다.
따라서 unique = true 설정이 정상적으로 동작했습니다.
열 제약 조건에 대한 예외 발생 테스트
@Column 애너테이션의 애트리뷰트 설정을 진행하면서 여러분은 지금 체계가 잡혀 있지는 않지만 어쨌든 예외 발생과 관련한 테스트를 진행한 것과 마찬가지입니다.
발생한 예외를 세련되게 테스트하는 방법은 [테스팅] 섹션에서 학습할 예정이니 조금만 기다려주세요. ^^
엔티티 클래스에서 발생한 예외 처리 계층은 다르지만 엔티티 클래스 필드의 설정으로 인해 발생한 예외는 API 계층의 DTO 클래스에서 발생한 예외와 마찬가지로 일종의 유효성(Validation) 검증이라고 볼 수 있습니다.
엔티티 클래스에서 발생한 예외는 API 계층까지 전파되므로 API 계층의 GlobalExceptionAdvice에서 캐치(catch) 한 후, 처리할 수 있다는 사실을 기억하기 바랍니다.
package com.springboot.entity_mapping.single_mapping.column;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.*;
import java.time.LocalDateTime;
@NoArgsConstructor
@Getter
@Setter
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long memberId;
@Column(nullable = false, updatable = false, unique = true)
private String email;
// (1)
@Column(length = 100, nullable = false)
private String name;
@Column(length = 13, nullable = false, unique = true)
private String phone;
@Column(nullable = false)
private LocalDateTime createdAt = LocalDateTime.now(); // (2)
// (3)
@Column(nullable = false, name = "LAST_MODIFIED_AT")
private LocalDateTime modifiedAt = LocalDateTime.now();
// (4)
@Transient
private String age;
public Member(String email) {
this.email = email;
}
public Member(String email, String name, String phone) {
this.email = email;
this.name = name;
this.phone = phone;
}
}[코드 3-126] Member 클래스 엔티티 매핑(Member.java)
코드 3-126은 Member 엔티티 클래스와 테이블 간의 매핑 애너테이션을 추가한 전체 소스 코드입니다.
코드 3-125에서 설명하지 않은 나머지 애너테이션을 설명하도록 하겠습니다.
- (1)의 @Column 애너테이션의 추가 설명.
- 애트리뷰트
- length
- 열에 저장할 수 있는 문자 길이를 지정할 수 있습니다.
- 디폴트 값은 255입니다.
- name 필드는 편의상 100으로 지정했습니다.
- length
- 애트리뷰트
- (2)는 회원 정보가 등록될 때의 시간 및 날짜를 매핑하기 위한 필드입니다.
- java.util.Date, java.util.Calendar 타입으로 매핑하기 위해서는 @Temporal 애너테이션을 추가해야 하지만 (2)와 같이 LocalDateTime 타입일 경우, @Temporal 애너테이션은 생략 가능합니다.
- LocalDateTime은 열의 TIMESTAMP 타입과 매핑됩니다.
- 회원 정보가 등록되는 시간 정보를 필드에 전달하기 위해 createdAt 필드에 LocalDateTime.now() 메서드로 현재 시간을 입력하고 있습니다.
- @Column 애너테이션의 name 애트리뷰트를 생략하면 엔티티 클래스 필드의 이름으로 열이 생성되지만 (3)과 같이 name 애트리뷰트에 별도의 이름을 지정해서 엔티티 클래스 필드명과 다른 이름으로 열을 생성할 수 있습니다.
- (4)와 같이 @Transient 애너테이션을 필드에 추가하면 테이블 열과 매핑하지 않겠다는 의미로 JPA가 인식합니다.
- 따라서 데이터베이스에 저장도 하지 않고, 조회할 때 역시 매핑되지 않습니다.
- @Transient은 주로 임시 데이터를 메모리에서 사용하기 위한 용도로 사용됩니다.
Coffee 엔티티 클래스 필드와 열 간의 매핑
package com.springboot.entity_mapping.single_mapping.column;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.*;
import java.time.LocalDateTime;
@NoArgsConstructor
@Getter
@Setter
@Entity
public class Coffee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long coffeeId;
@Column(nullable = false, length = 50)
private String korName;
@Column(nullable = false, length = 50)
private String engName;
@Column(nullable = false)
private int price;
@Column(nullable = false, length = 3)
private String coffeeCode;
@Column(nullable = false)
private LocalDateTime createdAt = LocalDateTime.now();
@Column(nullable = false, name = "LAST_MODIFIED_AT")
private LocalDateTime modifiedAt = LocalDateTime.now();
}[코드 3-127] Coffee 클래스 엔티티 매핑(Coffee.java)
코드 3-127에서는 열 매핑을 적용한 Coffee 엔티티 클래스의 전체 소스 코드입니다.
