
Thread Pool
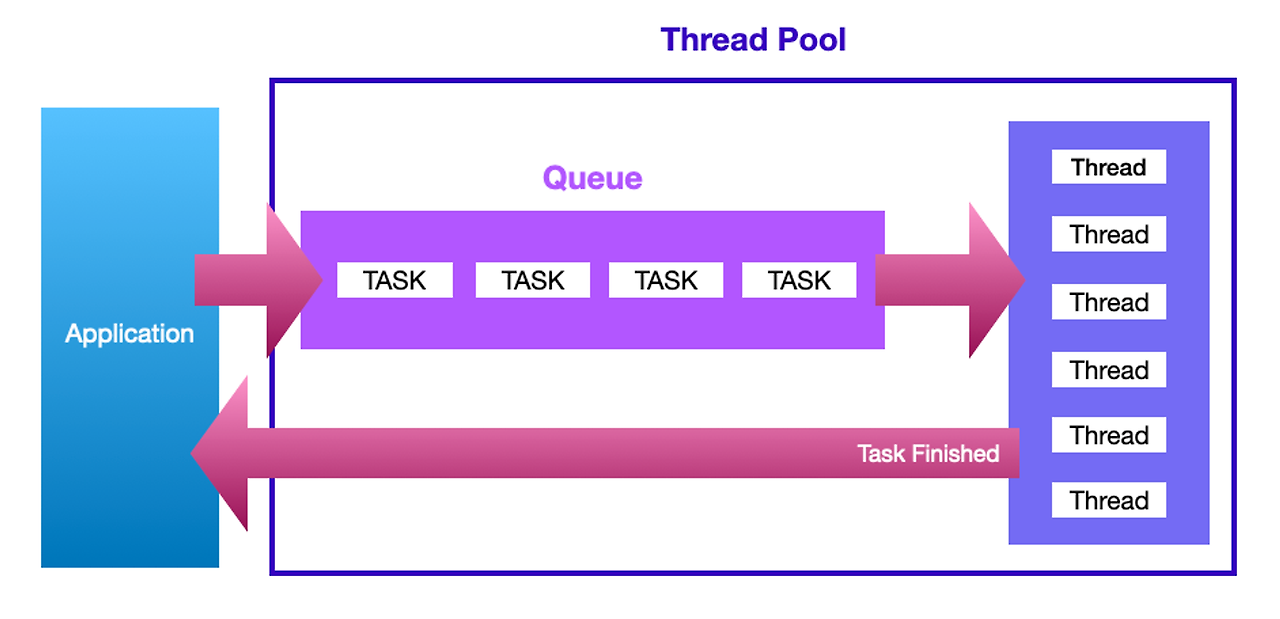
동시 작업 처리가 많아지만 스레드 수가 증가하고 스래드 생성과 스케줄링으로 인해 메모리 사용량이 늘어나면서 애플리케이션의 성능을 저하시킵니다. 스레드의 무분별한 증가를 방지하려면 스레드풀을 사용해야합니다. 스레드풀은 작업 처리에 사용되는 스레드의 수를 정해 놓습니다. 큐에 들어오는 작업이 들어오면 스레드풀 안에 스레드가 하나씩 맡아서 처리합니다. 작업 처리가 끝난 스레드는 작업 큐의 새로운 작업을 처리합니다.
아래 그림을 통해서 대략적인 흐름을 확인해보도록 합시다.
스레드풀 생성
ExecutorService(스레드 풀) 구현객체는 Executors 클래스 메서드로 생성할 수 있습니다.

