
스택(Stack)
스택의 개념과 특징

Stack의 정의
스택은 쌓다, 누적하다라는 의미를 가지고 있습니다. 마치 접시를 쌓아 놓은 것처럼 데이터(data)를 순서대로 쌓는 자료 구조입니다. 일상생활에서 스택과 유사한 예를 들어보겠습니다:
다섯 대의 자동차가 좁은 골목길을 순서대로 지나가고 있습니다. 이 골목길은 한 방향으로만 통행이 가능하며, 골목의 끝은 막혀 있습니다. 첫 번째 자동차가 골목길에 진입하고, 그 뒤를 이어 나머지 자동차들도 순서대로 진입합니다. 그러나 첫 번째 차량이 막다른 길을 만나게 되면, 마지막으로 들어온 다섯 번째 자동차부터 차례대로 후진하여 골목길을 빠져나가야 합니다.
Stack의 구조
위의 예시에서 골목길을 스택에 비유하고, 자동차를 데이터에 비유할 수 있습니다.

이 예시에서 볼 수 있듯이, 가장 먼저 들어간 자동차는 가장 나중에 나올 수 있습니다. 반대로 말하면, 가장 나중에 들어간 자동차가 가장 먼저 나올 수 있습니다.
- 스택의 특징은 입력과 출력이 하나의 방향으로 이루어지는 제한적 접근에 있습니다.
- 이런 정책을 LIFO(Last In First Out) 혹은 FILO(First In Last Out)이라고 부르기도 합니다.
- 스택에 데이터를 넣는 것을 '푸시(PUSH)', 데이터를 꺼내는 것을 '팝(POP)'이라고 합니다.
Stack의 특징
1. LIFO(Last In First Out)
스택은 마지막으로 삽입된 요소가 가장 먼저 삭제되는 원칙을 따릅니다. 즉, 가장 최근에 추가된 요소가 먼저 제거됩니다.
2. 제한적으로 데이터를 다뤄야 합니다.
가장 마지막에 삽입된 요소에만 접근할 수 있으며, 다른 요소에 직접 접근할 수 없습니다. 이러한 제한된 접근은 스택에 저장된 데이터의 안전성과 무결성을 보장합니다.
3. 하나의 입출력 장소를 가지고 있습니다.
스택은 데이터의 입출력 장소가 같습니다. 만약, 입출력 장소가 여러 개라면 스택이라고 볼 수 없습니다.
Stack 자료 구조의 장점
1. 스택은 후입선출(LIFO) 구조를 가지기 때문에, 스택에 저장된 데이터를 가져오는 속도가 매우 빠릅니다.
스택은 후입선출(LIFO) 구조를 가지기 때문에, 삽입과 삭제가 항상 스택의 맨 위에서 이루어집니다. 따라서 스택에서 데이터를 삽입하거나 삭제할 때, 다른 데이터의 위치를 변경할 필요가 없습니다. 예를 들어, 스택에서 삽입 연산을 수행하면, 새로운 데이터는 스택의 맨 위에 추가됩니다. 스택의 다른 데이터들은 그대로 놔둔 채로 새로운 데이터가 맨 위에 추가됩니다. 이와 마찬가지로 스택에서 삭제 연산을 수행하면, 맨 위에 있는 데이터가 삭제되고, 다른 데이터의 위치는 변경되지 않습니다. 이 과정은 스택의 크기와는 상관없이 항상 매우 빠르게 처리됩니다. 데이터를 삽입, 삭제하는데 모든 데이터를 순회할 필요가 없기 때문입니다.
Stack 자료 구조의 단점
1. 크기 제한이 없다.
스택은 데이터를 저장할 때 크기가 제한되지 않기 때문에, 메모리 사용량이 불필요하게 증가할 수 있습니다. 이러한 문제를 해결하기 위해서는 스택의 크기를 미리 정해놓거나, 동적으로 크기를 조절하는 방법을 사용해야 합니다.
2. 중간 요소에 접근이 제한된다.
스택은 상단(top) 요소에만 직접적인 접근이 가능하며, 중간에 있는 요소에 직접적인 접근은 불가능합니다. 중간 요소에 접근하려면 상단 요소를 Pop하여 원하는 요소에 도달해야 합니다.
Stack의 활용
스택은 다양한 분야에서 활용됩니다. 몇 가지 예를 들어보겠습니다:
- 컴퓨터 내부의 프로세스 구조: 컴퓨터의 프로세스 실행 구조는 스택을 이용합니다. 각 프로세스는 프로세스 스택을 가지고 있고, 이 스택에는 실행에 필요한 지역 변수나 반환 주소 등이 저장됩니다. 함수 호출 시 반환 주소를 스택에 push하고, 반환 시에는 스택에서 pop하여 이 주소로 돌아갑니다.
- 프로그래밍 언어의 메모리 관리: 대부분의 프로그래밍 언어는 메모리를 관리하기 위해 스택을 사용합니다. 예를 들어, C++에서는 스택 메모리 영역에 지역 변수를 저장하고, 함수가 종료될 때 이 변수를 자동으로 제거합니다.
- 문자열 역순 출력: 문자열을 스택에 push하고, 모든 문자를 pop하면 문자열이 역순으로 출력됩니다.
- 실시간 인터프리터: 실시간 인터프리터는 입력을 스택에 저장하고, 연산자가 나타나면 스택에서 피연산자를 pop하여 연산을 수행합니다.
- 문자열 괄호 검사: 문자열 내의 괄호가 올바르게 닫혔는지 검사하는 데 스택을 사용할 수 있습니다. 여는 괄호를 만날 때마다 스택에 push하고, 닫는 괄호를 만날 때마다 스택에서 pop하여 괄호를 매칭시킵니다.
- 웹 브라우저 방문 기록: 웹 브라우저의 '뒤로 가기'와 ‘앞으로 가기’ 기능은 스택을 사용합니다. 브라우저 예시를 좀 더 자세히 살펴 보겠습니다. 이 기능을 이해하기 위해서는 두 개의 스택이 사용된다는 것을 알아야 합니다. 하나는 방문한 페이지의 이력을 저장하는 '뒤로 가기' 스택(Prev Stack), 다른 하나는 '뒤로 가기'를 한 후에 '앞으로 가기'를 할 수 있도록 정보를 저장하는 '앞으로 가기' 스택(Next Stack)입니다.
Stack의 기본 연산
stack은 선형 자료구조로, 일렬로 나열된 요소들의 집합입니다. 이 요소들은 stack의 상단(top)을 기준으로 쌓이며, 스택의 맨 아래에 위치한 요소는 stack의 바닥(bottom)이라고 합니다.
push(삽입) 연산
- push 연산은 stack에 새로운 요소를 추가하는 작업입니다.
- 새로운 요소는 stack의 상단(top)에 삽입됩니다.
- stack이 비어있을 경우, 첫 번째 요소는 바닥(bottom)이자 상단(top)이 됩니다.
pop(삭제) 연산
- pop 연산은 상단에 위치한 요소를 제거하고 반환하는 작업입니다.
- 가장 최근에 추가된 요소가 가장 먼저 제거됩니다.
- pop 연산을 수행하면 상단 요소는 제거되며, 그 아래에 위치한 요소가 새로운 상단(top)이 됩니다.
peek 또는 top 연산
- peek 연산은 상단에 위치한 요소를 반환하는 작업입니다.
- peek 연산을 수행하더라도 요소가 제거되지 않습니다.
- peek 연산을 통해 상단에 위치한 요소를 확인할 수 있습니다.
isEmpty 연산
- isEmpty 연산은 stack이 비어있는지 확인하는 작업입니다.
- stack이 비어있을 경우 true를 반환하고, 비어있지 않을 경우 false를 반환합니다.
이러한 기본 연산들을 통해 스택은 그 특성에 따라 다양한 문제 해결에 활용될 수 있습니다. 이해를 돕기 위해 간단한 스택 구현 방법을 살펴보겠습니다.
스택의 구현 방법
Stack의 구현 방법
필요한 변수와 데이터 구조를 정의합니다:
- stack을 구현하기 위해 배열 또는 연결 리스트를 사용할 수 있습니다. 이 예시에서는 배열을 사용하여 stack을 구현하는 방법을 설명하겠습니다.
- 배열로 사용할 정적 배열 또는 동적 배열을 선언합니다. 스택의 최대 크기를 고려하여 배열의 크기를 결정합니다.
- 상단(top) 요소를 추적하기 위한 변수 top을 선언합니다. stack 선언 시 stack이 비어있으므로 이 변수의 초기값은 -1로 설정합니다.
push(삽입) 연산 구현
- push 연산은 새로운 요소를 stack에 추가하는 작업입니다.
- 삽입할 요소를 매개변수로 받아옵니다.
- top 변수를 1 증가시켜 다음 상단(top) 위치로 이동합니다.
- 배열의 top 위치에 요소를 삽입합니다.
pop(삭제) 연산 구현
- pop 연산은 stack에서 상단에 위치한 요소를 제거하고 반환하는 작업입니다.
- 반환할 요소를 임시 변수에 저장합니다.
- 배열의 top 위치에 있는 요소를 반환하기 전에 top 변수를 1 감소시킵니다.
- 임시 변수(반환할 요소)를 반환합니다.
peek(Top) 연산 구현
- peek 연산은 상단에 위치한 요소를 반환하는 작업입니다.
- 배열의 top 위치에 있는 요소를 반환합니다.
isEmpty 연산 구현
- isEmpty 연산은 stack이 비어있는지 확인하는 작업입니다.
- top 변수의 값이 -1인 경우 스택은 비어있는 상태입니다.
필요한 경우 예외 처리를 추가합니다
- stack이 가득 차 있는 상태에서 push 연산을 수행하려는 경우 "스택 오버플로우(Stack Overflow)" 예외를 처리합니다.
