
OOP(Object-Oriented Programming) Basic
잠시 컴퓨터에서 눈을 돌려 주위를 살펴봅시다. 무엇이 보이나요?
각자의 위치한 장소에 따라 각기 다른 여러 사물과 사람이 보일 것 같네요. 책상, 의자, 전등, 시계 등 우리가 주변에서 흔히 볼 수 있는 **'모든 실재(實在)하는 어떤 대상'**을 프로그래밍 언어에서는 **객체(Object)**라고 부릅니다.
사실 앞서 예시로 든 무생물뿐만 아니라 사람과 동물, 심지어 눈에 보이지 않는 어떤 논리나 사상, 개념 같은 무형의 대상들도 객체라는 범주에 포함될 수 있습니다.
한마디로, 객체는 우리가 보고 느끼고 인지할 수 있는 모든 것을 의미한다고 할 수 있습니다.
우리가 앞으로 중요하게 다룰 ‘객체지향 프로그래밍(OOP, Object Oriented Programming)’ 개념은 바로 이 객체로부터 시작됩니다.
객체지향이론의 핵심 개념은 실제 세계는 이러한 객체들로 구성되어 있으며, 발생하는 모든 사건들은 이 객체들 간의 상호작용을 통해 발생한다는 전제로부터 출발합니다.
컴퓨터 프로그래밍의 관점에서 보면 일련의 명령어들의 나열을 통해 컴퓨터에게 말을 건네는 절차적 프로그래밍 방식과는 다르게, 객체지향적 프로그래밍은 **"프로그래밍에서 필요한 데이터를 한 데 모아 추상화시켜 상태와 행위를 가진 객체를 만들고 그 객체들 간의 협력과 유기적인 상호작용을 통해 특정 기능을 구성"**하는 프로그래밍 방법론을 지칭합니다.
즉, 객체지향 프로그래밍은 실제 사물의 속성(state)과 기능(behavior)을 분석한 후에 이것을 프로그래밍의 변수와 함수로 정의함으로 실제 세계를 최대한 컴퓨터 프로그래밍에 반영하고자 하는 시도라 설명할 수 있습니다.
잠시 우리가 어릴 때 한 번쯤 가지고 놀아봤던 레고를 한번 떠올려볼까요?
레고 하나하나가 독립적인 속성을 가지고 있는 것과 동시에 레고 조각들을 모아 내가 상상하는 하나의 멋진 결과물을 만들어낼 수 있습니다. 물론 비유이기 때문에 100% 들어맞는 설명이라 하기는 어렵겠지만, 객체지향 프로그래밍도 이와 유사하다고 할 수 있습니다.
특정 사물이 가지는 속성과 기능을 하나의 독립적인 레고 조각으로 만들고, 이를 하나씩 하나씩 결합하여 원하는 결과물을 만들어가는 과정이 바로 객체지향적 설계가 가지는 핵심이라 할 수 있습니다. 벌써 재밌게 들리지 않나요?
조금만 더 구체적으로 설명하자면, 이렇게 레고 조각을 쪼개고 합치는 과정을 통해 프로그래밍을 하는 데에는 몇 가지 큰 이점들이 존재합니다.
먼저, 각 레고 조각들은 하나의 완전하고 독립적인 기능을 가지기 때문에, 그 자체로 유용하고 손쉽게 재활용할 수 있습니다. 따라서 기존 코드를 활용해서 새로운 코드를 상대적으로 손쉽게 작성할 수 있고, 코드 간의 관계 설정을 통해 적은 노력으로도 쉽게 코드를 변경할 수 있게 합니다.
결과적으로 프로그래밍 설계의 측면에서 보면 프로그램 개발 및 유지 보수에 드는 비용과 시간을 획기적으로 줄일 수 있고, 객체를 통해 데이터를 관리하여 데이터를 손실 없이 관리하기에 용이합니다.
지금 당장은 이해가 되지 않더라도 괜찮습니다. 좀 더 구체적인 내용들은 차차 학습을 통해 알아갈 예정이니 지금은 ‘아 그런 게 있구나' 정도로 생각하고 지나가도 좋습니다.
이런 맥락에서 우리는 이번 유닛과 다음 유닛을 통해 자바 언어의 맥락에서 객체지향 프로그래밍이 어떤 핵심적인 내용을 담고 있고, 어떻게 활용될 수 있는지를 중심으로 학습을 진행할 예정입니다.
객체지향 프로그래밍 콘텐츠는 각각 객체지향 프로그래밍 기초와 객체지향 프로그래밍 심화 두 파트로 나뉘어 있습니다. 그중 기초에 해당하는 이번 유닛에서는 주로 자바 객체지향 프로그래밍의 가장 기초적인 토대가 되는 기본적인 내용들을 학습할 예정입니다.
앞서 언급했듯, 먼저 객체 지향 프로그래밍의 가장 기본적인 단위이자 시작점인 객체, 그리고 그 객체를 만들어내기 위해 필요한 **‘클래스(Class)’**에 대한 내용을 학습합니다. 좀 더 구체적으로, **클래스를 만들기 위해 필요한 필드(Field)와 메서드(Method), 그리고 생성자(Constructor)**를 이해하는 시간을 가질 것입니다.
이 유닛에서 학습하는 내용들은 기본적인 내용들이지만 매우 중요한 내용입니다. 따라서 유어클래스에서 제공하는 자료들과 구글링을 통해 추가적으로 찾을 수 있는 자료를 통해 기초를 단단하게 가져가는 것을 권장드립니다.
마지막으로 "기억보다 기록을"이라는 교훈을 따라 배웠던 내용들을 개인 노트나 블로깅을 통해 꼼꼼하게 정리하고 기록해 봅시다.
클래스(Class)와 객체(Object)
이번 챕터에서는 객체지향 프로그래밍의 가장 기본이자 근간이라 할 수 있는 클래스와 객체에 대한 내용을 학습할 예정입니다.
다음의 학습 목표를 통해 이번 챕터의 학습 내용을 먼저 확인해 봅시다.
학습 목표
- 객체지향 프로그래밍의 가장 기본적인 토대인 객체를 이해할 수 있다.
- 객체를 만드는 데 필요한 클래스의 개념을 이해하고, 그 구성요소와 기본 문법을 설명할 수 있다.
- 객체의 두 가지 구성 요소, 속성과 기능이 무엇인지 이해할 수 있다.
- 클래스에 기반하여 new 키워드를 통해 객체를 생성하고, 이를 활용할 수 있다.
- 클래스와 객체의 차이에 대해 설명하고, 둘의 관계를 정의할 수 있다.
클래스와 객체
앞서 우리는 객체가 우리가 인지할 수 있는 ‘실재하는 모든 것’이자 ‘사용할 수 있는 실체'를 의미한다고 배웠습니다.
**클래스(Class)**란 이러한 **객체를 정의한 '설계도(blueprint)' 또는 '틀(frame)’**이라 정의할 수 있습니다. 즉, 클래스는 객체를 생성하는 데 사용되며, 반대로 객체는 클래스에 정의되고 설계된 내용 그대로 생성됩니다. 따라서 이 둘은 서로 떼려야 뗄 수 없는 불가분의 관계에 있습니다.
여기서 꼭 기억하고 넘어가야 할 한 가지는, 클래스는 객체 그 자체가 아니라 단지 객체를 생성하는 데 사용되는 하나의 틀이라는 사실입니다.
다른 말로 설명하면, 클래스는 객체 그 자체가 될 수 없습니다. 우리의 실생활로 예를 들자면 클래스와 객체의 관계는 마치 어떤 제품의 설계도와 제품과의 관계로 비유할 수 있습니다. TV의 설계도가 TV 그 자체가 될 수 없는 것처럼 클래스 또한 객체 그 자체가 될 수 없습니다.
종종 처음 객체지향 프로그래밍을 배울 때에 혼동할 수 있는 부분이기 때문에 처음부터 이 둘을 꼭 구분하여 기억해야 합니다.
다음의 그림을 통해 좀 더 구체적인 내용을 학습해 봅시다.