열 매핑에 사용한 애너테이션들은 이미 앞에서 설명했기 때문에 별도의 설명은 생략하겠습니다.
Order 엔티티 클래스 필드와 열 간의 매핑
package com.springboot.entity_mapping.single_mapping.column;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.*;
import java.time.LocalDateTime;
@NoArgsConstructor
@Getter
@Setter
@Entity(name = "ORDERS")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long orderId;
// (1)
@Enumerated(EnumType.STRING)
private OrderStatus orderStatus = OrderStatus.ORDER_REQUEST;
@Column(nullable = false)
private LocalDateTime createdAt = LocalDateTime.now();
@Column(nullable = false, name = "LAST_MODIFIED_AT")
private LocalDateTime modifiedAt = LocalDateTime.now();
public enum OrderStatus {
ORDER_REQUEST(1, "주문 요청"),
ORDER_CONFIRM(2, "주문 확정"),
ORDER_COMPLETE(3, "주문 완료"),
ORDER_CANCEL(4, "주문 취소");
@Getter
private int stepNumber;
@Getter
private String stepDescription;
OrderStatus(int stepNumber, String stepDescription) {
this.stepNumber = stepNumber;
this.stepDescription = stepDescription;
}
}
}[코드 3-128] Order 클래스 엔티티 매핑(Orders.java)
코드 3-128에서는 열 매핑을 적용한 Order 엔티티 클래스의 전체 소스 코드입니다.
- (1)의 @Enumerated 애너테이션은 enum 타입과 매핑할 때 사용하는 애너테이션입니다.
- @Enumerated 애너테이션은 아래의 두 가지 타입을 가질 수 있습니다.
- EnumType.ORDINAL : enum의 순서를 나타내는 숫자를 테이블에 저장합니다.
- EnumType.STRING : enum의 이름을 테이블에 저장합니다.
- ✅ 주의
- EnumType.ORDINAL로 지정할 경우, 기존에 정의되어 있는 enum 사이에 새로운 enum 하나가 추가된다면 그때부터 테이블에 이미 저장되어 있는 enum 순서 번호와 enum에 정의되어 있는 순서가 일치하지 않게 되는 문제가 발생합니다.
- 따라서 처음부터 이런 문제가 발생하지 않도록 EnumType.STRING을 사용하는 것을 권장하고 있습니다.
- @Enumerated 애너테이션은 아래의 두 가지 타입을 가질 수 있습니다.
엔티티와 테이블 매핑 권장 사용 방법
- 클래스 이름 중복 등의 특별한 이유가 없다면 @Entity와 @Id 애너테이션만 추가합니다.
- 만일 엔티티 클래스가 테이블 스키마 명세의 역할을 하길 바란다면 @Table 애너테이션에 테이블명을 지정해 줄 수 있습니다.
- 기본키 생성 전략은 데이터베이스에서 지원해 주는 AUTO_INCREMENT 또는 SEQUENCE를 이용할 수 있도록 IDENTITY 또는 SEQUENCE 전략을 사용하는 것이 좋습니다.
- @Column 정보를 명시적으로 모두 지정하는 것은 번거롭긴 하지만 다른 누군가가 엔티티 클래스 코드를 확인하더라도 테이블 설계가 어떤 식으로 되어 있는지 한눈에 알 수 있다는 장점이 있습니다.
- 엔티티 클래스 필드 타입이 Java의 원시타입일 경우, @Column 애너테이션을 생략하지 말고, 최소한 nullable=false 설정을 하는 게 좋습니다.
- @Enumerated 애너테이션을 사용할 때 EnumType.ORDINAL을 사용할 경우, enum의 순서가 뒤바뀔 가능성도 있으므로 처음부터 EnumType.ORDINAL 대신에 EnumType.STRING을 사용하는 것이 좋습니다.
핵심 포인트
- @Entity 애너테이션을 클래스 레벨에 추가하면 JPA의 관리대상 엔티티가 된다.
- @Table 애너테이션은 엔티티와 매핑할 테이블을 지정한다.
- @Entity 애너테이션과 @Id 애너테이션은 필수로 추가해야 한다.
- JPA는 IDENTITY, SEQUENCE, TABLE, AUTO 전략 같은 다양한 기본키 생성 전략을 지원한다.