- stack이 비어있는 상태에서 pop 연산을 수행하려는 경우 "스택 언더플로우(Stack Underflow)" 예외를 처리합니다.
코드로 구현하는 Stack
public class ArrayStack {
private int maxSize;// 스택의 최대 크기private int top;// 스택의 상단을 가리키는 인덱스private int[] stackArray;// 스택을 저장하는 배열// 스택 생성자public ArrayStack(int size) {
maxSize = size;
stackArray = new int[maxSize];
top = -1;// 초기에 스택이 비어있으므로 top을 -1로 설정
}
// 스택이 비어있는지 확인public boolean isEmpty() {
return (top == -1);
}
// 스택이 가득 찼는지 확인public boolean isFull() {
return (top == maxSize - 1);
}
// 스택에 데이터 추가public void push(int data) {
if (isFull()) {
System.out.println("스택이 가득 찼습니다. 데이터를 추가할 수 없습니다.");
return;
}
stackArray[++top] = data;
}
// 스택의 상단 데이터 반환public int peek() {
if (isEmpty()) {
System.out.println("스택이 비어있습니다. 데이터를 조회할 수 없습니다.");
return -1;
}
return stackArray[top];
}
// 스택의 상단 데이터 제거public int pop() {
if (isEmpty()) {
System.out.println("스택이 비어있습니다. 데이터를 제거할 수 없습니다.");
return -1;
}
return stackArray[top--];
}
// 스택의 모든 데이터 출력public void printStack() {
System.out.print("스택 내용: ");
for (int i = 0; i <= top; i++) {
System.out.print(stackArray[i] + " ");
}
System.out.println();
}
public static void main(String[] args) {
ArrayStack stack = new ArrayStack(5);
stack.push(1);
stack.push(2);
stack.push(3);
stack.push(4);
stack.push(5);
stack.push(6);// 스택이 가득 차서 추가되지 않음
stack.printStack();// 1 2 3 4 5 출력
System.out.println("스택의 상단 데이터: " + stack.peek());// 5 출력
System.out.println("스택의 상단 데이터 제거: " + stack.pop());// 5 출력
stack.printStack();// 1 2 3 4 출력
}
}[코드 1-2] List로 구현한 Stack
Stack의 시간복잡도와 공간복잡도
Stack의 시간복잡도(Time Complexity)
스택은 그 특성상 데이터를 추가하거나 제거하는 데 있어서 상수 시간, 즉 O(1)의 시간 복잡도를 가집니다. 이는 상단에 위치한 요소에만 접근하고 조작하기 때문입니다. 따라서 스택의 크기와 무관하게, 스택의 주요 연산들은 모두 상수 시간에 수행됩니다.
- Push(삽입) 연산: 상단에 요소를 추가하면 되기 때문에 연산이 상수 시간에 완료됩니다.
- Pop(삭제) 연산: 상단에 위치한 요소를 제거하면 되기 때문에 연산이 상수 시간에 완료됩니다.
- Peek(조회) 연산: 상단에 위치한 요소를 직접할 수 있기 때문에 연산이 상수 시간에 완료됩니다.
- IsEmpty(비어있는지 확인) 연산: 상단이 -1인지를 확인하면 되기 때문에 연산이 상수 시간에 완료됩니다.
스택의 공간복잡도(Space Complexity)
스택의 공간복잡도는 구현하는 방식에 따라 다릅니다.
- 배열(Array) 기반 구현: 미리 정의된 크기의 배열을 사용하여 구현합니다. 스택의 크기가 고정되어 있으므로, 배열의 크기 n만큼의 공간이 필요합니다. 배열 기반 스택의 공간복잡도는 O(n)입니다.
- 연결 리스트(Linked List) 기반 구현: 연결 리스트 기반 스택은 동적으로 크기가 조정되는 연결 리스트를 사용하여 구현됩니다. 각 요소는 노드로 표현되고, 노드에는 데이터와 다음 노드를 가리키는 링크가 포함됩니다. 연결 리스트 기반 스택의 공간복잡도는 O(n)입니다. 여기서 n은 스택에 저장된 요소의 개수입니다.
- 동적 배열(Dynamic Array) 기반 구현: 동적 배열 기반 스택은 동적으로 크기가 조정되는 배열을 사용하여 구현됩니다. 요소를 추가하거나 제거할 때 배열의 크기를 동적으로 조정할 수 있습니다. 동적 배열 기반 스택의 공간복잡도는 O(n)입니다. 동적 배열의 크기가 변경될 때마다 일시적으로 추가적인 메모리 할당 및 해제가 발생할 수 있습니다.
- 프로그래밍 언어별 내장 스택: 특정 프로그래밍 언어에서 스택을 내장(built-in) 자료구조로 제공합니다. 이 경우 그 공간 복잡도는 해당 언어의 스택 구현에 따라 다를 수 있습니다. 예를 들어, C++의 std::stack은 동적 배열을 기반으로 하므로, 요소를 저장하기 위한 메모리 공간을 동적으로 할당하고 해제하는 과정에서 추가적인 메모리 사용이 발생할 수 있습니다. Java의 java.util.Stack과 Python의 리스트를 활용한 스택도 마찬가지입니다. 이들은 모두 동적 배열로 구현되어 있어, 크기가 동적으로 조정됩니다. 한편, C는 스택을 내장 자료구조로 제공하지 않으므로, 직접 구현해야 합니다.
스택을 활용한 문제
1. 문제 접근 방식
문제의 요구사항은 다음과 같습니다.
주어진 문자열에서 괄호들이 올바른 순서로 입력되었는지 확인하는 문제입니다. 이를 위해서는 다음과 같은 규칙을 따라야 합니다
- 모든 여는 괄호에 대응하는 닫는 괄호가 있어야 합니다.
- 여는 괄호와 닫는 괄호의 순서가 일치해야 합니다.
- 모든 괄호 쌍은 서로 중첩되지 않아야 합니다.
2. 풀이
- 주어진 문자열을 입력 받습니다.
- 스택을 초기화합니다.
- 문자열을 한 글자씩 순회하면서 다음 작업을 수행합니다:
- 여는 괄호인 경우:
- 스택에 해당 괄호를 push합니다.
- 닫는 괄호인 경우:
- 스택이 비어있는지 확인합니다. 비어있다면 올바르지 않은 괄호이므로 결과를 반환합니다.
- 스택의 top에 있는 괄호와 현재 괄호가 짝이 맞는지 확인합니다. 짝이 맞지 않다면 결과를 반환합니다.
- 짝이 맞다면 스택에서 해당 괄호를 pop합니다.
- 여는 괄호인 경우:
- 문자열을 모두 순회한 뒤, 스택이 비어있는지 확인합니다. 비어있다면 올바른 괄호이므로 true를 반환합니다. 그렇지 않다면 false를 반환합니다.
이러한 접근 방식으로 주어진 문자열의 괄호가 올바른 순서로 짝지어졌는지 확인할 수 있습니다.
- 주어진 코드는 암호 해독을 위해 decrypt 함수를 정의하고, 내부적으로 dfs 함수를 사용하여 암호 해독을 수행합니다.
- decrypt 함수:
- ciphertext와 dictionary를 입력으로 받습니다.
- dfs 함수를 호출하여 암호 해독을 수행하고, 결과를 반환합니다.
- 반환된 결과가 None이 아니면 암호 해독에 성공한 것이므로 결과를 출력합니다.
- 반환된 결과가 None인 경우 암호 해독에 실패했다는 메시지를 출력합니다.
- dfs 함수:
- plaintext와 index를 입력으로 받습니다. plaintext는 현재까지 생성된 해독된 문자열을 나타내고, index는 현재까지 탐색한 암호문의 인덱스를 나타냅니다.
- 만약 index가 암호문의 길이와 동일한 경우, 모든 암호문을 해독한 것이므로 plaintext를 반환합니다.
- 주어진 dictionary를 순회하면서 다음을 확인합니다:
- 단어의 길이가 남은 암호문의 길이보다 작거나 같고, 암호문의 현재 위치에서부터 단어로 시작하는 경우
- plaintext에 단어를 추가하고, index에 단어의 길이를 더하여 재귀적으로 dfs 함수를 호출합니다.
- 재귀적인 호출에서 해독에 성공한 경우, 해당 결과를 반환합니다.