위의 그림은 집의 설계도와 실제 집의 관계를 통해 앞서 설명했던 클래스와 객체의 관계를 잘 보여주고 있습니다.
쉽게 확인할 수 있듯이, 어떤 집에 대한 설계도(클래스)가 먼저 정의되어 있고, 이 설계도를 통해 각각의 집들이 만들어졌습니다.
이렇게 클래스를 통해 생성된 객체를 우리는 해당 클래스의 **인스턴스(instance)**라 부릅니다. 또한 클래스로부터 객체를 만드는 과정을 우리는 **인스턴스화(instantiate)**라 지칭합니다.
그렇다면 객체와 인스턴스의 차이는 무엇일까요?
사실 객체와 인스턴스는 같은 말이라 차이를 두는 것에 큰 의미는 없으며, 따라서 이 두 용어를 혼용하여 사용할 수 있습니다.
그럼에도, 조금 엄격하게 두 용어를 구분해 보자면, 객체는 모든 인스턴스를 포괄하는 넓은 의미를 가지고 있는 반면, 인스턴스는 해당 객체가 어떤 클래스로부터 생성된 것인지를 강조한다는 데 그 차이가 있다고 할 수 있습니다.
위의 집의 예시에서 각각의 집은 일반적인 의미에서 객체이고, 조금 더 구체적인 표현으로 집의 설계도로부터 만들어진 집이라는 의미에서 집 클래스의 인스턴스라고 할 수 있습니다.
마지막으로, 앞서 설명했듯이 집의 설계도는 집 자체가 될 수 없고, 단지 집을 만들기 위해 필요한 요건들(구조와 모양 등)을 정의해 놓은 것에 불과합니다. 위와 같은 그림으로 보면 직관적으로 이해할 수 있는 부분이지만, 실제 코딩을 하다 보면 종종 헷갈릴 수 있는 부분이기에 잘 기억해 둡시다.
그렇다면 왜 클래스를 정의하고 이것을 통해 객체를 생성해야 할까요?
주로 많이 사용하는 아래의 붕어빵 기계와 붕어빵 이미지를 통해서 한번 알아봅시다.
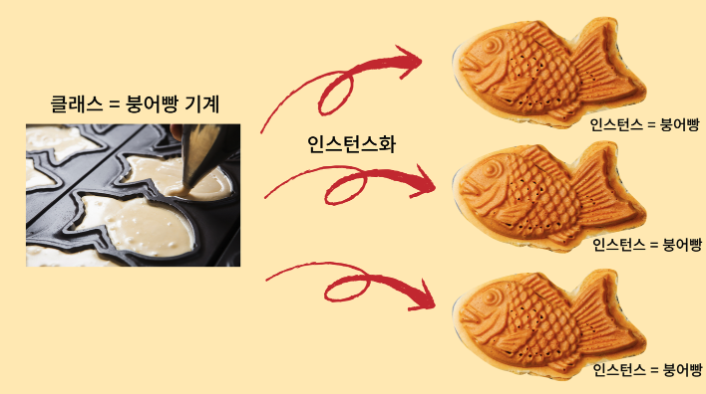
붕어빵을 만드는 데 있어서, 최초에 붕어빵 만드는 기계를 잘 만들어 놓으면 매번 붕어빵을 어떻게 만들어야 할 매번 고민하지 않아도 될 것입니다. 잘 만들어진 붕어빵 기계는 백 번이고, 수 천 번이고 계속해서 같은 모양의 붕어빵을 잘 만들어낼 수 있습니다.
이와 마찬가지로 클래스를 한번 잘 정의해 놓으면, 매번 객체를 생성할 때마다 어떻게 객체를 만들어야 할지 더 이상 고민하지 않고, 그저 클래스로부터 객체를 생성해서 사용하기만 하면 됩니다.
클래스의 구성요소와 기본 문법
그렇다면 클래스는 어떻게 정의할 수 있을까요?
클래스는 기본적으로 class 키워드를 사용하여 다음과 같이 정의합니다. 클래스명은 주로 대문자로 시작하는 것이 관례입니다.
class 클래스명 { // 클래스 정의
-- 생략 --
}
더 나아가, 클래스는 크게 네 가지의 요소로 구성되어 있습니다.
이제부터 하나씩 학습해 나가겠지만 이 네 가지 구성요소는 각각 필드(field), 메서드(method), 생성자(constructor), 그리고 **이너 클래스(inner class)**입니다.
자세한 내용은 뒤에서 배울 예정이니 여기서는 각각의 요소를 가볍게만 언급하고 지나가도록 하겠습니다.
public class ExampleClass {
int x = 10; // (1)필드
void printX() {...} // (2)메서드
ExampleClass {...} // (3)생성자
class ExampleClass2 {...} // (4)이너 클래스
}뒤에서 좀 더 자세히 배우게 되겠지만, 위의 네 가지 구성 요소를 간략하게 설명하면 다음과 같습니다.
(1) 필드 - 클래스의 속성을 나타내는 변수입니다. 자동차로 예를 들면 모델명, 컬러, 바퀴의 수 등이 포함될 수 있습니다.
(2) 메서드 - 클래스의 기능을 나타내는 함수입니다. 자동차를 예로 들면 시동하기, 가속하기, 정지하기 등이 포함될 수 있습니다.
(3) 생성자 - 클래스의 객체를 생성하는 역할을 합니다. 뒤의 내용에서 좀 더 자세히 학습하도록 합니다.
(4) 이너 클래스 - 클래스 내부의 클래스를 의미합니다.
뒤에서 좀 더 구체적으로 보겠지만, 위의 구성 요소들 중 생성자를 제외한 나머지 3가지 요소를 우리는 클래스의 **멤버(member)**라 부릅니다.
이 중에서 필드와 메서드는 각각의 클래스가 가지는 속성(state)과 기능(behavior)을 대표합니다. 속성과 기능은 해당 클래스와 관련된 데이터의 집합이며, 핵심적인 정보를 담고 있다고 할 수 있습니다.
코드 예제
이제 앞서 Java 기초 유닛에서 실습했었던 것과 비슷한 사칙연산을 수행하는 간단한 계산기 클래스를 통해 클래스의 구성요소와 문법에 대해 알아보도록 합시다.
먼저 아래 이미지와 같이 src/main/java 패키지 아래 SimpleCalculatorTest라는 이름의 자바 클래스 파일을 생성합니다.
파일이 생성되었다면, 아래 코드 예제를 반드시 인텔리제이에서 하나씩 입력해 보면서, 클래스의 기본 구조에 대해서 이해해 보도록 합니다.
코딩이 끝나면, main 메서드를 실행하여 의도한 결과가 잘 출력되는지 확인합니다. new 키워드 등 아직 모르는 부분이 있다면 그냥 넘어가도 좋습니다. 이 실습의 목적은 클래스의 기본 문법과 구조에 익숙해지는 것입니다.
import java.util.Scanner;
public class SimpleCalculatorTest {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in); // 외부 입력을 받을 수 있는 Scanner 객체 생성
System.out.println("첫 번째 숫자를 입력하세요.");
String str1 = scan.nextLine(); // 첫 번째 숫자 입력
System.out.println("사칙연산자를 입력하세요.");
String op = scan.nextLine(); // 사칙연산자 입력
System.out.println("두 번째 숫자를 입력하세요.");
String str2 = scan.nextLine(); // 두 번째 숫자 입력
int num1 = Integer.parseInt(str1); // 입력받은 첫 번째 문자를 숫자형으로 변환
int num2 = Integer.parseInt(str2); // 입력받은 두 번째 문자를 숫자형으로 변환
int result;
if(op.equals("+")) { // 덧셈 연산
result = num1 + num2;
}
else if(op.equals("-")) { //뺄셈 연산
result = num1 - num2;
}
else if(op.equals("/")) { //나누기 연산
result = num1 / num2;
}
else{
result = num1 * num2; //곱하기 연산
}
System.out.println(str1 + " " + op + " " + str2 + " = " + result); // 결과값 출력
}
}객체(Object)
앞서 우리는 클래스가 개별 객체(인스턴스)를 만들기 위한 설계도이며, 클래스를 통해 만들어진 객체가 실제로 사용할 수 있는 실체임을 배웠습니다. 이제 객체에 대한 좀 더 자세한 내용을 알아보도록 하겠습니다.