- IDENTITY 전략
- 기본키 생성을 데이터베이스에 위임하는 전략이다.
- SEQUENCE 전략
- 데이터베이스에서 제공하는 시퀀스를 사용해서 기본키를 생성하는 전략이다.
- TABLE 전략
- 별도의 키 생성 테이블을 사용하는 전략이다.
- AUTO 전략
- JPA가 데이터베이스의 Dialect에 따라서 적절한 전략을 자동으로 선택한다.
- IDENTITY 전략
- Java의 원시 타입 필드에서 @Column 애너테이션이 없거나 @Column 애너테이션이 있지만 애트리뷰트를 생략한 경우, 최소한 nullable=false는 설정하는 것이 에러를 미연에 방지하는 길이다.
- java.util.Date, java.util.Calendar 타입으로 매핑하기 위해서는 @Temporal 애너테이션을 추가해야 하지만 LocalDate, LocalDateTime 타입일 경우, @Temporal 애너테이션은 생략 가능하다.
- @Transient 애너테이션을 필드에 추가하면 JPA가 테이블 열과 매핑하지 않겠다는 의미로 인식한다.
- 테이블에 이미 저장되어 있는 enum 순서 번호와 enum에 정의되어 있는 순서가 일치하지 않게 되는 문제가 발생하지 않도록 EnumType.STRING을 사용하는 것이 좋다.
심화 학습
- 식별자에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- Dialect에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- @Column 애너테이션의 애트리뷰트에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
[기본] 엔티티 간의 연관 관계 매핑
지난 챕터에서 우리는 단일 엔티티를 데이터베이스의 테이블과 매핑하는 방법에 대해서 살펴보았습니다.
이번 시간에는 엔티티 간의 연관 관계를 매핑하는 방법에 대해서 알아보도록 하겠습니다.
엔티티 간의 연관 관계 매핑은 JPA 학습 내용 중에서 가장 중요한 부분이며, JPA 입문자들이 가장 이해하기 어려워하는 부분이기도 합니다.
따라서 이번 챕터에서 여러분들이 연관 관계 매핑에 대한 개념을 확실히 이해할 수 있도록 최대한 쉽게 설명을 해보도록 하겠습니다.
어렵다고 넘지 못할 산은 아니니 걱정 말고 잘 따라와 주길 바라봅니다.
JPA 방식의 연관 관계 매핑이 문법적으로 어렵다기보다는 외래키로 관계를 맺는 데이터베이스 테이블 간의 관계와는 다르게 엔티티 클래스는 객체 참조를 통해 서로 관계를 맺기 때문에 아마도 이런 방식의 차이에서 오는 혼란스러움이라고 할 수 있습니다.
따라서 이런 혼란스러움을 최소화하면서 JPA의 연관 관계 매핑을 이해하는 것이 이번 챕터의 핵심입니다.
연관 관계 매핑이란
연관 관계 매핑은 여러분이 Spring Data JDBC에서 이미 경험을 해보았습니다.
Spring Data JDBC를 학습하면서 테이블 설계, 클래스 다이어그램 설계를 통해 회원과 주문, 주문과 커피와의 관계를 도출했었던 것처럼 엔티티 클래스 간의 관계를 만들어주는 것이 바로 연관 관계 매핑입니다.
Spring Data JDBC에서 했던 것처럼 이번 시간에도 역시 엔티티 클래스 간에 관계를 매핑해 주어야 하는 것은 동일합니다.
단, JPA의 방식으로 해야 합니다.
연관 관계 매핑은 참조하는 방향성을 기준으로 생각했을 때 단방향 연관 관계와 양방향 연관 관계로 구분할 수 있습니다.
그리고, 엔티티 간에 참조할 수 있는 객체의 수에 따라서 일대다(1:N), 다대일(N:1), 다대다(N:N), 일대일(1:1)의 연관 관계로 나눌 수 있습니다.
JPA 연관 관계는 단순히 문장으로 설명하면 혼란스러울 수 있습니다.
따라서 우리가 구현하고 있는 커피 주문 샘플 애플리케이션에서 Member 클래스와 Order 클래스의 관계를 통해서 JPA의 연관 관계를 설명하겠습니다.
단방향 연관 관계

[그림 3-55] Member가 Order를 참조할 수 있는 단방향 관계]
[그림 3-55]에서는 Member 클래스가 Order 객체를 원소로 포함하고 있는 List 객체를 가지고 있으므로, Order를 참조할 수 있습니다.
따라서 Member는 Order의 정보를 알 수 있습니다.