- 모든 단어에 대해 해독을 시도한 후에도 성공적인 해독이 없는 경우, None을 반환합니다.
문제: 암호 해독하기
문제 설명:
주어진 문자열을 암호 해독하는 프로그램을 작성하십시오. 암호 해독은 다음과 같은 방식으로 이루어집니다:
- 주어진 문자열에서 가능한 모든 조합을 생성합니다.
- 주어진 조합이 암호 해독에 성공하는지 확인합니다.
- 성공적인 암호 해독 조합을 반환합니다.
- 암호 해독의 성공 조건은 다음과 같습니다:a. 주어진 조합의 문자열을 모두 연결했을 때, 암호화된 문자열과 일치해야 합니다.
주어진 ciphertext는 암호화된 문자열을 나타내며, dictionary는 가능한 단어들의 목록입니다.
입력
- ciphertext: 암호화된 문자열입니다. 암호를 해독하기 위해 이 문자열을 해석해야 합니다.
- dictionary: 가능한 단어들의 목록입니다. 암호 해독에 사용되는 단어들의 집합입니다.
알고리즘 설명
주어진 코드는 DFS(깊이 우선 탐색) 알고리즘을 이용하여 암호 해독을 수행합니다. 다음은 알고리즘의 동작 과정입니다:
- dfs 함수는 plaintext와 index를 입력으로 받습니다. plaintext는 현재까지 생성된 해독된 문자열을 나타내며, index는 현재까지 탐색한 암호문의 인덱스를 나타냅니다.
- index가 암호문의 길이와 동일한 경우, 모든 암호문을 해독한 것이므로 plaintext를 반환합니다.
- 주어진 dictionary를 순회하면서 각 단어에 대해 다음을 확인합니다:
- 단어의 길이가 남은 암호문의 길이보다 작거나 같고, 암호문의 현재 위치에서부터 단어로 시작하는 경우
- plaintext에 단어를 추가하고, index에 단어의 길이를 더하여 재귀적으로 dfs 함수를 호출합니다.
- 재귀적인 호출에서 해독에 성공한 경우, 해당 결과를 반환합니다.
- 모든 단어에 대해 해독을 시도한 후에도 성공적인 해독이 없는 경우, None을 반환합니다.
입출력 예시
입력
ciphertext = "abcdabcdabcd"
dictionary = ["ab", "cd", "abcd", "bc", "d"]
출력
암호 해독 결과: abcdabcdabcd
입력
ciphertext = "abcdef"
dictionary = ["ab", "cd", "ef"]
출력
암호 해독 결과: abcd ef
입력
ciphertext = "abcd"
dictionary = ["ab", "bc", "cd"]
출력
암호 해독에 실패했습니다.
1. 문제 접근 방식
문제의 요구사항은 다음과 같습니다.
주어진 스도쿠 퍼즐을 해결하는 프로그램을 작성하십시오. 스도쿠 퍼즐은 9x9 크기의 격자로 이루어져 있으며, 각 격자 칸에는 1부터 9까지의 숫자 중 하나를 채워야 합니다.
이 문제를 해결하기 위해 다음과 같은 접근 방식을 사용할 수 있습니다.
- DFS(깊이 우선 탐색) 알고리즘을 이용합니다.
- 모든 칸을 순회하면서 빈 칸을 찾습니다.
- 빈 칸을 찾았을 때, 가능한 숫자를 하나씩 채워보고 규칙을 확인합니다.
- 규칙을 만족하는 숫자를 찾았을 경우, 해당 칸에 숫자를 채우고 재귀적으로 DFS를 호출합니다.
- 재귀적인 호출에서 해결에 성공한 경우, 스도쿠 퍼즐을 해결한 것이므로 True를 반환합니다.
- 가능한 숫자를 모두 시도해도 해결에 실패한 경우, 스도쿠 퍼즐을 해결할 수 없으므로 False를 반환합니다.
이러한 접근 방식으로 주어진 스도쿠 퍼즐을 해결할 수 있습니다.
2. 풀이
주어진 코드는 위에서 설명한 접근 방식을 구현한 코드입니다. 주요 함수인 dfs 함수는 현재 스도쿠 퍼즐 상태를 입력으로 받아 재귀적으로 호출하여 스도쿠 퍼즐을 해결합니다. isValid 함수는 주어진 숫자가 스도쿠 퍼즐의 규칙을 만족하는지 확인하는 함수입니다.
이 코드를 실행하면 스도쿠 퍼즐의 빈 칸을 순회하면서 가능한 숫자를 시도하고, 규칙을 만족하는 숫자를 찾아 퍼즐을 해결합니다. 최종적으로 해결된 스도쿠 퍼즐이 출력됩니다.
이러한 방식으로 주어진 스도쿠 퍼즐을 해결할 수 있습니다.
입력:
- graph: 그래프의 인접 리스트 표현입니다. 그래프는 정점의 개수와 간선의 정보를 포함합니다.
알고리즘 설명:
주어진 코드는 BFS(너비 우선 탐색) 알고리즘을 이용하여 시작 정점에서 도착 정점까지의 최단 경로를 계산합니다. 다음은 알고리즘의 동작 과정입니다:
- 그래프를 초기화합니다.
- 시작 정점과 도착 정점을 설정합니다.
- 방문 여부를 저장하는 배열과 이전 정점을 저장하는 배열을 생성합니다.
- 큐를 초기화하고 시작 정점을 큐에 추가하고 방문 여부를 표시합니다.
- 큐가 비어있지 않은 동안 다음 작업을 수행합니다:
- 큐에서 정점을 하나 꺼내어 현재 정점으로 설정합니다.
- 현재 정점이 도착 정점과 같은지 확인합니다. 같다면 최단 경로를 역추적하여 반환합니다.
- 현재 정점과 연결된 이웃 정점들을 순회하면서 방문하지 않은 정점을 큐에 추가하고 방문 여부를 표시하고 이전 정점을 저장합니다.
- 도착 정점에 도달할 수 없는 경우, 빈 리스트를 반환합니다.
입출력 예시
입력
// 그래프 초기화Graph graph = new Graph(8);
// 간선 추가
graph.addEdge(0, 1);
graph.addEdge(0, 3);
graph.addEdge(1, 2);
graph.addEdge(1, 4);
graph.addEdge(2, 5);
graph.addEdge(3, 4);
graph.addEdge(4, 5);
graph.addEdge(4, 6);
graph.addEdge(5, 7);
graph.addEdge(6, 7);
// 시작 정점과 도착 정점 설정int startVertex = 0;
int endVertex = 7;
// 그래프의 모습0---1---2---5---7
| | |
| 4---6
|
3
출력
최단 경로: 0 1 4 6 7
입출력 예시
입력
# 초기 상태와 목표 상태 정의
initial_state = [[1, 2, 3], [4, 5, 6], [7, 0, 8]]
target_state = [[1, 2, 3], [4, 5, 6], [7, 8, 0]]
출력
최단 경로: UP -> LEFT -> LEFT -> DOWN -> DOWN -> RIGHT -> UP -> LEFT -> DOWN
위 문서는 상태 공간 탐색 문제에 대한 설명 문서입니다. 마지막에 입출력 예시를 채워야 합니다. 주어진 코드를 참고하여 내용을 추가해주세요.
1. 알고리즘이란 무엇일까?
- 알고리즘의 정의: 알고리즘의 기본적인 정의를 배우고, 알고리즘이 일상 생활에서 어떻게 적용되는지 여러 예시를 통해 이해합니다.
- 알고리즘의 특성: 알고리즘의 다섯 가지 주요 특성인 명확성, 유한성, 효과성, 입력, 출력을 자세히 배웁니다.
- 알고리즘의 분류: 정렬, 탐색, 동적 프로그래밍 등 다양한 종류의 알고리즘을 소개하고, 각 알고리즘의 기본적인 동작 방식과 사용 사례에 대해 설명합니다.
2. 문제의 이해 및 분석하기
- 문제 해석 기술: 문제를 효과적으로 해석하고 이해하는 방법을 배웁니다. 이는 문제의 조건과 요구사항을 정확히 파악하는 데 도움이 됩니다.
- 분석 전략: 주어진 문제를 체계적으로 분석하는 전략을 배웁니다. 이는 문제의 복잡성을 파악하고, 문제를 해결하기 위한 적절한 알고리즘을 선택하는 데 도움이 됩니다.
- 예제 문제: 실제 알고리즘 문제를 분석하고 이해하는 과정을 실습합니다.
3. 문제를 작은 단위로 분할하기
- 분할 정복 기법: 복잡한 문제를 더 작고 관리하기 쉬운 하위 문제로 분할하는 전략을 배웁니다. 이는 문제 해결 과정을 단순화하고, 문제 해결에 필요한 시간을 줄이는 데 도움이 됩니다.
- 재귀적 사고: 문제를 하위 문제로 분할하고 이를 재귀적으로 해결하는 방법에 대해 배웁니다.
- 예제 문제: 분할 정복 기법과 재귀적 사고를 사용하여 문제를 해결하는 과정을 실습합니다.
4. 시간복잡도와 공간복잡도
- 복잡도 이해: 알고리즘의 효율성을 측정하는 두 가지 중요한 척도인 시간 복잡도와 공간 복잡도에 대해 배웁니다.
- 빅오 표기법: 알고리즘의 복잡도를 표현하는 데 사용되는 빅오 표기법에 대해 배웁니다.
- 최적화 전략: 알고리즘의 시간 복잡도와 공간 복잡도를 최적화하는 전략에 대해 배웁니다. 이는 알고리즘의 효율성을 향상시키는 데 도움이 됩니다.
큐(Queue)
큐(Queue)의 개념과 특징