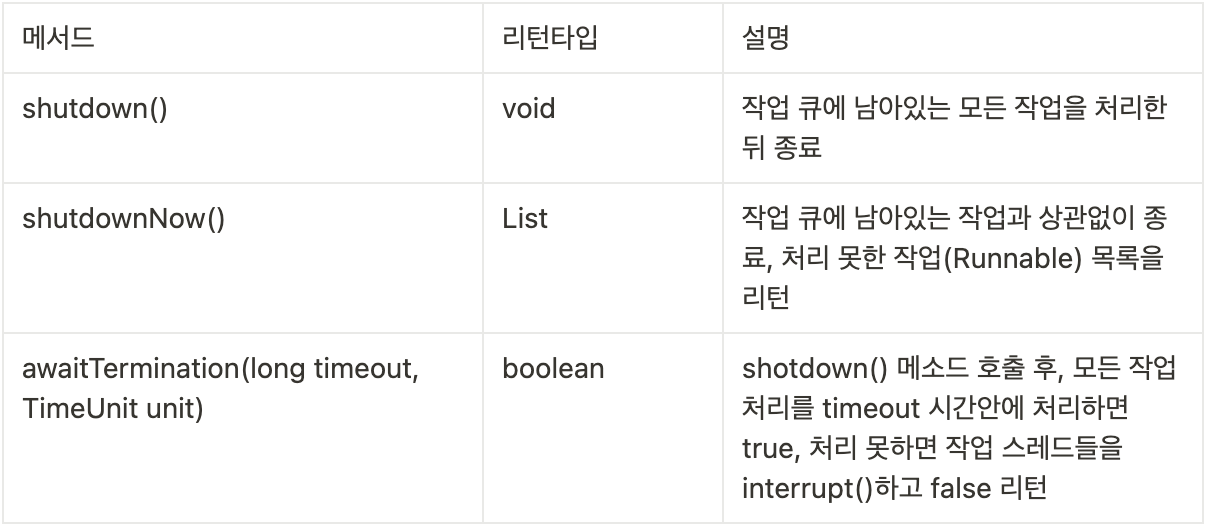
스레드풀 종료
스레드풀은 main 스레드가 종료되어도 작업을 처리하기 위해 계속 실행 상태로 남아있습니다. 애플리케이션을 종료하기 위해서는 스레드풀을 종료해야 합니다.
스레드풀 예시코드
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
public class Main {
public static void main(String[] args) {
//최대 6개의 스레드를 가진 스레드풀 생성
ExecutorService executorService = Executors.newFixedThreadPool(6);
for(int i = 0; i < 10; i++){
Runnable runnable = new Runnable() {
@Override
public void run() {
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executorService;
//스레드풀 갯수 확인
int poolSize = threadPoolExecutor.getPoolSize();
//스레드 풀에 있는 해당 스레드이름 확인
String threadName = Thread.currentThread().getName();
System.out.println("스레드풀 갯수:" + poolSize + "스레드 이름: "+threadName);
}
};
//스레드풀 작업 처리 요청
executorService.execute(runnable);
//executorService.submit(runnable);
//콘솔 출력을 위해 main스레드에 10ms sleep을 걸어둠.
try {
Thread.sleep(10);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//스레드풀 종료
executorService.shutdown();
}
}(Optional) 스레드의 상태와 실행 제어
앞서, [스레드의 생성과 실행]에서, 스레드를 생성한 후에 실행시키기 위해서는 start() 메서드를 호출해야 한다고 했습니다.
하지만, 엄밀히 말하면 start()는 스레드를 실행시키는 메서드는 아닙니다.
start()는 스레드의 상태를 실행 대기 상태로 만들어주는 메서드이며, 어떤 스레드가 start()에 의해 실행 대기 상태가 되면 운영체제가 적절한 때에 스레드를 실행시켜 줍니다.
여기에서 알 수 있는 사실은 다음과 같습니다.
- start()는 스레드를 실행 대기 상태로 만들어준다.
- 즉, 스레드에는 상태라는 것이 존재한다.
- 또한, 스레드의 상태를 바꿀 수 있는 메서드가 존재한다.
이 콘텐츠에서는 스레드의 상태와 스레드의 상태를 제어하는 메서드에 대해 학습합니다.