하지만 Order 클래스는 Member 클래스에 대한 참조 값이 없으므로 Order 입장에서는 Member 정보를 알 수 없습니다.

[그림 3-56] Order가 Member를 참조할 수 있는 단방향 관계
[그림 3-56]에서는 Order 클래스가 Member 객체를 가지고 있으므로, Member 클래스를 참조할 수 있습니다.
따라서 Order는 Member의 정보를 알 수 있습니다.
하지만 Member 클래스는 Order 클래스에 대한 참조 값이 없으므로 Member 입장에서는 Order 정보를 알 수 없습니다.
이처럼 한쪽 클래스만 다른 쪽 클래스의 참조 정보를 가지고 있는 관계를 단방향 연관 관계라고 합니다.
단방향 연관 관계 이해 되셨죠?
양방향 연관 관계

[그림 3-57] Order와 Member가 서로 참조할 수 있는 양방향 관계
[그림 3-57]에서는 Member 클래스가 Order 객체를 원소로 포함하고 있는 List 객체를 가지고 있고, Order 클래스를 참조할 수 있습니다.
따라서 Member는 Order의 정보를 알 수 있습니다.
그리고 Order 클래스 역시 Member 객체를 가지고 있으므로, Member 클래스를 참조할 수 있습니다.
결론적으로 두 클래스가 모두 서로의 객체를 참조할 수 있으므로, Member는 Order 정보를 알 수 있고, Order는 Member 정보를 알 수 있습니다.
이처럼 양쪽 클래스가 서로의 참조 정보를 가지고 있는 관계를 양방향 연관 관계라고 합니다.
JPA는 단방향 연관 관계와 양방향 연관 관계를 모두 지원하는 반면에 Spring Data JDBC는 단방향 연관 관계만 지원합니다.
일대다 단방향 연관 관계

[그림 3-58] Member와 Order의 일대다 단방향 관계
일대다의 관계란 일(1)에 해당하는 클래스가 다(N)에 해당하는 객체를 참조할 수 있는 관계를 의미합니다.
[그림 3-58]와 같이 한 명의 회원이 여러 건의 주문을 할 수 있으므로 Member와 Order는 일대다 관계입니다.
그리고 Member만 List<Order> 객체를 참조할 수 있으므로 단방향 관계입니다.
즉, [그림 3-58]은 일대다 단방향 연관 관계를 가지고 있습니다.
그런데 결론부터 이야기하자면 일대다 단방향 매핑은 잘 사용하지 않습니다.

[그림 3-59] MEMBER 테이블과 ORDERS 테이블의 관계
[그림 3-39]는 MEMBER 테이블과 ORDERS 테이블의 관계를 나타내는 다이어그램입니다.
여러분들이 잘 알고 있다시피 테이블 간의 관계에서는 일대다 중에서 ‘다’에 해당하는 테이블에서 ‘일’에 해당하는 테이블의 기본키를 외래키로 가집니다.
따라서 ORDERS 테이블이 MEMBER 테이블의 기본키인 member_id를 외래키로 가집니다.
그런데 [그림 3-58]에서는 Order 클래스가 ‘테이블 관계에서 외래키에 해당하는 MEMBER 클래스의 참조값’을 가지고 있지 않기 때문에 일반적인 테이블 간의 관계를 정상적으로 표현하지 못하고 있습니다.
따라서, Order 클래스의 정보를 테이블에 저장하더라도 외래키에 해당하는 MEMBER 클래스의 memberId 값이 없는 채로 저장이 됩니다.
이러한 문제 때문에 일대다 단방향 매핑은 잘 사용하지 않습니다.
일대다 단방향 매핑을 잘 사용하지 않는다면 굳이 매핑하는 방법을 알 필요가 있을까요?
네, 있습니다.
단, 일대다 단방향 매핑 하나만 사용하는 경우는 드물고, 이어서 배우는 다대일 단방향 매핑을 먼저 한 후에 필요한 경우, 일대다 단방향 매핑을 추가해서 양방향 연관 관계를 만드는 것이 일반적입니다.
다대일 연관 관계

[그림 3-60] Order와 Member의 다대일 단방향 관계
다대일의 관계란 다(N)에 해당하는 클래스가 일(1)에 해당하는 객체를 참조할 수 있는 관계를 의미합니다.
[그림 3-60]과 같이 여러 건의 주문은 한 명의 회원에 속할 수 있으므로 Order와 Member는 다대일 관계입니다.
그리고 Order만 Member 객체를 참조할 수 있으므로 단방향 관계입니다.