Queue의 정의
큐(Queue)는 줄을 서서 기다리다, 대기열이라는 뜻을 가지고 있습니다. 이는 실생활에서 줄을 서서 기다리는 것과 유사한 구조로 이해하시면 됩니다. 예를 들어, 슈퍼마켓에서 계산을 기다리는 사람들이 줄을 서 있을 때, 먼저 줄을 선 사람이 먼저 계산을 마치고 나가는 것과 같습니다.
명절 때 고향을 찾아가려고 많은 자동차들이 고속도로를 이용합니다. 고속도로에는 톨게이트가 있고, 자동차들은 톨게이트에 도착한 순서대로 통행료를 내고 통과합니다.
톨게이트를 큐, 자동차는 데이터(data)로 비유할 수 있습니다.

[그림] 큐는 순서대로 지나가는 자동차가 지나가는 톨게이트와 유사합니다.
이 비유에서 알 수 있듯이, 가장 먼저 톨게이트에 도착한 자동차가 가장 먼저 통과합니다. 반대로 말하면, 가장 나중에 도착한 자동차는 앞에 도착한 모든 자동차들이 통과할 때까지 톨게이트를 통과할 수 없습니다.
Queue의 구조
큐는 Stack과 반대되는 개념으로, 먼저 들어간 데이터가 먼저 나오는 FIFO(First In First Out) 혹은 LILO(Last In Last Out) 특성을 가지고 있습니다. 이는 티켓을 사기 위해 줄을 서서 기다리는 모습과 매우 유사합니다. 이 자료 구조는 입력과 출력의 방향이 고정되어 있으며, 두 곳에서 접근이 가능합니다. 큐에 데이터를 넣는 것을 'enqueue', 데이터를 꺼내는 것을 'dequeue'라고 합니다.
큐는 데이터를 입력된 순서대로 처리해야 할 때 주로 사용됩니다.
Queue의 특징
1. FIFO (First In First Out)
먼저 들어간 데이터가 가장 먼저 나오는 선입선출의 구조를 가지고 있습니다. 이는 공정한 순서를 유지하고자 할 때 유용합니다. 예를 들어, 프린터 대기열에서 문서를 인쇄하거나, 고객 서비스 센터에서 대기 중인 전화를 처리하는 등의 상황에서 큐를 사용할 수 있습니다.
2. 데이터는 하나씩 넣고 뺄 수 있습니다.
데이터가 아무리 많아도 한 번에 하나씩만 데이터를 추가하거나 제거합니다. 한 번에 여러 개의 데이터를 추가하거나 제거하는 것은 허용되지 않습니다. 이는 큐의 FIFO 특성을 유지하는 데 중요합니다.
3. 두 개의 입출력 위치를 가지고 있습니다.
데이터는 큐의 한쪽 끝에서 추가되고, 반대쪽 끝에서 제거됩니다. 이 특징은 큐를 사용하는 다양한 애플리케이션에서 중요한 역할을 합니다.
Queue 자료 구조의 이점
1. 데이터를 순차적으로 처리할 수 있습니다.
큐는 선입선출(First-In-First-Out, FIFO) 원칙을 따르므로, 가장 먼저 삽입된 데이터가 가장 먼저 삭제되고, 가장 나중에 삽입된 데이터는 가장 나중에 삭제됩니다. 이 특성 덕분에, 처리해야 할 데이터나 작업을 순차적으로 처리할 수 있습니다.
큐의 가장 앞(front)에서는 가장 오래전에 삽입된 데이터가 위치하고, 가장 뒤(rear)에는 가장 최근에 삽입된 데이터가 위치합니다. 즉, 데이터를 삽입하는 순서와 삭제하는 순서가 일치하게 유지됩니다..
이런 구조는 데이터 처리나 작업 처리에서 순서가 중요한 경우에 유용합니다. 예를 들어, 프린터에서 인쇄 요청이 들어온 순서대로 처리해야 하는 경우, 은행에서 대기 중인 고객 순서를 결정하는 경우, 채팅 시스템에서 메시지를 보내는 순서를 결정하는 경우 등에 큐를 활용할 수 있습니다.
2. 삽입과 삭제가 각각 양 끝에서 이루어지며 중간 원소를 삭제하는 연산이 없으므로, 다른 자료 구조에 비해 상대적으로 빠른 속도를 보입니다.
큐의 삽입과 삭제는 각각 큐의 끝단에서 이루어지기 때문에, 중간에 있는 원소를 삭제하는 연산이 없습니다. 이것은 배열과 같은 다른 자료 구조와 다릅니다.
배열의 경우, 중간에 있는 원소를 삭제하려면 삭제한 원소 이후의 모든 원소를 한 칸씩 앞으로 이동시켜야 합니다. 이 때문에 중간의 원소를 삭제한다면, 이후의 배열을 복사하고 다시 순회하며 데이터를 삽입하는 과정을 거쳐야 합니다. 삭제한 원소 뒤에 새로운 원소를 삽입하려면 빈자리를 만들기 위해 이후의 원소들을 한 칸씩 뒤로 밀어야 하므로 삽입 연산에서도 전체 배열을 순회해야 합니다.
반면, 큐에서는 삽입 연산은 큐의 끝단에서 새로운 원소를 추가하는 것으로 끝나며, 삭제 연산은 큐의 첫 번째 원소를 삭제하는 것으로 끝납니다. 따라서, 큐에서의 삽입과 삭제 연산은 단 한 번의 실행만으로 처리할 수 있습니다.
이러한 이유로 큐는 삽입과 삭제가 빈번하게 일어나는 상황에서 상대적으로 빠른 속도를 보이며, 데이터나 작업을 차례대로 처리해야 하는 상황에서 효과적으로 사용될 수 있습니다.
Queue 자료 구조의 한계
1. 큐는 자료 구조의 가장 앞에서 데이터를 꺼내는 연산과 가장 뒤에서 데이터를 추가하는 연산만 가능하기 때문에, 중간에 있는 데이터를 조회하거나 수정하는 연산에는 적합하지 않습니다.
큐는 데이터를 가장 먼저 추가한 위치에서부터 차례로 데이터를 처리하며, 가장 나중에 추가된 위치에서 새로운 데이터를 추가합니다. 이러한 구조 때문에 큐는 특정 위치의 데이터를 조회하거나 수정하는 연산에 적합하지 않습니다.
즉, 큐에서는 가장 앞에서 dequeue 연산(poll)으로 데이터를 삭제하거나, 가장 뒤에서 enqueue 연산(add)으로 데이터를 추가하는 것만 가능합니다. 큐는 다른 위치의 데이터에 직접 접근하여 데이터를 변경하는 연산이 불가능하며, 중간에 있는 데이터를 조회하는 것도 불가능합니다. 따라서 큐는 데이터를 순차적으로 처리하는 데 적합한 자료 구조입니다.
Queue의 실제 사용 사례
큐는 컴퓨터 시스템에서 광범위하게 활용됩니다. 예를 들어, 컴퓨터와 연결된 프린터에서 여러 문서를 순서대로 인쇄하는 경우를 생각해봅시다.
- 사용자가 문서를 작성하고 출력 버튼을 누르면 해당 문서는 임시 기억 장치인 인쇄 작업 큐에 추가됩니다.
- 프린터는 인쇄 작업 큐에 추가된 문서를 순서대로 인쇄합니다.
컴퓨터(출력 버튼) - 문서가 하나씩 인쇄 작업 큐에 추가됨 - 큐에 추가된 문서를 순서대로 인쇄
만약 큐에 추가된 순서대로 출력하지 않는다면, 인쇄 결과물이 뒤죽박죽일 것입니다.
대부분의 컴퓨터 장치에서 발생하는 이벤트는 불규칙적으로 발생합니다. 반면, CPU와 같이 발생한 이벤트를 처리하는 장치는 일정한 처리 속도를 갖습니다. 불규칙적으로 발생한 이벤트를 규칙적으로 처리하기 위해 버퍼(buffer)를 사용합니다.