앞서 클래스 챕터에서 간략하게 보았던 것처럼 객체는 크게 속성과 기능이라는 두 가지 구성요소로 이뤄져 있습니다.
속성과 기능은 각각 필드와 메서드로 정의되는데, 일반적으로 하나의 객체는 다양한 속성과 기능의 집합으로 이뤄져 있습니다. 그리고 이러한 속성과 기능은 이너클래스와 함께 객체의 **멤버(member)**라 부릅니다.
다음의 예시를 통해 좀 더 이해해 봅시다.

여기 아주 멋있는 빨간 차 한 대가 있습니다. 이 차를 잠시 하나의 객체로 생각해 보도록 하겠습니다.
이 자동차 객체와 관련한 속성과 기능을 정의한다면 어떻게 할 수 있을까요?
물론 자동차 한 대가 가지는 복잡한 구조와 여러 기능들을 생각해 볼 때 매우 많은 속성과 기능이 언급될 수 있겠지만, 편의상 내용을 단순화시켜서 몇 가지만 언급해 보겠습니다.
먼저 차가 가지는 일반적인 속성으로 차의 모델명, 바퀴의 개수, 문의 개수, 컬러 등을 언급할 수 있겠고, 그 기능으로는 시동 걸기, 가속하기, 감속하기, 정지하기 등의 기능을 생각해 볼 수 있을 것 같습니다.
이러한 차의 기본 속성과 기능들을 코드로 옮겨보면 다음의 이미지처럼 클래스의 필드와 메서드로 정의할 수 있습니다.

어떤가요?
코드를 확인해 보면, 앞서 언급한 자동차의 속성과 기능이 Car 클래스 안에 각각 필드와 메서드로 구현되어 있는 것을 확인할 수 있습니다. 이렇게 차와 관련된 데이터와 그 데이터를 다룰 수 있는 방법을 클래스라는 울타리에 모아 하나로 관리해 주니 좀 더 직관적이고 데이터 관리가 용이해졌습니다.
또한, 각 변수의 자료형은 각 속성값에 알맞은 것으로 정의되었습니다. 예를 들면, 차문의 개수를 의미하는 doors는 int 형으로, 컬러를 의미하는 color는 String 형으로 정의된 것을 확인할 수 있습니다.
이러한 방식은 우리가 실제 세계에서 사물을 바라보는 방식에 가장 가까운 방식의 개발 설계 방법론이라 할 수 있습니다. 지금은 하나의 클래스만을 보고 있지만, 만약 큰 규모의 프로젝트에서 수백 수천 줄의 데이터들을 관리해줘야 하는 상황이라면 그 효과와 편리함은 더욱 분명해집니다.
그렇다면 객체는 어떻게 생성할 수 있을까요?
객체의 생성은 다음과 같이 new 키워드를 사용하여 다음과 같이 실제 객체를 생성할 수 있습니다. 그리고 객체를 생성한 후에는 **포인트 연산자(.)**를 통해 해당 객체의 멤버에 접근이 가능합니다.
class CarTest {
public static void main(String[] args) {
Car bmw = new Car(); // Car 클래스를 기반으로 생성된 bmw 인스턴스
Car tesla = new Car(); // Car 클래스를 기반으로 생성된 tesla 인스턴스
Car audi = new Car(); // Car 클래스를 기반으로 생성된 audi 인스턴스
}자세한 내용은 다음 챕터에서 좀 더 자세히 알아보도록 하겠습니다.
객체의 생성
이번 챕터에서는 좀 더 구체적으로 객체를 어떻게 생성하고 활용할 수 있는지 알아보도록 하겠습니다.
먼저, 앞서 간략하게 살펴봤듯이 객체는 new 키워드로 생성할 수 있습니다.
경우에 따라 메서드를 사용해 객체를 생성할 수도 있지만 이 경우도 내부적인 작업을 통해 new 키워드를 통해 객체를 생성하는 것이기 때문에 결국에는 동일한 방식이라 할 수 있습니다.
객체는 다음과 같이 생성합니다.
클래스명 참조_변수명; // 인스턴스를 참조하기 위한 참조변수 선언
참조_변수명 = new 생성자(); // 인스턴스 생성 후, 객체의 주소를 참조 변수에 저장먼저 특정 클래스 타입의 참조변수를 선언합니다. 참조변수가 선언되면, 이제 new 키워드와 생성자를 통해 인스턴스를 생성하여 참조변수에 할당합니다.
여기서 참조 변수는 실제 데이터 값이 아니라 실제 데이터가 저장되어 있는 힙 메모리의 주소값을 가리킵니다. 좀 더 자세한 내용은 아래에서 살펴보도록 하겠습니다.
new 키워드는 생성된 객체를 힙 메모리에 넣으라는 의미를 가지고 있는데, 생성자(클래스와 동일한 이름을 가졌지만 뒤에 소괄호가 붙음)를 통해 객체가 만들어지면 해당 객체를 힙 메모리에 넣는 역할을 수행하게 됩니다.
이 과정을 간편하게 줄여서 다음처럼 선언할 수 있습니다.
클래스명 참조_변수명 = new 생성자();이제 객체의 생성과 관련해서 자바에서 매우 중요한 메모리의 개념을 포함해서 조금만 더 자세하게 풀어보겠습니다.
먼저 참조 변수는 앞서 설명한 대로 실제 데이터 값을 저장하는 것이 아니라 실제 데이터가 위치해 있는 힙 메모리의 주소를 저장하는 변수를 의미합니다.
따라서 우리가 new 키워드와 생성자를 통해 클래스의 객체를 생성한다는 것은 해당 객체를 힙 메모리에 넣고 그 주소값을 참조변수에 저장하는 것과 같습니다.
매우 중요한 부분이기 때문에 아래 그림을 통해서 좀 더 살펴보도록 하겠습니다.
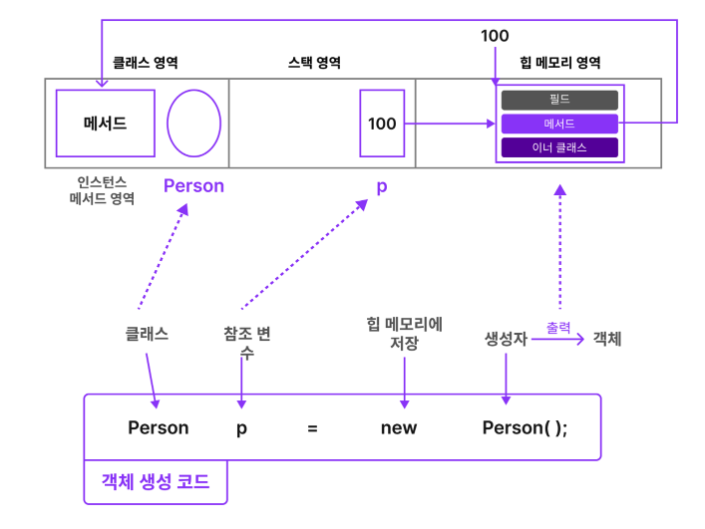
그림에서 볼 수 있는 것처럼 클래스 Person과 참조 변수 p는 각각 클래스 영역과 스택 영역이라는 다른 위치에 저장됩니다.
한편 생성자로 만들어진 인스턴스는 힙 메모리 영역에 들어가며 객체 내부에는 클래스의 멤버들이 위치하게 됩니다. 앞서 설명드린 대로, 참조변수는 객체의 실제 값이 아닌 힙에 저장되어 있는 주소값을 가리키게 됩니다.
여기서 또 한 가지 주목해야 하는 부분은 메서드의 구현 코드의 위치입니다. 보시는 것처럼 메서드 구현 코드는 클래스 영역에 저장되고 객체 안에서는 그 위치를 가리키고 있습니다.