스레드의 상태와 실행 제어 메서드 요약
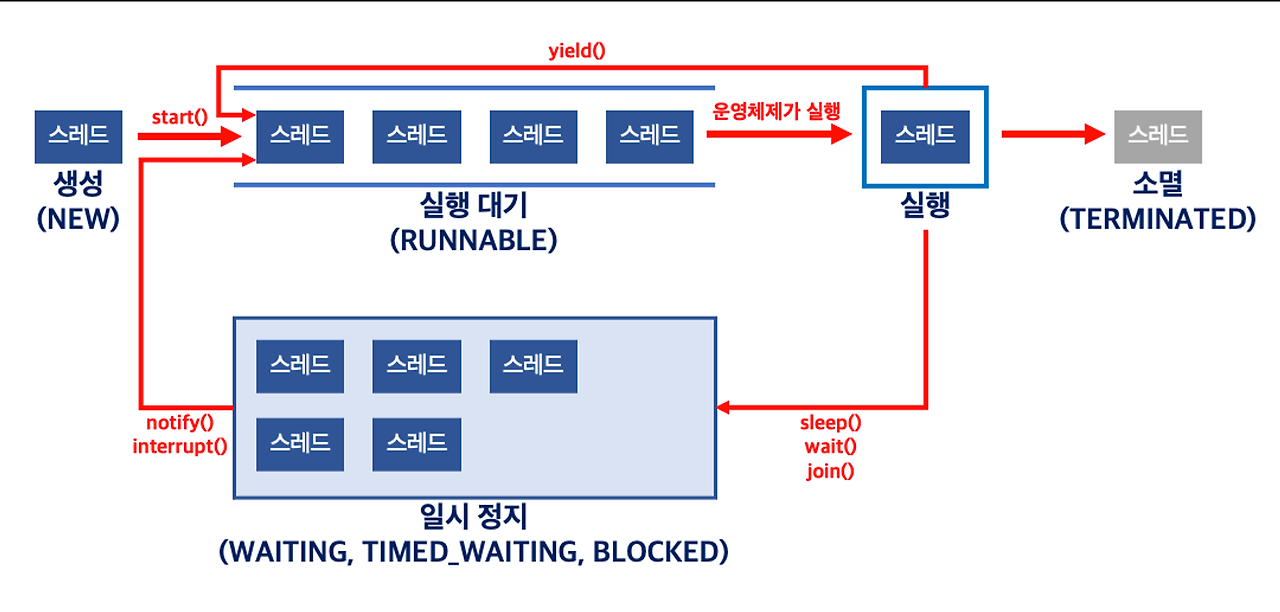
스레드 실행 제어 메서드
sleep(long milliSecond) : milliSecond 동안 스레드를 잠시 멈춥니다.
static void sleep(long milliSecond)
sleep()은 스레드의 실행을 잠시 멈출 때 사용합니다. 인자로 얼마나 스레드를 멈출 것인지 설정할 수 있으나, 항상 지정한 시간만큼 정확히 스레드가 중지되는 것은 아니며 약간의 오차를 가집니다.
위의 메서드 시그니처에서 확인할 수 있듯, sleep()은 Thread의 클래스 메서드입니다. 따라서 sleep()을 호출할 때는 Thread.sleep(1000);과 같이 클래스를 통해서 호출하는 것이 권장됩니다.
sleep()을 호출하면 sleep()을 호출하는 코드를 실행한 스레드의 상태가 실행 상태에서 일시 정지(TIMED_WAITING) 상태로 전환됩니다.
sleep()에 의해 일시 정지된 스레드는 다음의 경우에 실행 대기 상태로 복귀합니다.
- 인자로 전달한 시간만큼의 시간이 경과한 경우
- interrupt()를 호출한 경우
위의 두 가지 경우 중 interrupt()를 호출하여 스레드를 실행 대기 상태로 복귀시키고자 한다면 반드시 try … catch 문을 사용해서 예외 처리를 해주어야 합니다. 아래에서 설명할 예정이지만 간단하게 미리 설명하자면, interrupt()가 호출되면 기본적으로 예외가 발생하기 때문입니다.