즉, [그림 3-60]은 다대일 단방향 연관 관계를 가지고 있습니다.
[그림 3-60]의 다대일 단방향 매핑은 [그림 3-59]에서 ORDERS 테이블이 MEMBER 테이블의 member_id를 외래키로 가지듯이 Order 클래스가 Member 객체를 외래키처럼 가지고 있습니다.
즉, 다대일 단방향 매핑은 테이블 간의 관계처럼 자연스러운 매핑 방식이기 때문에 JPA의 엔티티 연관 관계 중에서 가장 기본으로 사용되는 매핑 방식입니다.
✔ 코드로 보는 다대일 연관 관계 매핑 방법
- 다(N)에 해당하는 Order 클래스
package com.springboot.entity_mapping.many_to_one_unidirection;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.*;
import java.time.LocalDateTime;
@NoArgsConstructor
@Getter
@Setter
@Entity(name = "ORDERS")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long orderId;
@Enumerated(EnumType.STRING)
private OrderStatus orderStatus = OrderStatus.ORDER_REQUEST;
@Column(nullable = false)
private LocalDateTime createdAt = LocalDateTime.now();
@Column(nullable = false, name = "LAST_MODIFIED_AT")
private LocalDateTime modifiedAt = LocalDateTime.now();
@ManyToOne // (1)
@JoinColumn(name = "MEMBER_ID") // (2)
private Member member;
public void addMember(Member member) {
this.member = member;
}
public enum OrderStatus {
ORDER_REQUEST(1, "주문 요청"),
ORDER_CONFIRM(2, "주문 확정"),
ORDER_COMPLETE(3, "주문 완료"),
ORDER_CANCEL(4, "주문 취소");
@Getter
private int stepNumber;
@Getter
private String stepDescription;
OrderStatus(int stepNumber, String stepDescription) {
this.stepNumber = stepNumber;
this.stepDescription = stepDescription;
}
}
}[코드 3-129] 다(N)에 해당하는 Order 클래스의 연관관계 매핑
다대일의 연관관계 매핑에서는 코드 3-129의 (1), (2)와 같은 방법으로 매핑을 할 수 있습니다.
먼저 (1)과 같이 @ManyToOne 애너테이션으로 다대일의 관계를 명시합니다.
그리고 (2)와 같이 @JoinColumn 애너테이션으로 ORDERS 테이블에서 외래키에 해당하는 열 이름을 적어줍니다.
일반적으로 부모 테이블에서 기본키로 설정된 열 이름과 동일하게 외래키 열을 만드는데, 여기서는 MEMBER 테이블의 기본키 열 이름이 “MEMBER_ID” 이기 때문에 동일하게 적어주었습니다.
다대일 단방향 연관 관계이기 때문에 코드 3-129의 (1), (2)와 같이 다(N) 쪽에서만 설정을 해주면 매핑 작업은 끝납니다.
이제 매핑된 두 엔티티 클래스를 이용해서 실제 테이블에 데이터를 저장해 보겠습니다.
✔ 다대일 매핑을 이용한 회원과 주문 정보 저장
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaManyToOneUniDirectionConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaManyToOneRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
mappingManyToOneUniDirection();
};
}
private void mappingManyToOneUniDirection() {
tx.begin();
Member member = new Member("hgd@gmail.com", "Hong Gil Dong",
"010-1111-1111");
// (1)
em.persist(member);
Order order = new Order();
order.addMember(member); // (2)
em.persist(order); // (3)
tx.commit();
// (4)
Order findOrder = em.find(Order.class, 1L);
// (5) 주문에 해당하는 회원 정보를 가져올 수 있다.
System.out.println("findOrder: " + findOrder.getMember().getMemberId() +
", " + findOrder.getMember().getEmail());
}
}[코드 3-130] 다대일 연관관계 매핑을 이용한 회원과 주문 정보 저장 예
- 먼저 주문을 하기 위해서는 회원 정보가 필요합니다. (1)에서 회원 정보를 저장합니다.
- (1)에서 저장한 회원 정보의 주문 정보를 저장하기 위해서 (2)와 같이 order 객체에 member 객체를 추가합니다. order 객체에 추가된 member 객체는 외래키의 역할을 합니다.
우리가 ORDER 테이블에 주문 정보를 저장하는 INSERT 쿼리문을 떠올려 보세요. INSERT 쿼리문에는 MEMBER 테이블의 MEMBER_ID가 외래키로 포함이 될 것입니다. (2)와 같이 추가되는 member 객체는 이 MEMBER_ID 같은 외래키의 역할을 한다고 생각하면 됩니다.