즉 같은 클래스로 만든 모든 객체는 동일한 메서드 값을 공유하기 때문에 여러 번 같은 메서드를 선언해 주는 것이 아니라 한 번만 저장해 두고 필요한 경우에만 클래스 영역에 정의된 메서드를 찾아 사용할 수 있는 것입니다.
메모리와 관련된 부분은 조금 복잡한 부분이기 때문에, 지금 당장 이해가 어렵다면 넘어가셔도 좋습니다.
다만 생성된 객체에서 필드값은 실제 저장공간이 객체 내부에 있다는 것과 메서드는 다른 영역에 하나만 저장해 놓고 공유한다는 점만 기억합시다.
객체의 활용
이제 이렇게 생성된 객체를 활용해 봅시다. 어떻게 할 수 있을까요?
사실 객체에 접근하고 이를 사용할 수 있는 방법은 매우 간단합니다. 우리가 기억해야 할 가장 중요한 것은 .입니다. 포인트 연산자라고도 불리는데, 그 의미는 **‘해당 위치에 있는 객체 안을 보세요'**라는 뜻을 가지고 있습니다.
우리는 이 .을 활용하여 특정 인스턴스 객체의 필드와 메서드, 즉 객체의 멤버들에 접근할 수 있습니다.
기본적인 문법은 다음과 같습니다.
참조 변수명.필드명 // 필드값 불러오기
참조 변수명.메서드명() // 메서드 호출
위와 같은 방법을 통해서 우리는 특정 객체 안에 있는 필드 값 또는 메서드에 접근할 수 있습니다.
그러면 이제 이전과 같은 방식으로 src/main/java 아래 Car 클래스와 CarTest 클래스를 각각 생성하여 앞서 배웠던 내용들을 실습을 통해 좀 더 이해해 보도록 합시다.
앞의 학습과 마찬가지로, 반드시 하나씩 손으로 입력해 보면서 출력값이 바르게 출력되는지 확인해 주세요.
public class CarTest {
public static void main(String[] args) {
Car tesla = new Car("Model 3", "빨강"); // 객체 생성.
System.out.println("내 차의 모델은 " + tesla.model + "이고 " + "색은 " + tesla.color + "입니다."); // 필드 호출
tesla.power(); // 메서드 호출
tesla.accelerate();
tesla.stop();
}
}
class Car {
public String model; // 필드 선언
public String color;
public Car(String model, String color) { // 인스턴스 초기화를 위한 생성자 함수. 이후 챕터에서 학습 예정.
this.model = model;
this.color = color;
}
void power() { // 메서드 선언
System.out.println("시동을 걸었습니다.");
}
void accelerate() {
System.out.println("더 빠르게!");
}
void stop(){
System.out.println("멈춰!!");
}
}
// 출력값
내 차의 모델은 Model 3이고 색은 빨강입니다.
시동을 걸었습니다.
더 빠르게!
멈춰!!위의 예시에서, 먼저 model과 color의 속성을 가지며 power(), accelerate(), stop() 기능을 가지고 있는 Car 클래스를 정의했습니다.
그리고 CarTest 클래스 안에서 tesla 인스턴스를 만들어 앞서 정의한 속성과 기능을 println() 메서드를 통해 출력했습니다.
결과적으로 우리가 의도한 내용들이 순차적으로 출력되고 있음을 확인할 수 있습니다.
개발 역량을 기를 수 있는 가장 확실하고 빠른 방법은 많이 시도해 보고 실제로 코드를 반복적으로 작성하는 것입니다.
필드(Field)와 메서드(Method)
앞서 우리는 객체지향 프로그래밍의 가장 기본이 되는 클래스와 객체에 대해 학습했습니다. 그리고 각 객체의 속성과 기능을 정의하기 위해 필드와 메서드를 사용한다는 사실을 배웠습니다.
이번 챕터에서는 필드와 메서드에 대해 좀 더 자세하게 알아보도록 하겠습니다.
다음의 학습 목표를 통해 이번 챕터의 학습 내용을 먼저 확인해봅시다.
학습 목표
- 객체의 속성을 정의하는 필드를 이해하고, 세 가지 종류의 변수를 구분할 수 있다.
- 각각의 변수가 저장되는 위치를 설명하고, 그 차이를 설명할 수 있다.
- static 키워드가 무엇이며, 언제 사용되는지 설명할 수 있다.
- 객체의 기능을 정의하는 메서드를 이해하고, 메서드의 구성요소와 호출에 대해 설명할 수 있다.
- 메서드 오버로딩을 이해하고 그 장점을 설명할 수 있다.
필드(Field)
필드는 ‘클래스에 포함된 변수'를 의미하는 것으로 객체의 속성을 정의할 때 사용됩니다.
자바에서 변수는 크게 클래스 변수(cv, class variable), 인스턴스 변수(iv, instance variable), 그리고 **지역 변수(lv, local variable)**라는 세 가지로 구분될 수 있습니다.
이 중 우리가 필드라 부른 것은 클래스 변수와 인스턴스 변수이며, 이 둘은 다시 static 키워드의 유무로 구분할 수 있습니다.
좀 더 구체적으로, static 키워드가 함께 선언된 것은 클래스 변수, 그렇지 않은 것은 인스턴스 변수입니다. 그리고 이 두 가지 변수 유형에 포함되지 않고 메서드 내에 포함된 모든 변수를 지역변수라 부릅니다.
이 세 가지 유형의 변수들은 주로 선언된 위치에 따라 그 종류가 결정되며 각각 다른 유효 범위(scope)를 가지게 됩니다. 아래 예시를 통해 한번 살펴보겠습니다.
class Example { // => 클래스 영역
int instanceVariable; // 인스턴스 변수
static int classVariable; // 클래스 변수(static 변수, 공유변수)
void method() { // => 메서드 영역
int localVariable = 0; // 지역 변수. {}블록 안에서만 유효
}
}
위의 코드 예제에서 Example 클래스 안에 앞서 언급한 세 가지 유형의 변수가 선언되어 있습니다. 이 중에 instanceVariable과 classVariable은 클래스 영역에 선언되었기 때문에 멤버 변수입니다.
다시 static 키워드(이어지는 챕터에서 학습 예정)의 유무에 따라 classVariable 변수가 클래스 변수, 그리고 키워드가 있지 않은 instanceVariable 변수가 인스턴스 변수가 됩니다.
마지막으로 메서드 내부의 블록에 선언되어 있는 지역변수 localVariable 이 있습니다.
이처럼 변수는 주로 그 선언 위치와 static 키워드의 유무에 따라 구분할 수 있습니다. 이제 각각에 대해서 좀 더 자세히 살펴보겠습니다.
먼저 인스턴스 변수(iv)는 인스턴스가 가지는 각각의 고유한 속성을 저장하기 위한 변수로 new 생성자()를 통해 인스턴스가 생성될 때 만들어집니다.
클래스를 통해 만들어진 인스턴스는 힙 메모리의 독립적인 공간에 저장되고, 동일한 클래스로부터 생성되었지만 객체의 고유한 개별성을 가집니다.
마치 사람마다 성별, 이름, 나이, MBTI가 다 다르듯 인스턴스 변수는 그 고유한 특성을 정의하기 위한 용도로 사용됩니다.

다음으로, static 키워드를 통해 선언하는 클래스 변수(cv)가 있습니다. 클래스 변수는 독립적인 저장 공간을 가지는 인스턴스 변수와 다르게 공통된 저장공간을 공유합니다.
따라서 한 클래스로부터 생성되는 모든 인스턴스 이 특정한 값을 공유해야 하는 경우에 주로 static 키워드를 사용하여 클래스 변수를 선언하게 됩니다. 사람을 예로 들면 손가락과 발가락 개수와 같이 모든 사람이 공유하는 특성을 저장하는 데에 사용됩니다.
또한, 클래스 변수는 인스턴스 변수와 달리 인스턴스를 따로 생성하지 않고도 언제라도 클래스명.클래스변수명 을 통해 사용이 가능합니다. 위의 코드 예제로 예를 들면, Example.classVariable로 클래스 변수를 사용할 수 있습니다.