[그림] (왼쪽) CPU에서는 이벤트를 규칙적으로 처리합니다. (오른쪽) 대부분의 컴퓨터 장치에서는 이벤트가 불규칙하게 발생합니다.
컴퓨터와 프린터 간의 데이터 통신을 정리하면 아래와 같습니다.
- 일반적으로 프린터는 처리 속도가 상대적으로 느립니다.
- 반면에, CPU는 프린터와 비교할 때 데이터를 처리하는 속도가 훨씬 빠릅니다.
- 그래서 CPU는 빠른 속도로 인쇄에 필요한 데이터를 생성한 후, 이를 인쇄 작업 큐에 저장하고 다른 작업을 계속 수행합니다.
- 프린터는 인쇄 작업 큐에서 데이터를 가져와 일정한 속도로 인쇄하는 작업을 수행합니다.
유튜브와 같은 동영상 스트리밍 앱에서 동영상을 시청하는 경우를 생각해봅시다. 다운로드된 데이터가 영상을 재생하기에 충분하지 않은 경우가 있습니다. 이럴 때, 동영상을 원활하게 재생하기 위해 데이터를 큐에 저장해두고, 충분한 양의 데이터가 모일 때까지 기다린 후에 동영상을 재생합니다. 이렇게 큐는 데이터 처리의 효율성을 높이는 데 중요한 역할을 합니다.

큐의 기본 연산
Queue 의 기본 연산
큐는 일렬로 나열된 데이터를 가지며, Rear(뒷부분)은 새로운 요소가 삽입되는 위치를, Front(앞부분)은 요소가 제거되는 위치를 나타냅니다.
Enqueue(삽입) 연산
- 새로운 요소를 큐의 뒷부분(rear)에 추가합니다.
- 삽입 연산은 큐에 요소를 추가하는 작업입니다.
- 새로운 요소는 큐의 가장 뒤(rear)에 위치하게 됩니다.
- 큐가 가득 차 있는 경우, 삽입 연산은 실패할 수 있습니다.
Dequeue(삭제) 연산
- 큐의 앞부분(front)에 위치한 요소를 제거하고 반환합니다.
- 삭제 연산은 큐에서 요소를 제거하는 작업입니다.
- 가장 먼저 추가된 요소가 가장 먼저 제거됩니다.
- 큐가 비어있는 경우, 삭제 연산은 실패할 수 있습니다.
Peek(조회) 연산
- 큐의 앞부분(front)에 위치한 요소를 반환합니다.
- 조회 연산을 수행하더라도 큐에서 요소가 제거되지 않습니다.
- 큐의 가장 앞(front)에 위치한 요소를 확인할 수 있습니다.
IsEmpty(비어있는지 확인) 연산
- 큐가 비어있는지 확인하는 작업입니다.
- 큐가 비어있으면 true를 반환하고, 비어있지 않으면 false를 반환합니다.
- 큐가 비어있는지 여부를 확인하여 추가적인 조치를 취할 수 있습니다.
큐의 연산은 큐의 상태에 따라 다를 수 있습니다. 예를 들어, 큐가 비어있는 상태에서 Dequeue 연산을 수행하면 오류가 발생할 수 있습니다. 따라서 큐를 사용할 때는 연산을 수행하기 전에 상태를 확인하고 조건에 맞게 처리해야 합니다.
큐의 구현 방법
Queue 자료 구조의 구현 방법
일반적으로 큐는 배열(Array) 또는 연결 리스트(Linked List)를 활용하여 구현할 수 있습니다. 각각의 구현 방법에 대해 알아보겠습니다.
배열(Array) 기반 큐
배열을 사용하여 큐를 구현하는 방법입니다. 큐의 크기를 미리 정의하고, 배열을 이용해 요소를 저장하고 조회합니다. 주요 특징은 다음과 같습니다:
- 필요한 변수와 데이터 구조를 정의합니다
- 큐를 구현하기 위해 정적 배열(static array) 또는 동적 배열(dynamic array)을 선언합니다. 큐의 최대 크기를 고려하여 배열의 크기를 결정합니다.
- 큐의 상태를 추적하기 위한 변수로 front(앞부분)와 rear(뒷부분)을 선언합니다. 이 변수들은 초기에는 큐가 비어있는 상태를 나타내기 위해 동일한 값을 가집니다.
- Enqueue(삽입) 연산
- Enqueue 연산은 새로운 요소를 큐의 뒷부분(rear)에 추가하는 작업입니다.
- rear 변수를 1 증가시켜 다음 뒷부분(rear) 위치로 이동합니다.
- 배열의 rear 위치에 요소를 삽입합니다.
- Dequeue(삭제) 연산
- Dequeue 연산은 큐에서 앞부분(front)에 위치한 요소를 제거하고 반환하는 작업입니다.
- front 변수를 1 증가시켜 다음 앞부분(front) 위치로 이동합니다.
- 배열의 front 위치에 있는 요소를 반환하기 전에 front 변수를 증가시킵니다.
- Peek(조회) 연산
- Peek 연산은 큐의 앞부분(front)에 위치한 요소를 반환하는 작업입니다.
- front 변수의 값에 해당하는 배열 요소를 반환합니다.
- IsEmpty(비어있는지 확인) 연산
- IsEmpty 연산은 큐가 비어있는지 확인하는 작업입니다.
- front와 rear 변수의 값이 동일한 경우, 큐는 비어있는 상태입니다.
연결 리스트(Linked List) 기반 큐
이 방법은 큐의 요소를 노드로 구성하고, 노드들을 연결하여 큐를 형성합니다. 연결 리스트 기반 큐의 주요 특징은 다음과 같습니다:
- 필요한 변수와 데이터 구조를 정의합니다:
- 노드(Node)라는 자료구조를 정의합니다. 각 노드는 데이터를 저장하는 변수와 다음 노드를 가리키는 링크(포인터)로 구성됩니다.
- 큐의 상태를 추적하기 위한 변수로 front(앞부분)와 rear(뒷부분)을 선언합니다. 이 변수들은 초기에는 큐가 비어있는 상태를 나타내기 위해 NULL 또는 특정 값을 가집니다.
- Enqueue(삽입) 연산
- Enqueue 연산은 새로운 요소를 큐의 뒷부분(rear)에 추가하는 작업입니다.
- 새로운 노드를 생성하고 데이터를 저장합니다.
- rear 변수를 업데이트하여 새로운 노드를 큐의 뒷부분(rear)으로 지정합니다.
- 이전 rear 노드의 링크를 새로운 노드로 연결합니다.
- Dequeue(삭제) 연산
- Dequeue 연산은 큐에서 앞부분(front)에 위치한 요소를 제거하고 반환하는 작업입니다.
- front 변수를 업데이트하여 다음 앞부분(front)으로 이동합니다.
- front가 가리키는 노드의 데이터를 반환합니다.
- 이전 front 노드를 삭제하고 front 변수를 업데이트합니다.
- Peek(조회) 연산
- Peek 연산은 큐의 앞부분(front)에 위치한 요소를 반환하는 작업입니다.
- front 변수가 가리키는 노드의 데이터를 반환합니다.
- IsEmpty(비어있는지 확인) 연산
- IsEmpty 연산은 큐가 비어있는지 확인하는 작업입니다.
- front와 rear 변수가 NULL 또는 특정 값을 가지고 있는지 확인하여 큐의 비어있는 상태를 판별합니다.
- 필요한 경우 예외 처리를 추가합니다
- 큐가 비어있는 상태에서 Dequeue 연산을 수행하려는 경우 "큐 언더플로우(Queue Underflow)" 예외를 처리합니다.
- 큐의 크기를 제한한 경우, 큐가 가득 찬 상태에서 Enqueue 연산을 수행하려는 경우 "큐 오버플로우(Queue Overflow)" 예외를 처리합니다.
연결 리스트 기반 큐는 크기가 동적으로 조정될 수 있어 유연성이 높고, 메모리를 효율적으로 사용할 수 있습니다. 또한, 큐의 요소들이 메모리 상에 연속적으로 위치할 필요가 없어서, 요소를 삽입하거나 삭제하는 작업에서 발생하는 복잡성을 줄일 수 있습니다.
큐의 시간 복잡도와 공간 복잡도
큐의 시간복잡도(Time Complexity)
- Enqueue(삽입) 연산: O(1)
- 큐의 맨 뒤(rear)에 데이터를 삽입하는 연산입니다.
- 배열을 사용한 구현에서는 데이터를 삽입할 위치를 기억하고 있는 변수(rear)를 증가시키는 것으로 수행됩니다.
- 연결 리스트를 사용한 구현에서는 리스트의 맨 뒤에 노드를 추가하는 연산으로 수행됩니다.
- 어떤 경우에도 데이터를 삽입하는 데에는 상수 시간이 소요됩니다.
- Dequeue(삭제) 연산: O(1)
- 큐의 맨 앞(front)에서 데이터를 제거하는 연산입니다.
- 배열을 사용한 구현에서는 데이터를 제거할 위치를 기억하고 있는 변수(front)를 1 증가시키는 것으로 수행됩니다.
- 연결 리스트를 사용한 구현에서는 리스트의 맨 앞에서 노드를 제거하는 연산으로 수행됩니다.
- 어떠한 경우에도 데이터를 제거하는 데에는 상수 시간이 소요됩니다.
- Peek(조회) 연산: O(1)
- 큐의 맨 앞(front)에서 데이터를 조회하는 연산입니다.
- 배열이나 연결 리스트에서는 맨 앞의 데이터에 접근하는 것이 간단하므로 상수 시간에 수행됩니다.
- 데이터를 제거하지 않고 조회하는 연산이므로 큐의 크기에 영향을 주지 않습니다.
큐의 공간복잡도(Space Complexity)
- 큐의 공간 복잡도는 큐에 저장되는 데이터의 개수에 비례합니다.
- 배열을 사용한 구현에서는 배열의 크기가 큐의 최대 크기를 결정하므로 O(N)입니다. (N은 큐에 저장되는 데이터의 개수)
- 연결 리스트를 사용한 구현에서는 필요한 만큼의 노드를 동적으로 생성하므로 실제 데이터 개수에 따라 공간이 사용됩니다. 따라서 최대 O(N)입니다.
그래프(Graph)
그래프(Graph)의 정의와 구조

그래프의 정의
그래프는 여러 개의 점들이 서로 복잡하게 연결되어 있는 관계를 표현한 자료 구조입니다.
그래프라는 단어를 들으면 어떤 이미지가 떠오르나요? 만약 자료 구조의 그래프를 처음 접하는 거라면, 아마 대부분의 사람들이 아래와 같은 그림을 떠올릴 것입니다.