- (3)에서 주문 정보를 저장합니다.
- (4)에서는 등록한 회원에 해당하는 주문 정보를 조회하고 있습니다.
- (5)에서 findOrder.getMember()와 같이 주문에 해당하는 회원 정보를 가져와서 출력하고 있습니다.
(5)에서 findOrder.getMember().getMemberId()와 같이 객체를 통해 다른 객체의 정보를 얻을 수 있는 것을 객체 그래프 탐색이라고 합니다.
이처럼 다대일 관계에서는 일(1)에 해당하는 객체의 정보를 얻을 수 있습니다.
✔ 다대일 매핑에 일대다 매핑 추가
그런데 곰곰이 생각해 보세요.
카페 주인 입장에서는 이 주문을 누가 했는지 주문한 회원의 회원 정보를 알아야 할 경우에는 다대일 매핑을 통해 주문한 사람의 정보를 조회할 수 있습니다.
그런데 회원 입장에서는 내가 주문한 주문의 목록을 확인할 수 있어야 할 텐데 다대일 매핑만으로는 member 객체를 통해 내가 주문한 주문 정보인 order 객체들을 조회할 수 없습니다.
이 경우, 다대일 매핑이 되어 있는 상태에서 일대다 매핑을 추가해 양방향 관계를 만들어주면 됩니다.
- 일대다에서 일(1)에 해당하는 Member 클래스
package com.springboot.entity_mapping.many_to_one_bidirection;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.*;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
@NoArgsConstructor
@Getter
@Setter
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long memberId;
@Column(nullable = false, updatable = false, unique = true)
private String email;
@Column(length = 100, nullable = false)
private String name;
@Column(length = 13, nullable = false, unique = true)
private String phone;
@Column(nullable = false)
private LocalDateTime createdAt = LocalDateTime.now();
@Column(nullable = false, name = "LAST_MODIFIED_AT")
private LocalDateTime modifiedAt = LocalDateTime.now();
// (1)
@OneToMany(mappedBy = "member")
private List<Order> orders = new ArrayList<>();
public Member(String email) {
this.email = email;
}
public Member(String email, String name, String phone) {
this.email = email;
this.name = name;
this.phone = phone;
}
public void addOrder(Order order) {
orders.add(order);
}
}[코드 3-131] 일(1)에 해당하는 Member 클래스의 연관관계 매핑
코드 3-131에서는 다대일 매핑에 일대다 매핑을 추가해서 양방향 관계를 만들어주었습니다.
(1)의 @OneToMany(mappedBy = "member")를 주목해 주세요.
JPA에서 가장 이해하기 어려워하는 부분 중에 하나가 바로 이 @OneToMany 애너테이션의 mappedBy 애트리뷰트입니다.
일대다 단방향 매핑의 경우에는 mappedBy 애트리뷰트의 값이 필요하지 않습니다.
mappedBy는 참조할 대상이 있어야 하는데 일대다 단방향 매핑의 경우 참조할 대상이 없으니까요.
공식 API 문서에서는 @OneToMany 애너테이션의 mappedBy에 대해서 다음과 같이 설명하고 있습니다.
public @interface OneToMany {
...
...
/**
* The field that owns the relationship.
* Required unless the relationship is unidirectional.
*/
String mappedBy() default "";
...
...
}mappedBy에 있는 주석을 해석해 보면,
mappedBy의 값은 관계를 소유하고 있는 필드를 지정하는 것으로 이해할 수 있습니다.
그런데 솔직히 이 문장만으로는 mappedBy의 값으로 뭘 지정해야 되는지 알기가 힘듭니다.
자.. 잘 생각해 보세요.
MEMBER 테이블과 ORDER 테이블의 관계에서 ORDER 테이블의 외래키로 무얼 지정하나요?
바로 MEMBER 테이블의 기본키 열인 MEMBER_ID의 값을 지정합니다.
그렇다면 Order 클래스에서 외래키의 역할을 하는 필드는 무엇일까요?
바로 member 필드입니다.
그렇기 때문에 [코드 3-131]의 (1)에서 mappedBy의 값이 “member”가 되는 것입니다.
mappedBy의 값으로 무얼 지정해야 할지 도저히 모르겠다면 두 가지만 기억하세요.
(1) 두 객체들 간에 외래키의 역할을 하는 필드는 무엇인가?(2) 외래키의 역할을 하는 필드는 다(N)에 해당하는 클래스 안에 있다.