참고로, 이것은 앞서 봤었던 메모리 구조에서 메서드처럼, 클래스 변수 또한 클래스 영역에 저장되어 그 값을 공유하기 때문에 가능합니다.
마지막으로 앞서 설명한 두 가지의 멤버 변수와 구분되는 지역변수(lv)가 있습니다. 지역변수는 메서드 내에 선언되며 메서드 내({} 블록)에서만 사용가능한 변수입니다.
멤버 변수와는 다르게 지역변수는 스택 메모리에 저장되어 메서드가 종료되는 것과 동시에 함께 소멸되어 더 이상 사용할 수 없게 됩니다.
또한 힙 메모리에 저장되는 필드 변수는 객체가 없어지지 않는 한 절대로 삭제되는 않는 반면, 스택 메모리에 저장되는 지역변수는 한동안 사용되지 않는 경우 가상 머신에 의해 자동으로 삭제됩니다.

마지막으로 필드 변수와 지역 변수의 주요한 한 가지 차이점은 초기값에 있습니다.
직접 초기화하지 않으면 값을 출력할 때에 오류가 발생하는 지역변수와는 다르게 필드 변수는 직접적으로 초기화를 실행하지 않더라도 강제로 초기화가 이뤄집니다.
이것 또한 메모리의 저장 위치와 긴밀한 연관성을 가집니다. 힙 메모리에는 빈 공간이 저장될 수 없기 때문에 이곳에 저장되는 필드는 강제로 초기화되지만, 스택 메모리는 강제로 초기화되지 않으므로 지역 변수는 선언 시 반드시 초기화를 실행해주어야 합니다.
처음이라 조금 복잡하게 들릴 수 있지만, 이 세 가지 변수의 종류와 특성을 이해하는 것은 향후 클래스를 작성하고, 객체지향적 프로그래밍을 설계하는 데 매우 중요한 내용입니다. 각 변수 값이 저장되는 메모리의 위치와 연결 지어 각 변수의 특징을 잘 기억해두기를 바랍니다.
static 키워드
앞선 챕터에서 우리는 클래스 변수와 인스턴스 변수를 구분하기 위한 방법으로 static 키워드의 유무를 확인한다고 배웠습니다. 이번 챕터에서는 static 키워드에 대해서 좀 더 알아보겠습니다.
static은 클래스의 멤버(필드, 메서드, 이너 클래스)에 사용하는 키워드입니다.
static 키워드가 붙어있는 멤버를 우리는 **‘정적 멤버(static member)’**라고 부르고 static이 붙어있지 않은 인스턴스 변수와 구분합니다.
이 둘을 구분하는 가장 큰 차이는 인스턴스 멤버는 기존에 우리가 배웠던 내용처럼 반드시 객체를 생성한 이후에 변수와 메서드에 접근하여 해당 멤버를 사용가능한 반면, static 키워드로 정의되어 있는 클래스 멤버들은 인스턴스의 생성 없이도 클래스명.멤버명 만으로도 사용이 가능하다는 점입니다.
물론 정적 멤버도 객체를 생성한 이후 참조변수를 통해 사용이 가능하지만, 애초에 정적 멤버임을 표시하기 위해서 클래스명.멤버명 의 형태로 사용할 것을 권장하고 있습니다.
static 키워드를 사용하는 정적 멤버를 클래스명.멤버명 으로 사용할 수 있는 것 또한 앞에서 봤었던 메모리의 저장 위치와 관련이 있습니다. 앞서 확인했듯이 new 키워드를 통해 생성된 인스턴스는 힙 메모리에 생성되고 독립적인 저장공간을 가지게 됩니다.
반면 static 키워드로 선언된 정적 멤버는 클래스 내부에 저장 공간을 가지고 있기 때문에 객체 생성 없이 곧바로 사용할 수 있습니다.
정말 그런지 코드를 통해 직접 확인해 보겠습니다.
public class StaticTest {
public static void main(String[] args) {
StaticExample staticExample = new StaticExample();
System.out.println("인스턴스 변수: " + staticExample.num1); // static 키워드가 없는 인스턴스 변수
System.out.println("클래스 변수: " + StaticExample.num2); //static 키워드가 있는 클래스 변수
}
}
class StaticExample {
int num1 = 10;
static int num2 = -10;
}
//출력값
인스턴스 변수: 10
클래스 변수: -10위의 예시를 보면 static 키워드의 유무에 따라 달라지는 차이를 명확하게 확인해 볼 수 있습니다.
실험을 위해, 먼저 StaticExample 클래스에 static 키워드가 있는 변수 num2와 static 키워드가 없는 변수 num1에 각각 -10과 10을 할당했습니다. 그리고 StaticTest 클래스에서 각각의 필드 값을 호출했습니다.
다만 인스턴스 변수는 우리가 아는 일반적인 방법으로 객체 생성 후에 포인트 연산자를 사용하여 값을 불러왔고, 클래스 변수는 객체 생성 없이 클래스명을 사용하여 값을 불러왔습니다. 직접 인텔리제이를 사용하여 값이 정상적으로 호출되는지 확인해 봅시다.
여기서 우리가 기억해야 할 것이 두 가지가 있습니다.
먼저, 정적 필드는 객체 간 공유 변수의 성질이 있다는 점입니다. 이것은 메서드에도 동일하게 적용됩니다. 일반적인 메서드 앞에 static 키워드를 사용하면 해당 메서드는 정적 메서드가 됩니다. 정적 메서드도 정적 필드와 마찬가지로 클래스명만으로 바로 접근이 가능합니다.
둘째, 정적 메서드의 경우 인스턴스 변수 또는 인스턴스 메서드를 사용할 수 없다는 것입니다. 이 점은 잘 생각해 보면, 사실 너무 당연한 이야기입니다. 정적 메서드는 인스턴스 생성 없이 호출이 가능하기 때문에 정적 메서드가 호출되었을 때 인스턴스가 존재하지 않을 수 있기 때문입니다.
이제 정적 필드 간에 값 공유가 일어나는 것을 코드로 한번 살펴보겠습니다.
public class StaticFieldTest {
public static void main(String[] args) {
StaticField staticField1 = new StaticField(); // 객체 생성
StaticField staticField2 = new StaticField();
staticField1.num1 = 100;
staticField2.num1 = 1000;
System.out.println(staticField1.num1);
System.out.println(staticField2.num1);
staticField1.num2 = 150;
staticField2.num2 = 1500;
System.out.println(staticField1.num2);
System.out.println(staticField2.num2);
}
}
class StaticField {
int num1 = 10;
static int num2 = 15;
}
//출력값
100
1000
1500
1500보시는 것처럼 StaticField 클래스에 인스턴스 필드(num1)와 정적 필드(num2)를 각각 선언하고, 대조를 위해 staticField1와 staticField2 객체를 생성했습니다.
num1의 경우에는 각각의 변수가 고유성을 가지기 때문에 100과 1000으로 따로 출력되는 반면에, num2의 경우는 앞서 배웠던 것처럼 값 공유가 일어나 1500이 출력값으로 두 번 반복되고 있습니다.
이처럼 static 키워드를 사용하면 모든 인스턴스에 공통적으로 적용되는 값을 공유할 수 있습니다.
결론적으로 static 키워드는 클래스의 멤버 앞에 붙일 수 있습니다. 정적 멤버의 가장 큰 특징은 인스턴스를 따로 생성하지 않아도 클래스명만으로도 변수나 메서드 호출이 가능하다는 점이며, 이는 메모리의 저장위치와 관련이 있다는 사실을 알 수 있었습니다.
메서드(Method)
이제 필드와 더불어 클래스의 중요한 구성 요소인 메서드에 대한 내용을 살펴보도록 하겠습니다.
메서드는 **“특정 작업을 수행하는 일련의 명령문들의 집합"**을 의미하며, 앞서 본 것처럼 클래스의 기능에 해당하는 내용들을 담당합니다. 앞의 자동차의 예시에서 시동걸기, 가속하기, 정지 등이 메서드로 정의되었습니다.