따라서 sleep()을 사용할 때는 아래처럼 try … catch 문으로 sleep()을 감싸주어야 합니다.
try { Thread.sleep(1000); } catch (Exception error) {}
interrupt() : 일시 중지 상태인 스레드를 실행 대기 상태로 복귀시킵니다.
void interrupt()
interrupt()는 sleep(), wait(), join()에 의해 일시 정지 상태에 있는 스레드들을 실행 대기 상태로 복귀시킵니다.
sleep(), wait(), join()에 의해 일시 정지된 스레드들의 코드 흐름은 각각 sleep(), wait(), join()에 멈춰있습니다.
멈춰있는 스레드가 아닌 다른 스레드에서 멈춰 있는 스레드.interrupt()를 호출하면, 기존에 호출되어 스레드를 멈추게 했던 sleep(), wait(), join() 메서드에서 예외가 발생하며, 그에 따라 일시 정지가 풀리게 됩니다.
아래 예제를 통해 스레드의 상태 변화를 확인해 보세요.
public class ThreadExample5 {
public static void main(String[] args) {
Thread thread1 = new Thread() {
public void run() {
try {
while (true) Thread.sleep(1000);
}
catch (Exception e) {}
System.out.println("Woke Up!!!");
}
};
System.out.println("thread1.getState() = " + thread1.getState());
thread1.start();
System.out.println("thread1.getState() = " + thread1.getState());
while (true) {
if (thread1.getState() == Thread.State.TIMED_WAITING) {
System.out.println("thread1.getState() = " + thread1.getState());
break;
}
}
thread1.interrupt();
while (true) {
if (thread1.getState() == Thread.State.RUNNABLE) {
System.out.println("thread1.getState() = " + thread1.getState());
break;
}
}
while (true) {
if (thread1.getState() == Thread.State.TERMINATED) {
System.out.println("thread1.getState() = " + thread1.getState());
break;
}
}
}
}
출력 결과는 다음과 같습니다.
/Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home/bin/java -javaagent:/Users/0hyun.cho/Library/Application Support/JetBrains/Toolbox/apps/IDEA-C/ch-0/221.5080.210/IntelliJ IDEA CE.app/Contents/lib/idea_rt.jar=53048:/Users/0hyun.cho/Library/Application Support/JetBrains/Toolbox/apps/IDEA-C/ch-0/221.5080.210/IntelliJ IDEA CE.app/Contents/bin -Dfile.encoding=UTF-8 -classpath /Users/0hyun.cho/study/example/out/production/classes ThreadExample5
thread1.getState() = NEW
thread1.getState() = RUNNABLE
thread1.getState() = TIMED_WAITING
Woke Up!!!
thread1.getState() = RUNNABLE
thread1.getState() = TERMINATED
Process finished with exit code 0
출력 결과를 보면, sleep()에 의해 일시 정지(TIMED_WAITING) 상태가 되었다가 interrupt()에 의해 다시 RUNNABLE로 상태가 변화한 것을 확인할 수 있습니다.
이후 해당 스레드는 run()의 마지막 코드인 println()을 실행한 뒤에 종료되어 TERMINATE 상태가 됩니다.
예제에서 interrupt()가 호출되면 코드의 흐름은 다음과 같이 흘러갑니다.

yield() : 다른 스레드에 실행을 양보합니다.
static void yield()
yield()는 다른 스레드에 자신의 실행 시간을 양보합니다. 예를 들어, 운영 체제의 스케줄러에 의해 3초를 할당받은 스레드 A가 1초 동안 작업을 수행하다가 yield()를 호출하면 남은 실행 시간 2초는 다음 스레드에 양보됩니다.
스레드를 활용할 때, 스레드에 반복적인 작업을 실행시키는 경우가 많습니다. 그런데 특정 경우에 반복문의 순회가 불필요할 때가 있습니다.
예를 들어 다음과 같이 코드가 작성되어 있을 때, example의 값이 false라면 스레드는 while문의 반복이 불필요함에도 계속해서 반복시킵니다.
public void run() {
while (true) {
if (example) {
...