모든 관계의 중심을 외래키에서 부터 시작하면 연관 관계 매핑은 의외로 쉬워집니다!
이제 양방향으로 매핑된 두 엔티티 클래스를 이용해서 회원 정보와 주문 정보를 저장한 후, 회원 정보를 통해 주문한 회원의 주문 정보를 조회해 보도록 하겠습니다.

✔ 다대일 매핑에 일대다 매핑을 추가하여 주문 정보 조회
package com.springboot.entity_mapping.many_to_one_bidirection;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
@Configuration
public class JpaManyToOneBiDirectionConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaManyToOneRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
mappingManyToOneBiDirection();
};
}
private void mappingManyToOneBiDirection() {
tx.begin();
Member member = new Member("hgd@gmail.com", "Hong Gil Dong",
"010-1111-1111");
Order order = new Order();
member.addOrder(order); // (1)
order.addMember(member); // (2)
em.persist(member); // (3)
em.persist(order); // (4)
tx.commit();
// (5)
Member findMember = em.find(Member.class, 1L);
// (6) 이제 주문한 회원의 회원 정보를 통해 주문 정보를 가져올 수 있다.
findMember
.getOrders()
.stream()
.forEach(findOrder -> {
System.out.println("findOrder: " +
findOrder.getOrderId() + ", "
+ findOrder.getOrderStatus());
});
}
}[코드 3-132] 일대다 연관관계 매핑을 추가하여 주문 정보를 조회하는 예
- 먼저 (1)에서 member 객체에 order 객체를 추가해 줍니다.
- member 객체에 order 객체를 추가해주지 않아도 테이블에는 member 정보와 order 정보가 정상적으로 저장이 됩니다.
- 하지만 member 객체에 order 객체를 추가해주지 않으면 (5)에서 find() 메서드로 조회한 member 객체로 order를 그래프 탐색하면 order 객체를 조회할 수 없습니다.
- 이유는 바로 find() 메서드가 1차 캐시에서 member 객체를 조회하는데 (1)에서 order를 추가해주지 않으면 1차 캐시에 저장된 member 객체는 order를 당연히 가지고 있지 않기 때문입니다.
- 그리고 (2)에서 order 객체에 역시 member 객체를 추가해 줍니다.
- order 객체에 member 객체를 추가해 주는 이유는 다대일 관계에서 보았듯이 member가 order의 외래키 역할을 하기 때문에 order 객체 저장 시, 반드시 필요합니다.
- 만약에 order 객체에 member 객체를 추가해주지 않으면 ORDERS 테이블에 저장된 주문 정보의 MEMBER_ID 필드가 null이 될 것입니다.
- 즉 외래키로 참조할 객체 정보(member)가 없기 때문입니다.
- (3)에서 회원 정보를 저장하고, (4)에서 주문 정보를 저장합니다.
- (5)에서 방금 저장한 회원 정보를 1차 캐시에서 조회합니다.
- 일대다 양방향 관계를 매핑했기 때문에 (6)과 같이 find() 메서드로 조회한 member로부터 객체 그래프 탐색을 통해 List<order> 정보에 접근할 수 있습니다.
다대다 연관 관계
실무에서는 다대다의 관계를 가지는 테이블을 설계하는 경우도 굉장히 많습니다.
우리가 만들고 있는 커피 주문 샘플 애플리케이션에서도 주문(Order)과 커피(Coffee)의 관계는 다대다 관계입니다.
하나의 주문에 여러 개의 커피가 속할 수 있고, 하나의 커피는 여러 주문에 속할 수 있으니 다대다 관계인 것입니다.
그렇다면 JPA에서 다대다에 해당하는 엔티티 클래스는 어떻게 매핑해야 할까요?
테이블 설계 시, 다대다의 관계는 중간에 테이블을 하나 추가해서 두 개의 일대다 관계를 만들어주는 것이 일반적인 방법입니다.

[그림 3-61] 다대다 관계의 테이블을 두 개의 1대다 관계로 설계한 예
[그림 3-61]에서는 다대다 관계에 있는 ORDERS 테이블과 COFFEE 테이블 사이에 ORDER_COFFEE 테이블을 두고 두 개의 1대 다 관계로 만들었습니다.
ORDER_COFFEE 테이블은 ORDERS 테이블의 외래키와 COFFEE 테이블의 외래키를 가지고 있습니다.
테이블 설계가 되었으니 이제 클래스 간의 연관 관계 매핑을 하면 됩니다.