메서드는 다시 크게 머리에 해당하는 **메서드 시그니처(method signature)**와 몸통에 해당하는 **메서드 바디(method body)**로 구분할 수 있습니다.
아래 코드 예시를 통해서 좀 더 자세히 알아보도록 하겠습니다.
자바제어자 반환타입 메서드명(매개 변수) { // 메서드 시그니처
메서드 내용 // 메서드 바디
}위의 예제는 메서드의 시그니처와 바디가 각각 어떻게 구성되어 하나의 메서드를 완성하는 지를 잘 보여주고 있습니다.
먼저 머리에 해당하는 메서드 시그니처를 살펴보면 자바 제어자, 반환타입, 메서드명, 그리고 매개 변수로 이뤄져 있다는 사실을 알 수 있습니다.
뒤에서 배우게 될 자바 제어자에 대한 부분을 잠시 생략하고 보면, 메서드의 시그니처는 순서대로 해당 메서드가 어떤 타입을 반환하는 가(반환 타입), 메서드 이름이 무엇(메서드명)이며 해당 작업을 수행하기 위해서 어떤 재료들이 필요한지(매개 변수)에 대한 정보를 포함하고 있습니다.
다음으로 메서드의 바디는 괄호({}) 안에 해당 메서드가 호출되었을 때 수행되어야 하는 일련의 작업들을 표시하게 됩니다. 참고로 메서드명은 관례적으로 소문자로 표시합니다.
public static int add(int x, int y) { // 메서드 시그니처
int result = x + y; // 메서드 바디
return result;
}위의 예시는 앞서 봤었던 내용이 어떻게 실제 코딩에 적용될 수 있는지 잘 보여주고 있습니다.
이후 학습하게 될 public 접근 제어자를 생략하고 잠시 설명해 보자면, 메서드명이 add 인 메서드이며 int 타입 2개의 값(x와 y)을 받아 더한 다음 int 타입의 결과값을 반환하는 메서드라 정리할 수 있습니다.
만약 메서드의 반환타입이 void가 아닌 경우에는 메서드 바디({}) 안에 반드시 return 문이 존재해야 합니다. 리턴문은 작업을 수행한 결과값을 호출한 메서드로 전달합니다. 여기서 결과값은 반드시 반환타입과 일치하거나 적어도 자동 형변환이 가능한 것이어야 합니다.
다른 예시들도 한번 볼까요?
void printHello() { // 반환타입이 void인 메서드
System.out.println("hello!");
}이 예시의 printHello 메서드는 반환 타입이 void, 즉 반환 값이 없는 메서드를 의미합니다. 따라서 printHello 메서드는 호출되면 그저 hello!라는 내용을 출력하고 종료됩니다.
int getNumSeven() { // 매개변수가 없는 메서드
return 7;
}
getNumSeven 메서드는 int 타입의 결과값을 반환하는 매개변수가 없는 메서드입니다. 해당 메서드가 호출되면 그냥 숫자 7을 반환하면 되기 때문에 따로 매개변수가 필요하지 않습니다.
Double multiply(int x, double y) { // 매개변수가 있는 메서드
double result = x * y;
return result;
}
multiply 메서드는 매개변수 x와 y를 전달받아 반환 타입이 double인 result를 반환하는 매개변수가 있는 메서드입니다(앞서 자바 기초 유닛에서 배웠던 것처럼 int와 double형을 산술 연산하면 범위가 더 큰 타입으로 자동으로 형 변환이 이루어집니다.).
이제 조금 익숙해졌나요?
메서드는 모든 프로그래밍의 가장 기본이 되는 핵심 중에 하나이기 때문에 실제로 많이 사용해 보시면서 최대한 익숙해지는 것을 권장합니다.
메서드의 호출
메서드를 아무리 잘 정의하더라도 실제로 호출되지 않으면 너무 당연하게도 아무 일도 일어나지 않습니다.
메서드도 클래스의 멤버이므로 클래스 외부에서 메서드를 사용하기 위해서는 먼저 인스턴스를 생성해야 합니다. 인스턴스를 생성한 후에 앞서 보았던 것처럼 포인트 연산자(.)를 통해 메서드를 호출할 수 있습니다.
반면, 클래스 내부에 있는 메서드끼리는 따로 객체를 생성하지 않고도 서로를 호출할 수 있습니다.
메서드를 호출하는 기본적인 방법은 다음과 같습니다.
메서드이름(매개변수1, 매개변수2, ...); // 메서드 호출방법. 매개 변수가 없을 수도 있음.
printHello(); // 위의 코드 예제 호출
getNumSeven();
multiply(4, 4.0);
//출력값
hello!
7
16.0위의 코드 예제는 앞서 살펴본 메서드들을 호출한 경우를 보여줍니다. 각각 리턴 타입에 맞는 결과값을 바르게 반환하고 있습니다.
메서드 호출 시 괄호() 안에 넣어주는 입력 값을 우리는 **‘인자(argument)’**라고 하는데, 인자의 개수와 순서는 반드시 메서드를 정의할 때 선언된 매개변수와 일치되어야 합니다. 그렇지 않은 경우 실행 에러가 발생합니다. 인자의 타입 또한 매개변수의 그것과 일치하거나 자동 형변환이 가능한 것이어야 합니다.
메서드 오버로딩(Method Overloading)
메서드 오버로딩이란 하나의 클래스 안에 같은 이름의 메서드를 여러 개 정의하는 것을 의미합니다. 영어로 “overload”의 사전적 의미가 ‘과적하다/ 부담을 지우다’라는 점을 생각해 보면 좀 더 이해하기 쉽습니다.
보통 하나의 메서드에 하나의 기능만을 구현해야 하는데, 같은 이름의 메서드를 여러 기능을 구현하기 때문에 오버로딩이란 용어를 사용한 것이라 생각해 볼 수 있습니다.

메서드 오버로딩을 제대로 이해하기 위해서는 먼저 **메서드 시그니처(method signature)**에 대한 개념 이해가 먼저 선행되어야 합니다.
앞서 봤듯이, 메서드 시그니처는 메서드명과 매개변수의 타입을 의미하는데 “서명"을 의미하는 시그니처라는 단어에서도 유추할 수 있듯이 각 메서드를 구분하는 용도로 사용합니다.
이것은 메서드의 이름 또는 매개변수의 타입이 다르면 다른 메서드라고 인식하는 자바 가상머신의 기능과 관계가 있습니다.
public class Overloading {
public static void main(String[] args) {
Shape s = new Shape(); // 객체 생성
s.area(); // 메서드 호출
s.area(5);
s.area(10,10);
s.area(6.0, 12.0);
}
}
class Shape {
public void area() { // 메서드 오버로딩. 같은 이름의 메서드 4개.
System.out.println("넓이");
}
public void area(int r) {
System.out.println("원 넓이 = " + 3.14 * r * r);
}
public void area(int w, int l) {
System.out.println("직사각형 넓이 = " + w * l);
}
public void area(double b, double h) {
System.out.println("삼각형 넓이 = " + 0.5 * b * h);
}
}
//출력값
넓이
원 넓이 = 78.5
직사각형 넓이 = 100
삼각형 넓이 = 36.0위의 예시를 보면, Shape 클래스 안에 있는 모든 메서드들이 area()라는 메서드명을 가지고 있음에도 불구하고 각기 다른 출력값을 리턴하는 것을 확인하실 수 있습니다.
여기서 한 가지 꼭 기억해야 하는 점은 무조건 같은 메서드명을 사용한다고 해서 오버로딩이 되는 것이 아니라는 것입니다.
오버로딩이 성립하기 위해서는 크게 두 가지 조건이 성립되어야 합니다.
먼저, 앞서 봤었던 것처럼 같은 이름의 메서드명을 써줘야 하고, 매개변수의 개수나 타입이 다르게 정의되어야 합니다. 만약 이 조건이 하나라도 충족이 되지 않는다면 중복 정의로 간주되어 컴파일 에러가 발생하게 됩니다.
위의 예시를 확인해 보면 이 두 가지 조건이 모두 충족되어 문제없이 출력값을 리턴하고 있는 것을 확인하실 수 있습니다. 참고로 반환 타입은 오버로딩이 성립하는 데에 영향을 주지 못합니다.