}
}
}
이러한 경우에 yield()를 유용하게 활용할 수 있습니다. 아래처럼 어떤 스레드가 yield()를 호출하면 example의 값이 false일 때에 무의미한 while문의 반복을 멈추고 실행 대기 상태로 바뀌며, 자신에게 남은 실행 시간을 실행 대기열 상 우선순위가 높은 다른 스레드에 양보합니다.
public void run() {
while (true) {
if (example) {
...
}
else Thread.yield();
}
}
join() : 다른 스레드의 작업이 끝날 때까지 기다립니다.
void join()
void join(long milliSecond)
join()은 특정 스레드가 작업하는 동안에 자신을 일시 중지 상태로 만드는 상태 제어 메서드입니다.
인자로 시간을 밀리초 단위로 전달할 수 있으며, 전달한 인자만큼의 시간이 흐르거나, interrupt()가 호출되거나, join() 호출 시 지정했던 다른 스레드가 모든 작업을 마치면 다시 실행 대기 상태로 복귀합니다.
join()은 다음과 같은 측면에서 sleep()과 유사합니다.
- join()을 호출한 스레드는 일시 중지 상태가 됩니다.
- try … catch 문으로 감싸서 사용해야 합니다.
- interrupt()에 의해 실행 대기 상태로 복귀할 수 있습니다.
그러나 sleep()과 join()은 다음과 같은 차이점을 가집니다.
- sleep()은 Thread 클래스의 static 메서드입니다. 반면, join()은 특정 스레드에 대해 동작하는 인스턴스 메서드입니다.
- 예 : Thread.sleep(1000);
- 예 : thread1.join();
public class ThreadExample {
public static void main(String[] args) {
SumThread sumThread = new SumThread();
sumThread.setTo(10);
sumThread.start();
// 메인 스레드가 sumThread의 작업이 끝날 때까지 기다립니다.
try { sumThread.join(); } catch (Exception e) {}
System.out.println(String.format("1부터 %d까지의 합 : %d", sumThread.getTo(), sumThread.getSum()));
}
}
class SumThread extends Thread {
private long sum;
private int to;
public long getSum() {
return sum;
}
public int getTo() {
return to;
}
public void setTo(int to) {
this.to = to;
}
public void run() {
for (int i = 1; i <= to; i++) {
sum += i;
}
}
}
wait(), notify() : 스레드 간 협업에 사용됩니다.
스레드를 활용하다 보면, 두 스레드가 교대로 작업을 처리해야 할 때가 있습니다. 이때 사용할 수 있는 상태 제어 메서드가 바로 wait()과 notify()입니다.
스레드A와 스레드B가 공유 객체를 두고 협업하는 상황을 가정해 봅시다. 스레드 간 협업은 아래의 플로우로 진행됩니다.
먼저, 스레드A가 공유 객체에 자신의 작업을 완료합니다. 이때, 스레드B와 교대하기 위해 notify()를 호출합니다. notify()가 호출되면 스레드B가 실행 대기 상태가 되며, 곧 실행됩니다. 이어서 스레드A는 wait()을 호출하며 자기 자신을 일시 정지 상태로 만듭니다.
이후 스레드B가 작업을 완료하면 notify()를 호출하여 작업을 중단하고 있던 스레드A를 다시 실행 대기 상태로 복귀시킨 후, wait()을 호출하여 자기 자신의 상태를 일시 정지 상태로 전환합니다.
이와 같은 과정이 반복되면서, 두 스레드는 공유 객체에 대해 서로 배타적으로 접근하면서도 효과적으로 협업할 수 있습니다.