[그림] 수학의 그래프 예시
X축과 Y축이 존재하고, X축의 값에 따라 Y축의 값을 나타내는 그래프, 또는 수학 수업이나 발표에서 사용되는 자료로 자주 접한 이 그래프를 말입니다. 그러나 컴퓨터 공학에서 말하는 자료 구조 그래프는 전혀 다른 모습을 보입니다. 자료 구조의 그래프는 여러 개의 점들이 선으로 연결되어 있는, 거미줄처럼 복잡한 네트워크와 유사한 모습을 보입니다.

[그림] 자료 구조 그래프 예시
그래프의 구조
- 직접적인 관계가 있는 경우 두 점 사이를 이어주는 선이 있습니다.
- 간접적인 관계라면 몇 개의 점과 선에 걸쳐 이어집니다.
- 그래프에서 하나의 점은 정점(vertex)이라고 표현하며, 하나의 선은 간선(edge)이라고 합니다.
아래에 간단한 그래프를 보여드리겠습니다. 각 요소가 무엇인지 확인해보세요.

[그림] 정점 A, B, C와 2개의 단방향 간선, 그리고 하나의 양방향 간선이 있는 그래프
그래프의 실사용 예제
그래프 자료구조의 실용성에 대한 인식은 종종 우리 일상생활에서 간과됩니다. 실제로, 포털 사이트의 검색 엔진, 소셜 네트워킹 서비스의 관계 연결, 그리고 내비게이션의 경로 찾기 기능 등, 우리가 매일 이용하는 수많은 서비스들은 그래프 자료구조의 활용에 의존하고 있습니다. 언급한 각각의 서비스는 다수의 정점을 포함하며, 이 정점들은 서로 간선으로 연결되어 있습니다. 세 가지 서비스 중, 내비게이션 시스템이 그래프 자료구조를 어떻게 활용하는지에 대해 조금 더 깊이 이해해보도록 하겠습니다.
가정해봅시다. 서울에 거주하는 A씨는 오랜 친구인 부산에 사는 B씨의 결혼식에 참석하기 위해, 차를 몰고 부산으로 향할 계획입니다. 또한 대전에 살고 있는 친구 C씨도 B씨의 결혼식에 참석한다고 하여, A씨는 서울에서 출발하여 대전에서 C씨를 만나 함께 부산으로 이동하려고 합니다.
이 시나리오에서는 세 개의 주요 정점이 존재합니다. 각각의 정점은 A, B, C가 거주하는 도시 (서울, 부산, 대전)를 나타내며, 이 정점들은 각각의 관계를 표현하는 간선으로 연결되어 있습니다.
- 정점: 서울, 대전, 부산
- 간선: 서울—대전, 대전—부산, 부산—서울
위의 예에서 서울, 대전, 부산 간에는 간선이 존재하는데, 이 간선은 내비게이션에서 "이동 가능함"을 표시합니다. 그렇다면 캐나다의 토론토를 정점으로 추가한다면 어떻게 될까요? 자동차로는 토론토에서 한국으로 이동할 수 없으므로, 간선은 추가되지 않습니다. 이를 그래프에서는 "관계가 없음"으로 표현합니다.
이렇게 볼 때, 간선은 서울, 대전, 부산이 서로 관련이 있다는 사실을 알려주지만, 각 도시가 실제로 얼마나 떨어져 있는지는 알려주지 않습니다. 이는 간선이 특정 도시 두 개가 연결되어 있다는 사실만을 전달하며, 그 외의 정보는 제공하지 않기 때문입니다. 이와 같이 추가 정보를 제공하지 않는 그래프를 **"비가중치 그래프"**라고 합니다.
이 그래프를 코드로 표현하면 아래와 같습니다:
/*
1 == 서울, 2 == 부산, 3 == 대전
0은 연결되지 않은 상태, 1은 연결된 상태 (간선을 정수로 표현)
*/
[1] = [0, 1, 1]// 서울 - 부산 , 서울 - 대전
[2] = [1, 0, 1]// 부산 - 서울 , 부산 - 대전
[3] = [1, 1, 0]// 대전 - 서울 , 대전 - 부산
[코드] 비가중치 그래프로 나타낸 서울, 대전, 부산 그래프
이 코드는 서울에서 부산까지 이동 가능함을 나타내지만, 그 이상의 정보를 제공하지 않습니다. 내비게이션 시스템이라면 최소한 각 도시 간의 거리 정보를 제공해야 할 것입니다. 이를 위해 "비가중치 그래프"를 "가중치 그래프"로 변환하고, 각 도시 간의 거리를 포함해볼 수 있습니다.
- 정점: 서울, 대전, 부산
- 간선: 서울—140km—대전, 대전—200km—부산, 부산—325km—서울
이처럼 간선에 연결 정도(거리 등)를 표현한 그래프를 가중치 그래프라고 합니다. 내비게이션은 수백만 개의 정점(주소)과 간선을 포함하고 있는 가중치 그래프를 통해 동작합니다.
알아둬야 할 Graph 용어들
- 정점 (vertex): 노드(node)라고도 하며 데이터가 저장되는 그래프의 기본 원소입니다.
- 간선 (edge): 두 정점을 연결하며, 이들의 관계를 나타냅니다.
- 인접 정점 (adjacent vertex): 간선에 의해 직접 연결된 정점을 의미합니다.
- 가중치 그래프 (weighted Graph): 연결의 강도(추가적인 정보, 위의 예시에서는 서울-부산으로 가는 거리)를 나타내는 그래프를 의미합니다.
- 비가중치 그래프 (unweighted Graph): 연결의 강도를 표현하지 않는 그래프를 의미합니다.
- 무향(무방향) 그래프 (undirected graph): 간선이 양방향을 가리키는 그래프를 의미합니다. 이 경우, 한 정점에서 다른 정점으로 이동하는 것과 반대로 이동하는 것 모두 가능합니다. 앞선 예시에서 서울에서 부산으로 갈 수 있듯, 반대로 부산에서 서울로 가는 것도 가능합니다. 하지만 단방향(directed) 그래프로 구현된다면 서울에서 부산을 갈 수 있지만, 부산에서 서울로 가는 것은 불가능합니다(혹은 그 반대). 만약 두 지점이 일방통행 도로로 이어져 있다면 단방향인 간선으로 표현할 수 있습니다.
- 진입차수 (in-degree) / 진출차수 (out-degree): 한 정점으로 들어오는 간선과 나가는 간선의 수를 의미합니다.
- 인접 (adjacency): 두 정점이 직접 연결되어 있는 경우, 이들을 인접하다고 표현합니다.
- 자기 루프 (self loop): 한 정점에서 시작해서 바로 그 정점으로 돌아오는 경로를 의미합니다.
- 사이클 (cycle): 한 정점에서 시작해서 다시 그 정점으로 돌아오는 경로가 존재한다면, 이를 사이클이 있다고 표현합니다. 내비게이션 그래프는 서울 —> 대전 —> 부산 —> 서울로 이동이 가능하므로, 사이클이 존재하는 그래프입니다.
그래프의 종류

[그림 1-1] 무방향 그래프
무방향 그래프 (Undirected Graph): 무방향 그래프는 각각의 간선이 양방향으로 흐르는, 즉, 어떠한 방향성 없이 두 노드를 연결하는 그래프를 말합니다. 이 경우, 노드 간의 관계는 선으로 표현됩니다. 친구 관계를 나타내는 그래프는 이러한 무방향 그래프의 좋은 예시입니다.