다른 말로 표현하면, 다른 반환 타입을 지정했다고 해서 가상 머신은 다른 메서드라 인식하지 못합니다.
오버로딩의 조건을 정리하면 다음과 같습니다.
- 메서드를 오버로딩하려면
- 메서드의 이름이 같아야 합니다.
- 매개변수의 개수 또는 타입이 달라야 합니다.
그렇다면 오버로딩의 장점은 무엇일까요?
가장 큰 장점은 하나의 메서드로 여러 경우의 수를 해결할 수 있다는 것입니다.
오버로딩의 대표적인 예시로 println() 메서드가 있습니다. 지금까지 우리가 println() 메서드를 사용했을 때 아무 값이나 괄호() 안에 인자로 넣어서 사용하는데 문제가 없었지만, 사실 그 내부를 살펴보면 매개변수의 타입에 따라서 호출되는 println 메서드가 달라진다는 사실을 알 수 있습니다.
만약에 오버로딩이 지원되지 않았다면, 하나하나 일일이 메서드를 정의해줘야 하는 번거로움이 발생했을 것입니다. 오버로딩을 통해서 같은 기능을 하는 메서드의 이름을 계속 반복적으로 지어주지 않아도 되고, 이름만 보고도 기능을 쉽게 예측할 수 있습니다.
오버로딩에 대한 부분은 다음 유닛의 객체지향 프로그래밍의 심화에서 학습하게 될 다형성과도 긴밀한 관련이 있습니다.
오버로딩 활용
가변인자 사용
package MethodOverloadingExample;
public class MethodOverloadingExampleV2 {
public int add(int a, int b) {
return a + b;
}
// 세 정수의 합을 계산하는 메서드
public int add(int a, int b, int c) {
return a + b + c;
}
// 가변 인자(Variable Arguments) 사용
public int add(int ...numbers) {
int sum = 0;
for(int number: numbers) {
sum += number;
}
return sum;
}
public static void main(String[] args) {
MethodOverloadingExampleV2 methodOverloadingExampleV2 = new MethodOverloadingExampleV2();
System.out.println(methodOverloadingExampleV2.add(1, 2));
System.out.println(methodOverloadingExampleV2.add(1, 2, 3, 4, 5, 6));
}
}생성자(Constructor)
이제 클래스의 내부 구성요소 중 또 다른 중요한 역할을 담당하고 있는 생성자에 대해서 알아보겠습니다.
다음의 학습 목표를 통해 이번 챕터의 학습 내용을 먼저 확인해 봅시다.
학습 목표
- 생성자의 핵심 개념과 기본 문법을 이해하고 사용할 수 있다.
- 생성자가 메서드와 구분되는 두 가지 차이를 이해하고 설명할 수 있다.
- 메서드 오버로딩이 생성자에서 어떻게 구현될 수 있는지 확인하고 이해할 수 있다.
- 기본 생성자와 매개변수가 있는 생성자의 차이를 설명할 수 있다.
- this와 this()의 차이에 대해 설명할 수 있다.
생성자(Constructor)
생성자는 말 그대로 객체를 생성하는 역할을 하는 클래스의 구성 요소로서, 인스턴스가 생성될 때 호출되는 인스턴스 초기화 메서드라 정리할 수 있습니다.
앞서 우리가 new 키워드를 사용하여 객체를 생성할 때에 호출되는 것이 사실 바로 이 생성자입니다. 그럼 이제 좀 더 자세하게 생성자에 대해서 알아보도록 하겠습니다.
종종 생성자라는 이름에서 생성자가 인스턴스를 생성하는 역할을 한다는 오해가 발생하는데, 이것은 사실이 아닙니다. 인스턴스 생성을 담당하는 것은 new 키워드이며, 생성자는 인스턴스 변수들을 초기화하는 데 사용되는 특수한 메서드라 할 수 있습니다.
생성자는 메서드와 비슷한 구조를 가지고 있지만 크게 두 가지 부분에서 큰 차이를 가집니다.
첫 번째는 생성자의 이름은 반드시 클래스의 이름과 같아야 합니다. 만약 클래스 이름과 생성자의 이름이 다르다면 그 메서드는 더 이상 생성자로서의 기능을 수행할 수 없습니다.
두 번째로, 생성자는 리턴 타입이 없습니다. 하지만 메서드에서 리턴 값이 없을 때 표시하는 void 키워드를 사용하지 않습니다. 그 이유는 무언가를 ‘리턴하지 않는다’를 의미하는 void와는 다르게 생성자는 아예 리턴 타입 자체가 존재하지 않기 때문입니다.
이 두 가지 특징을 기억하면서 아래 예시를 한번 살펴봅시다.
클래스명(매개변수) { // 생성자 기본 구조
...생략...
}
먼저 클래스명과 같은 이름의 생성자명을 작성해 주고 리턴 타입이 없기 때문에 리턴 타입에는 아무것도 적지 않습니다. 매개변수는 있을 수도 있고 없을 수도 있습니다.
한 가지 기억해야 하는 사실은 생성자도 앞서 학습했던 오버로딩이 가능하므로 한 클래스 내에 여러 개의 생성자가 존재할 수 있다는 점입니다.
public class ConstructorExample {
public static void main(String[] args) {
Constructor constructor1 = new Constructor();
Constructor constructor2 = new Constructor("Hello World");
Constructor constructor3 = new Constructor(5,10);
}
}
class Constructor {
Constructor() { // (1) 생성자 오버로딩
System.out.println("1번 생성자");
}
Constructor(String str) { // (2)
System.out.println("2번 생성자");
}
Constructor(int a, int b) { // (3)
System.out.println("3번 생성자");
}
}위의 예시에서 확인할 수 있듯이, 오버로딩을 활용하여 같은 이름을 가진 생성자 여러 개를 만들 수 있습니다.
여기서, 생성자의 모양에 따라서 객체를 생성하는 방법이 결정됩니다. 예를 들면, (2) 번 생성자를 호출하기 위해서는 객체 생성 시에 문자열을 전달해주어야 하고, (3) 번 생성자를 위해서는 두 개의 int형 매개변수를 전달해주어야 합니다.
이제 앞서 봤었던 Car 클래스를 다시 한번 살펴볼까요?
class Car {
public String model;
public String color;
public Car(){} // 기본생성자. 생성자가 없는 경우 자동 생성
// 생성자 오버로딩
public Car(String model, String color) { // 매개변수가 있는 생성자
this.model = model;
this.color = color;
}
void power() {
System.out.println("시동을 걸었습니다.");
}
void accelerate() {
System.out.println("더 빠르게!");
}
void stop(){
System.out.println("멈춤");
}
}
//Output
내 차의 모델은 Model 3이고 색은 빨강입니다.
시동을 걸었습니다.
더 빠르게!
멈춤앞선 챕터에서는 생성자에 대한 내용을 아직 배우지 않았기 때문에 생략하고 지나갔었는데, 이제 다시 보니 어떤가요?
확인하실 수 있는 것처럼, Car 클래스에는 두 개의 생성자가 정의되어 있습니다. 하나는 매개변수가 없는 기본 생성자이며, 다른 하나는 model과 color라는 두 가지의 매개변수를 받고 있는 생성자입니다.
이렇게 두 개 이상의 생성자를 정의할 수 있는 이유는 자바가 오버로딩을 지원하기 때문이라고 앞서 설명했습니다.
눈으로 이해하는데 그치지 말고 반드시 인텔리제이에 하나씩 입력해 보면서 이해해 보길 바랍니다.
기본 생성자(Default Constructor)
지금까지 우리는 생성자의 존재를 모르고 그저 new 키워드를 사용하여 생성자를 호출하여 객체를 만들었지만, 사실 모든 클래스에는 반드시 하나 이상의 생성자가 존재해야 합니다.
사실 지금까지 생성자를 따로 만들지 않아도 정상적으로 인스턴스를 만들 수 있었던 이유는 만약 생성자가 클래스 안에 포함되어 있지 않은 경우에는 자바 컴파일러가 기본 생성자를 자동으로 추가해 줬기 때문입니다.