일대다 단방향 매핑은 외래키를 포함하지 않기 때문에 자주 사용되지 않는 매핑 방법이라고 앞에서 설명했습니다.
그렇다면 두 개의 다대일 매핑이 필요하다는 얘기가 됩니다. 그러고 나서 현실적으로 다대일 매핑을 통해 객체 그래프 탐색으로 원하는 객체를 조회할 수 없다면 그때 일대다 양방향 매핑을 추가하면 됩니다.
다대다 연관 관계 매핑은 Spring Data JPA 학습 이후, 실습 과제를 통해 여러분의 몫으로 남겨두겠습니다.
앞에서 다대일의 관계를 이해했다면 다대다 관계 실습 과제 역시 잘 구현할 수 있을 거라고 생각합니다.
다대일의 관계가 이해가 되지 않는 다면 과제를 하기 전에 다대일의 관계부터 이해되도록 반복해서 연습하길 바랍니다.
일대일 연관관계
일대일 연관 관계 매핑은 다대일 단방향 연관 관계 매핑과 매핑 방법은 동일합니다.
단지 @ManyToOne 애너테이션이 아닌 @OneToOne 애너테이션을 사용한다는 차이만 있습니다.
일대일 단방향 매핑에 양방향 매핑을 추가하는 방법도 다대일에 일대다 매핑을 추가하는 방식과 동일합니다.
단, 역시 @ManyToOne 애너테이션이 아닌 @OneToOne 애너테이션을 사용합니다.
일대일 연관 관계 매핑 역시 실습으로 남겨두겠습니다.
엔티티 간의 연관 관계 매핑 권장 방법
- 일대다 매핑은 사용하지 않습니다.
- 제일 먼저 다대일 단방향 매핑부터 적용합니다.
- 다대일 단방향 매핑을 통해 객체 그래프 탐색으로 조회할 수 없는 정보가 있을 경우, 그때 비로소 양방향 매핑을 적용합니다.
JPA는 굉장히 방대한 내용을 다루고 있기 때문에 하루아침에 JPA의 모든 파트를 여러분의 것으로 만들 수는 없습니다.
하지만 이번 유닛에서 설명한 JPA의 기본적인 동작 방식과 엔티티 매핑, 엔티티 간의 연관관계 매핑이 JPA의 핵심 중에 핵심이라고 볼 수 있기 때문에 이번 유닛에서 언급한 내용들만 여러분들 것으로 만들게 되면 나머지 부분들은 여러분들이 스스로 학습하는데 큰 무리는 없을 거라고 생각합니다.
JPA의 나머지 관련된 내용을 더 알고 싶다면 [심화 학습]을 참고하세요.
핵심 포인트
- Spring Data JDBC는 엔티티 간에 단방향 매핑만 지원하지만 JPA는 단방향과 양방향 매핑을 모두 지원한다.
- JPA는 엔티티 간에 일대다, 다대일, 다대다, 일대일 연관 관계 매핑을 지원한다.
- 일대다 관계는 외래키를 가지고 있어야 할 엔티티에 외래키 역할을 하는 객체 참조가 없기 때문에 가급적 사용하지 않는 것이 좋다.
- 다대일 매핑(@ManyToOne)은 다대일에서 ‘다’에 해당하는 엔티티에서 사용한다.
- @JoinColumn 애너테이션은 다대일 매핑(@ManyToOne)에 사용한다.
- @JoinColumn 애너테이션의 name 애트리뷰트 값에는 테이블 조인 시 사용되는 외래키가 저장되는 열 이름을 지정한다.
- 일대다(@OneToMany) 양방향 매핑은 다대일에서 ‘일’에 해당하는 엔티티에서 사용한다.
- @OneToMany의 mappedBy 애트리뷰트의 값으로 외래키 역할을 하는 객체의 필드이름을 지정한다.
- 다대다 연관 관계 매핑은 두 개의 다대일 단방향 매핑을 적용하고, 필요한 경우 양방향 매핑을 적용한다.
- 일대일 연관 관계 매핑 방식은 @OneToOne 애너테이션을 사용한다는 것 외에 @ManyToOne 단방향 방식, 양방향 방식과 동일하다.
심화 학습
- 엔티티 클래스의 연관 관계에 대해서 더 알아보고 싶다면 아래 링크를 참고하세요.
- JPA에서 FETCH가 무엇이고, FETCH 방식에는 어떤 것이 있는지 알아보고 싶다면 아래 링크를 참고하세요.
- JPA에서 CASCADE가 무엇인지 알아보고 싶다면 아래 링크를 참고하세요.