[그림 1-2] 방향 그래프
방향 그래프 (Directed Graph): 방향 그래프는 간선이 한 노드에서 다른 노드로 향하는 방향성을 가지고 있습니다. 이런 방향성은 화살표로 표시되며, 이를 통해 노드 간의 관계가 표현됩니다. 도로망이나 웹 페이지의 하이퍼링크 등을 표현하는 데 방향 그래프가 효과적입니다.
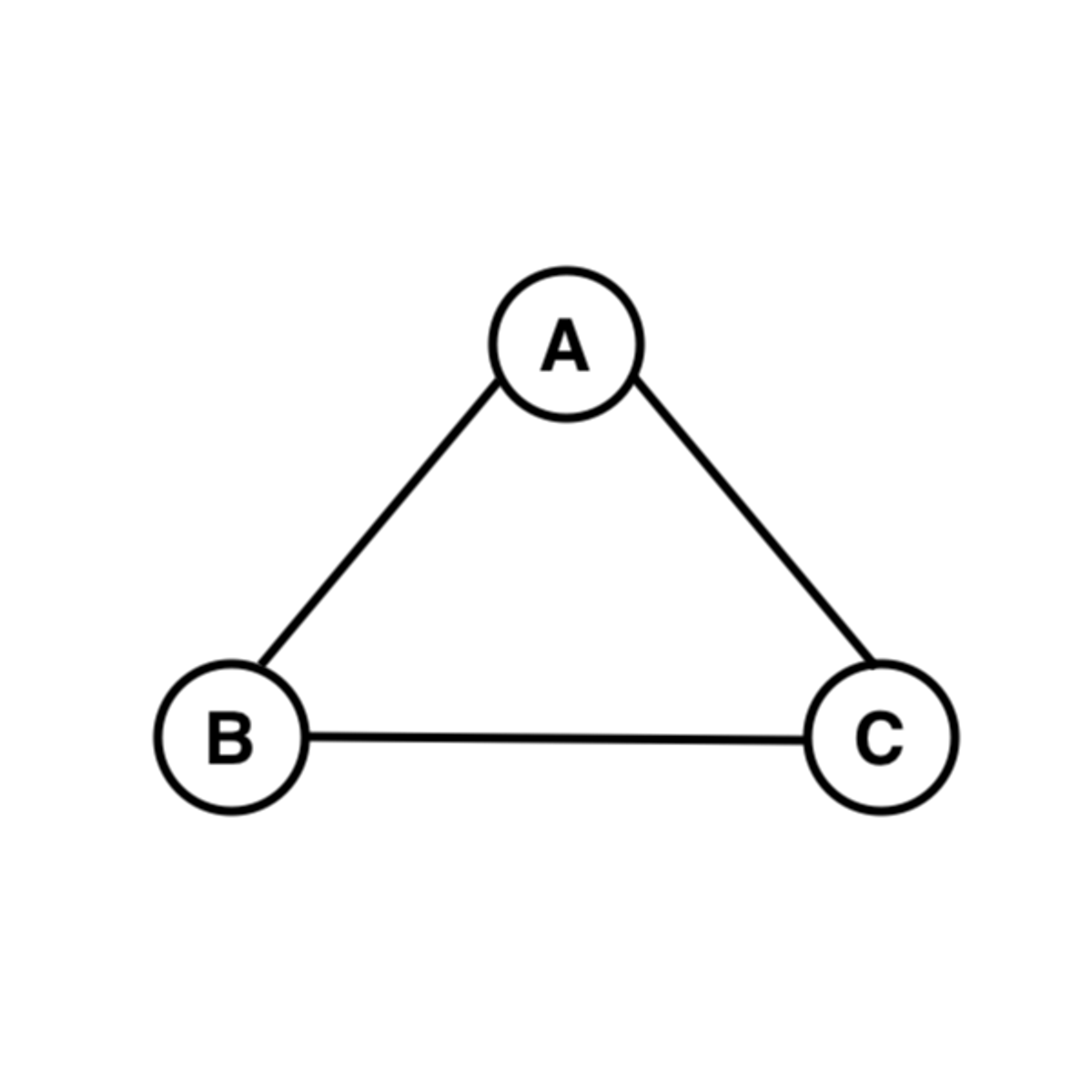
[그림 1-3] 완전 그래프
- 완전 그래프 (Complete Graph): 완전 그래프는 모든 노드가 서로 연결되어 있는, 즉 모든 노드 쌍 사이에 간선이 존재하는 그래프를 의미합니다. 이 경우, n개의 노드가 있을 때 간선의 수는 조합으로 계산된 nC2입니다. 완전 그래프는 노드 간의 모든 가능한 관계를 나타내므로, 모든 노드가 서로 관련된 상황을 표현하는데 사용됩니다.

[그림 1-4] 부분 그래프
부분 그래프 (Subgraph): 부분 그래프는 하나의 큰 그래프의 일부를 추출한 형태로, 주어진 그래프에서 몇 가지 노드와 간선만을 포함합니다. 이러한 방식으로, 우리는 관심 있는 영역만을 집중적으로 조사하고 다룰 수 있습니다. 다만, 부분 그래프가 원래 그래프의 모든 특성을 유지하는 것은 아니며, 일부 특성만을 가질 수도 있습니다.

[그림 1-5] 가중 그래프
가중 그래프 (Weighted Graph): 가중 그래프는 간선에 가중치(weight)가 할당된 그래프입니다. 가중치는 노드 사이의 연결 강도, 거리, 비용 등을 나타내는 값으로 사용됩니다. 가중 그래프는 주로 경로 선택, 네트워크 흐름 등을 모델링하는 데 사용됩니다.

[그림 1-6] 유향 비순환 그래프
유향 비순환 그래프 (Directed Acyclic Graph, DAG): 유향 비순환 그래프는 방향성을 가진 그래프 중에서 사이클이 없는 형태를 지칭합니다. 이는 한 노드에서 출발하여 자신으로 돌아오는 경로가 없음을 의미합니다. 이런 그래프는 일반적으로 우선순위 지정, 작업 스케줄링, 의존 관계 설정 등에 활용됩니다. 특히, 특정 작업들 간의 선후관계를 나타내는 그래프가 유향 비순환 그래프의 일반적인 예시입니다.

[그림 1-7] 연결 그래프
연결 그래프 (Connected Graph): 연결 그래프는 모든 노드 쌍 사이에 경로가 존재하는 그래프를 의미합니다. 즉, 그래프 내에서 임의의 두 노드 사이에 항상 연결되는 경로가 존재합니다. 이런 그래프는 노드 간의 상호작용이 가능하고, 모든 노드가 서로 영향을 주고받는 상황을 표현할 때 주로 사용됩니다. 소셜 네트워크 상에서 친구 관계를 나타내는 그래프가 이 연결 그래프의 대표적인 예시입니다.

[그림 1-8] 단절 그래프
단절 그래프 (Disconnected Graph): 단절 그래프는 무방향 그래프에서 적어도 한 개 이상의 노드 집합이 다른 노드 집합과 연결되지 않은 그래프를 의미합니다. 즉, 이 그래프는 여러 개의 독립된 구성 요소로 분리되어 있습니다. 이러한 그래프는 네트워크 분리 상황이나 독립된 그룹 형성을 표현하는데 사용될 수 있습니다. 인터넷에서의 여러 네트워크 간의 연결 상태를 나타내는 그래프가 단절 그래프의 일반적인 예시입니다.
그래프의 표현 방법과 기본 연산
그래프의 표현 방식
인접 행렬
두 노드를 직접 연결하는 경로가 있으면, 이 두 노드는 인접하다고 표현합니다. 인접 행렬은 서로 다른 노드들이 어떻게 인접해 있는지를 보여주는 2차원 배열입니다. 예를 들어, A 노드와 B 노드가 연결되어 있다면 1(true)로 표시하고, 연결되어 있지 않다면 0(false)로 표시하는 표입니다. 가중치가 존재하는 그래프라면 1 대신 관계의 의미를 나타내는 값이 저장됩니다. 예를 들어, 위의 네비게이션 예제에서는 거리가 저장될 수 있습니다. 네비게이션 그래프를 인접 행렬로 표현하면 아래의 그림과 같습니다.