이 기본 생성자는 앞선 챕터에서도 우리가 봤듯이 매개변수가 없는 생성자를 의미합니다.
클래스명(){} //기본 생성자
DefaultConst(){} // 예시) DefaultConst 클래스의 기본 생성자위의 예시에서 보실 수 있는 것처럼 컴파일러가 자동으로 추가해 주는 기본 생성자에는 매개변수도 없고 바디에 아무런 내용이 없습니다. 그렇다면 만약에 생성자가 이미 추가되어 있는 경우는 어떻게 될까요?
이 경우에는 기본생성자가 아니라 이미 추가되어 있는 생성자를 기본으로 사용하게 됩니다.
매개변수가 있는 생성자
그럼 매개변수가 있는 생성자의 경우도 간략하게 한번 살펴보겠습니다. 매개변수가 있는 생성자는 메서드처럼 매개변수를 통해 호출 시에 해당 값을 받아 인스턴스를 초기화하는 데 사용됩니다.
고유한 특성을 가진 인스턴스를 계속 만들어야 하는 경우 인스턴스마다 각기 다른 값을 가지고 초기화할 수 있어서 매우 유용합니다. 간단한 예시를 통해서 확인해 보겠습니다.
public class ConstructorExample {
public static void main(String[] args) {
Car c = new Car("Model X", "빨간색", 250);
System.out.println("제 차는 " + c.getModelName() + "이고, 컬러는 " + c.getColor() + "입니다.");
}
}
class Car {
private String modelName;
private String color;
private int maxSpeed;
public Car(String modelName, String color, int maxSpeed) {
this.modelName = modelName;
this.color = color;
this.maxSpeed = maxSpeed;
}
public String getModelName() {
return modelName;
}
public String getColor() {
return color;
}
}
//Output
제 차는 Model X이고, 컬러는 빨간색입니다.위의 예시를 보시면 Car 인스턴스를 생성 시 매개변수가 있는 생성자를 사용하게 되면 인스턴스를 만든 후에 인스턴스의 필드값을 일일이 설정해 줄 필요 없이 생성과 동시에 원하는 값으로 설정해 줄 수 있어서 굉장히 편리합니다.
또한, 보시는 것처럼 생성자의 모양에 따라서 객체를 생성하는 방법도 달라지게 됩니다. 앞의 기본 생성자의 경우에는 매개변수가 없었기 때문에 원래 우리가 객체를 생성하던 방식으로 new 키워드와 생성자를 호출하면 되었지만, 매개변수가 있는 경우에는 그 개수와 타입에 알맞게 생성자를 호출해주어야 합니다.
이렇듯 생성자의 특징을 잘 이해하면 보다 간결하고 직관적인 코드 작성이 가능합니다.
this()
앞서 메서드의 호출 내용에서 같은 클래스 안에 메서드들끼리 서로 호출할 수 있었던 것처럼 생성자도 상호 호출이 가능합니다. 그리고 이를 위해 사용하는 것이 바로 this() 메서드입니다.
한마디로 this() 메서드는 자신이 속한 클래스에서 다른 생성자를 호출하는 경우에 사용합니다. 예를 들면 만약 클래스명이 Car라는 Car 클래스의 생성자를 호출하는 것은 Car()가 아니라 this()이고, 그 효과는 Car() 생성자를 호출하는 것과 동일합니다.
this() 메서드를 사용하기 위해서는 크게 두 가지의 문법요소를 충족시켜야 합니다.
- 첫째, this() 메서드는 반드시 생성자의 내부에서만 사용할 수 있습니다.
- 둘째, this() 메서드는 반드시 생성자의 첫 줄에 위치해야 합니다.
이 두 가지 조건을 유념하면서 다음의 예시를 한번 살펴봅시다.
public class Test {
public static void main(String[] args) {
Example example = new Example();
Example example2 = new Example(5);
}
}
class Example {
public Example() {
System.out.println("Example의 기본 생성자 호출!");
};
public Example(int x) {
this();
System.out.println("Example의 두 번째 생성자 호출!");
}
}
//Output
Example의 기본 생성자 호출!
Example의 기본 생성자 호출!
Example의 두 번째 생성자 호출!전반적인 실행 흐름을 위주로 한번 살펴봅시다. Example 클래스는 두 개의 생성자를 가지고 있습니다. 하나는 매개변수가 필요하지 않은 기본 생성자이고, 다른 하나는 int 타입의 매개변수를 받고 있는 생성자입니다.
그리고 두 번째 생성자 내부의 첫 번째 줄에 this() 메서드가 포함되어 있습니다.
이제 Example 클래스를 기반으로 만들어지는 인스턴스를 생성하면, 첫 번째 생성자가 호출되고 그 결과로 Example의 기본 생성자 호출!이라는 문구가 출력됩니다.
다음으로 두 번째 생성자를 사용하여 객체를 만드는 과정에서 생성자가 호출되면 먼저 this() 메서드가 출력되어 다시 첫 번째 기본생성자가 호출되고, 그다음으로 Example의 두 번째 생성자 호출!이라는 문구가 출력됩니다.
this 키워드
이제 앞서 배운 this() 메서드와 매우 유사한 생김새를 가지고 있지만 쓰임새는 전혀 다른 this 키워드에 대해서 알아보도록 하겠습니다. this 키워드를 이해하기 위해서 먼저 앞서 매개변수가 있는 생성자 챕터에서 봤었던 예제를 한번 다시 살펴보도록 하겠습니다.
public class ConstructorExample {
public static void main(String[] args) {
Car car = new Car("Model X", "빨간색", 250);
System.out.println("제 차는 " + car.getModelName() + "이고, 컬러는 " + car.getColor() + "입니다.");
}
}
class Car {
private String modelName;
private String color;
private int maxSpeed;
public Car(String modelName, String color, int maxSpeed) {
this.modelName = modelName;
this.color = color;
this.maxSpeed = maxSpeed;
}
public String getModelName() {
return modelName;
}
public String getColor() {
return color;
}
}
//Output
제 차는 Model X이고, 컬러는 빨간색입니다.위의 예제에서 Car 클래스를 한번 살펴볼까요?
인스턴스 변수로 modelName, color, 그리고 maxSpeed가 선언되어 있는데, 동시에 생성자의 매개변수로 modelName, color, maxSpeed가 정의되어 있습니다.
이런 경우, 인스턴스 변수와 매개변수를 이름만으로는 구분하기가 어려워지는 문제가 발생하게 되는데, 이를 구분해 주기 위한 용도로 주로 사용되는 방법이 바로 this 키워드라 할 수 있습니다.
만약에 위의 코드에서, this.modelName = modelName대신 modelName = modelName라고 작성하면 둘 다 지역변수로 간주되게 됩니다.
this 키워드에 대해 좀 더 구체적으로 설명해 보면, 모든 메서드에는 자신이 포함된 클래스의 객체를 가리키는 this라는 참조변수가 있는데, 일반적인 경우에는 컴파일러가 this. 를 추가해 주기 때문에 생략하는 경우가 많습니다.
예를 들면, 현재 Car 클래스의 modelName이라는 인스턴스 필드를 클래스 내부에 출력하고자 한다면 원래는 System.out.println(this.modelName) 이런 방식으로 작성해주어야 합니다.
결론적으로 this는 인스턴스 자신을 가리키며, 우리가 참조변수를 통해 인스턴스의 멤버에 접근할 수 있는 것처럼 this를 통해서 인스턴스 자신의 변수에 접근할 수 있는 것입니다.
그리고 위의 예시에서 봤던 것처럼, this 키워드는 주로 인스턴스의 필드명과 지역변수를 구분하기 위한 용도로 사용됩니다.
애초에 이름이 서로 달랐다면 구분이 필요 없었겠지만, 자바 프로그래밍에서 많은 경우 메서드의 지역 변수명이 필드명과 동일하게 구성되어 있기 때문에 이 형식에 꼭 익숙해지기를 권장합니다.