아래 예제를 직접 입력해 보고 실행하면서 맥락을 파악해 보세요.
public class ThreadExample5 {
public static void main(String[] args) {
WorkObject sharedObject = new WorkObject();
ThreadA threadA = new ThreadA(sharedObject);
ThreadB threadB = new ThreadB(sharedObject);
threadA.start();
threadB.start();
}
}
class WorkObject {
public synchronized void methodA() {
System.out.println("ThreadA의 methodA Working");
notify();
try { wait(); } catch(Exception e) {}
}
public synchronized void methodB() {
System.out.println("ThreadB의 methodB Working");
notify();
try { wait(); } catch(Exception e) {}
}
}
class ThreadA extends Thread {
private WorkObject workObject;
public ThreadA(WorkObject workObject) {
this.workObject = workObject;
}
public void run() {
for(int i = 0; i < 10; i++) {
workObject.methodA();
}
}
}
class ThreadB extends Thread {
private WorkObject workObject;
public ThreadB(WorkObject workObject) {
this.workObject = workObject;
}
public void run() {
for(int i = 0; i < 10; i++) {
workObject.methodB();
}
}
}자바 가상 머신(Java Virtual Machine)
“Write Once, Run Anywhere”

자바가 탄생하기 이전에는 C++ 이 프로그래밍 언어로 많이 사용되고 있었습니다. C++은 C언어를 기반으로 한 유명한 객체지향 프로그래밍 언어입니다. 그런데, 당시 C++에 큰 문제가 하나 있었습니다.
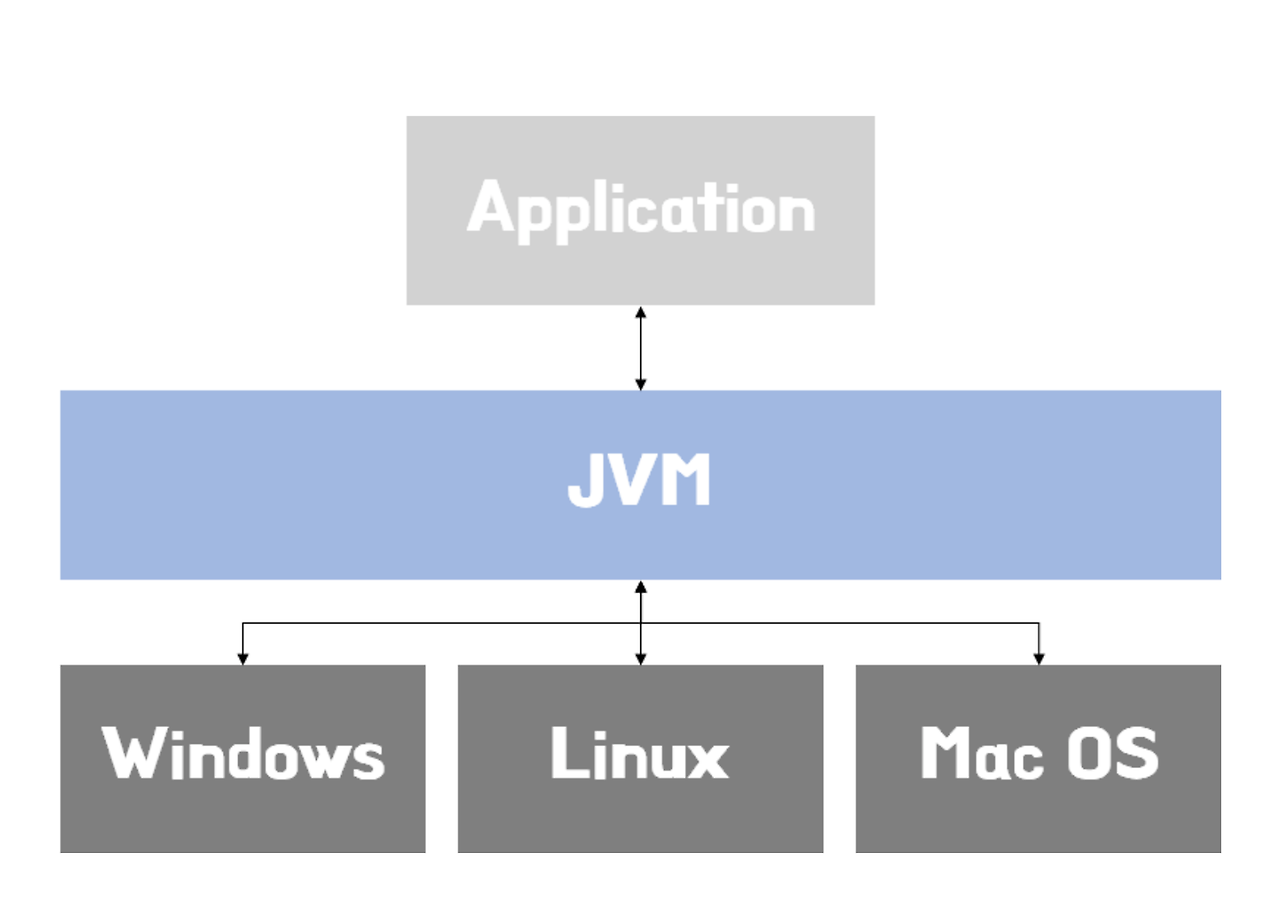