[그림] 그래프 예시
- 위의 그래프를 인접 행렬로 표시한다면, 다음과 같은 2차원 배열로 나타낼 수 있습니다.
int[][] matrix = new int[][]{// Java 인접행렬 표현
{0, 0, 1},// A정점에서 이동 가능한 정점을 나타내는 행
{1, 0, 1},// B정점에서 이동 가능한 정점을 나타내는 행
{1, 0, 0}// C정점에서 이동 가능한 정점을 나타내는 행
};
int matrix[MAX_VERTICES][MAX_VERTICES] = {// C 인접행렬 표현
{0, 0, 1},// A정점에서 이동 가능한 정점을 나타내는 행
{1, 0, 1},// B정점에서 이동 가능한 정점을 나타내는 행
{1, 0, 0}// C정점에서 이동 가능한 정점을 나타내는 행
};
vector<vector<int>> matrix = {// C++ 인접행렬 표현
{0, 0, 1},// A정점에서 이동 가능한 정점을 나타내는 행
{1, 0, 1},// B정점에서 이동 가능한 정점을 나타내는 행
{1, 0, 0}// C정점에서 이동 가능한 정점을 나타내는 행
};
matrix = [// Python 인접행렬 표현
[0, 0, 1],// A정점에서 이동 가능한 정점을 나타내는 행
[1, 0, 1],// B정점에서 이동 가능한 정점을 나타내는 행
[1, 0, 0]// C정점에서 이동 가능한 정점을 나타내는 행
]
var matrix: [[Int]] = [// Swift 인접행렬 표현
[0, 0, 1],// A정점에서 이동 가능한 정점을 나타내는 행
[1, 0, 1],// B정점에서 이동 가능한 정점을 나타내는 행
[1, 0, 0]// C정점에서 이동 가능한 정점을 나타내는 행
]
val matrix = arrayOf(// Kotlin 인접행렬 표현
intArrayOf(0, 0, 1),// A정점에서 이동 가능한 정점을 나타내는 행
intArrayOf(1, 0, 1),// B정점에서 이동 가능한 정점을 나타내는 행
intArrayOf(1, 0, 0)// C정점에서 이동 가능한 정점을 나타내는 행
)
- A의 진출차수는 1개입니다: A —> C
- [0][2] == 1
- B의 진출차수는 2개입니다: B —> A, B —> C
- [1][0] == 1
- [1][2] == 1
- C의 진출차수는 1개입니다: C —> A
- [2][0] == 1
인접 행렬은 언제 사용할까?
인접 행렬은 본질적으로 큰 표와 같은 형태로, 이는 두 개의 정점 간의 연결 여부를 확인하는데 매우 유용하게 사용됩니다. 그 예시로, A에서 B로 이동하는 경로가 있는지를 알고자 한다면, 단순히 0번째 행의 1번째 열에 저장된 값을 참조하면 됩니다. 이는 인접 행렬의 가장 간단하면서도 효과적인 특징입니다.
또한, 인접 행렬은 최단 경로 문제를 해결하고자 할 때 주로 사용됩니다. 이렇게 인접 행렬을 통해 그래프의 복잡한 구조를 쉽게 파악하고, 최적의 경로를 찾아내는 데 도움을 줍니다. 이를 통해 효율적인 데이터 분석과 정보 처리가 가능해지게 됩니다.
인접 리스트
인접 리스트는 그래프의 정점 간 연결을 리스트 형식으로 표현하는 방식입니다. 이는 각 정점이 어떤 다른 정점들과 연결되어 있는지를 알기 쉽게 해줍니다. 각 정점마다 하나의 리스트를 가지고 있으며, 이 리스트는 자신과 인접한 다른 정점을 담고 있습니다. 위 그래프를 인접 리스트로 표현하면 다음 그림과 같습니다.

[그림] 내비게이션 그래프의 인접 리스트 예시
- 위의 그래프를 인접 리스트로 다음과 같이 표현할 수 있습니다.
// Java언어로 표현한 인접 리스트// A, B, C는 각각의 인덱스로 표기합니다. 0 == A, 1 == B, 2 == C
ArrayList<ArrayList<Integer>> graph = new ArrayList<>();
graph.add(new ArrayList<>(Arrays.asList(2, null)));
graph.add(new ArrayList<>(Arrays.asList(0, 2, null)));
graph.add(new ArrayList<>(Arrays.asList(0, null)));
// graph.get(0) == [2, null] == 0 -> 2 -> null// graph.get(1) == [0, 2, null] == 1 -> 0 -> 2 -> null// graph.get(2) == [0, null] == 2 -> 0 -> null// C언어로 표현한 인접 리스트// A, B, C는 각각의 인덱스로 표기합니다. 0 == A, 1 == B, 2 == C
struct Graph* graph = createGraph(vertexCount);
// 간선 추가
addEdge(graph, 0, 2);
addEdge(graph, 1, 0);
addEdge(graph, 1, 2);
// 그래프 출력
printGraph(graph);
정점 0에 인접한 정점들: 2
정점 1에 인접한 정점들: 0 2
정점 2에 인접한 정점들: 0
// C++언어로 표현한 인접 리스트// A, B, C는 각각의 인덱스로 표기합니다. 0 == A, 1 == B, 2 == C
std::vector<std::vector<int>> graph;
graph.push_back({2, -1});
graph.push_back({0, 2, -1});
graph.push_back({0, -1});
// 그래프 출력for (int i = 0; i < graph.size(); i++) {
std::cout << "정점 " << i << "에 인접한 정점들: ";
for (int j = 0; j < graph[i].size(); j++) {
if (graph[i][j] == -1) {
std::cout << "null ";
} else {
std::cout << graph[i][j] << " ";
}
}
std::cout << std::endl;
}
정점 0에 인접한 정점들: 2
정점 1에 인접한 정점들: 0 2
정점 2에 인접한 정점들: 0
// Python언어로 표현한 인접 리스트// A, B, C는 각각의 인덱스로 표기합니다. 0 == A, 1 == B, 2 == C
graph = [
[2, None],
[0, 2, None],
[0, None]
]
# 그래프 출력
for i in range(len(graph)):
print(f"정점 {i}에 인접한 정점들:", end=" ")
for j in range(len(graph[i])):
if graph[i][j] is None:
print("null", end=" ")
else:
print(graph[i][j], end=" ")
print()
정점 0에 인접한 정점들: 2
정점 1에 인접한 정점들: 0 2
정점 2에 인접한 정점들: 0
// Swift 언어로 표현한 인접 리스트// A, B, C는 각각의 인덱스로 표기합니다. 0 == A, 1 == B, 2 == Cvar graph: [[Int]] = []
graph.append([2, -1])
graph.append([0, 2, -1])
graph.append([0, -1])
// 그래프 출력for i in 0..<graph.count {
print("정점 \\(i)에 인접한 정점들: ", terminator: "")
for j in 0..<graph[i].count {
if graph[i][j] == -1 {
print("null ", terminator: "")
} else {
print("\\(graph[i][j]) ", terminator: "")
}
}
print()
}
// Kotlin 언어로 표현한 인접리스트// A, B, C는 각각의 인덱스로 표기합니다. 0 == A, 1 == B, 2 == C
val graph: ArrayList<ArrayList<Int>> = ArrayList()
graph.add(ArrayList(listOf(2, null)))
graph.add(ArrayList(listOf(0, 2, null)))
graph.add(ArrayList(listOf(0, null)))
// graph.get(0) == ${graph[0]} == 0 -> 2 -> null// graph.get(1) == ${graph[1]} == 1 -> 0 -> 2 -> null// graph.get(2) == ${graph[2]} == 2 -> 0 -> null
B는 A와 C로 이어지는 간선이 두 개가 있는데, 왜 A가 C보다 먼저죠? 이 순서는 중요한가요?
일반적으로, 순서는 중요하지 않습니다. 각각의 자료 구조, 그래프, 트리, 스택, 큐 등은 그 사용 목적과 사용자의 편의에 따라서 어떤 요소들을 추가하거나 삭제할 수 있습니다. 인접 리스트를 이용해 그래프를 구현할 때는, 각 정점을 처리하는 우선순위를 고려할 수도 있습니다. 이 경우, 리스트에 저장된 정점들은 그 우선순위에 따라 정렬될 수 있습니다. 그러나 우선순위가 따로 정해지지 않았다면, 연결된 정점들은 단순히 나열된 형태의 리스트가 될 것입니다.
- 만약 우선순위를 고려해야 하는 상황이라면, 큐나 힙과 같은 다른 자료 구조를 사용하는 것이 더 합리적일 수 있습니다. 그래서, 일반적으로 순서는 중요하지 않다고 할 수 있습니다. (물론, 예외는 존재할 수 있습니다.)
인접 리스트는 언제 사용해야 할까요?
- 메모리 사용을 최적화하고 싶을 때, 인접 리스트를 사용하는 것이 좋습니다.
- 인접 행렬은 모든 가능한 연결을 저장하므로, 메모리 사용량이 높게 나타날 수 있습니다. 반면, 인접 리스트는 실제 연결만을 저장하기 때문에 메모리 사용이 더 효율적입니다.
그래프의 기본 연산
- 정점 추가: 그래프에 새로운 정점을 추가하는 연산입니다.
- 간선 추가: 그래프에 두 정점을 연결하는 간선을 추가하는 연산입니다.
- 정점 제거: 그래프에서 특정 정점을 제거하는 연산입니다. 동시에 해당 정점과 연결된 모든 간선도 제거됩니다.
- 간선 제거: 그래프에서 두 정점을 연결하는 간선을 제거하는 연산입니다.
- 정점 탐색: 그래프에서 특정 정점을 찾는 연산입니다.
- 간선 탐색: 그래프에서 두 정점을 연결하는 간선을 찾는 연산입니다.
- 인접 정점 탐색: 그래프에서 특정 정점과 인접한 정점들을 찾는 연산입니다.
- 그래프 순회: 그래프의 모든 정점을 방문하는 연산입니다. 일반적으로 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)이 사용됩니다.