바로 운영체제로부터 독립적이지 못하다는 점입니다. 쉽게 말해, Windows를 위해 만든 프로그램은 Windows에서만 작동할 수 있었고, Mac OS에서 그 프로그램을 실행시키려면 Mac OS에 맞게 새로 프로그램을 만들고 컴파일해야 했습니다. 즉, 프로그래밍 언어가 운영체제에 종속적이기 때문에, 어떤 프로그램을 만들 때 운영체제 별로 따로 만들어주어야 했습니다.
자바는 이러한 문제점을 해결하고자 탄생한 언어입니다. 자바는 C++처럼 객체지향 프로그래밍이 가능하면서도, 운영체제로부터 독립되어 있으므로, 자바로 소스 코드를 한 번만 작성하면 어떤 운영체제에서도 코드를 수정할 필요 없이 프로그램을 실행시킬 수 있습니다. 이와 같은 운영체제로부터의 독립성은 JVM이라는 별도의 프로그램을 통해서 구현됩니다. 이제, JVM이 무엇인지 좀 더 공부해 봅시다.
학습 목표
- JVM이 무엇인지 이해한다.
- JVM의 메모리 구조를 개괄적으로 이해한다.
- 가비지 컬렉션이 무엇인지 이해한다.
JVM이란?
JVM(Java Virtual Machine)은 자바 프로그램을 실행시키는 도구입니다. 즉, JVM은 자바로 작성한 소스 코드를 해석해 실행하는 별도의 프로그램입니다.
개요에서 자바는 운영체제로부터 독립적이라고 했습니다. 이러한 자바의 독립성은 JVM을 통해 구현되는데, 이유는 다음과 같습니다.
먼저, 프로그램이 실행되기 위해서는 CPU, 메모리, 각종 입출력 장치 등과 같은 컴퓨터 자원을 프로그램이 할당받아야 합니다.
프로그램이 자신이 필요한 컴퓨터 자원을 운영체제에게 주문하면, 운영체제는 가용한 자원을 확인한 다음, 프로그램이 실행되는 데에 필요한 컴퓨터 자원을 프로그램에게 할당해 줍니다.
이때, 프로그램이 운영체제에게 필요한 컴퓨터 자원을 요청하는 방식이 운영체제마다 다릅니다. 이것이 바로 프로그래밍 언어가 운영체제에 대해 종속성을 가지게 되는 이유입니다.
하지만 자바는 JVM을 매개해서 운영체제와 소통합니다. 즉, JVM이 자바 프로그램과 운영체제 사이에서 일종의 통역가 역할을 수행합니다.
JVM은 각 운영체제에 적합한 버전이 존재합니다. 즉, Windows용 JVM, Mac OS용 JVM, Linux용 JVM이 따로 존재합니다.
이처럼 운영체제에 맞게 JVM이 개발되어 있으며, JVM은 자바 소스 코드를 운영 체제에 맞게 변환해 실행시켜 줍니다. 이것이 자바가 운영체제로부터 독립적으로 동작할 수 있는 이유입니다.
JVM 구조
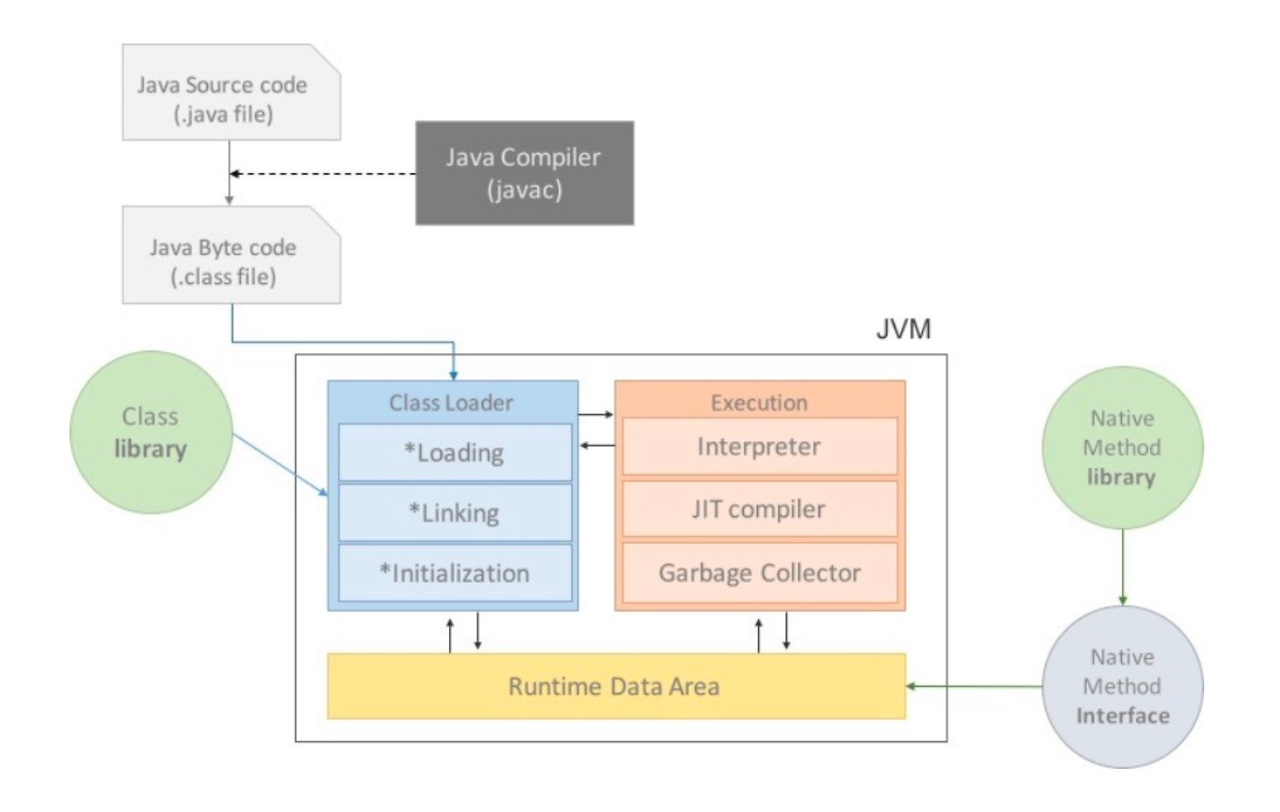
JVM의 내부 구조는 위 그림과 같습니다.
자바로 소스 코드를 작성하고 실행하면 어떤 일이 일어나는지 위 그림을 통해 가볍게 이해해 봅시다.
여러분이 자바로 소스 코드를 작성하고 실행하면, 먼저 컴파일러가 실행되면서 컴파일이 진행됩니다. 컴파일의 결과로 .java 확장자를 가졌던 자바 소스 코드가 .class 확장자를 가진 바이트 코드 파일로 변환됩니다.
이후, JVM은 운영 체제로부터 소스 코드 실행에 필요한 메모리를 할당받습니다. 그것이 바로 위 그림 상의 런타임 데이터 영역(Rumtime Data Area)입니다.
그다음에는 클래스 로더(Class Loader)가 바이트 코드 파일을 JVM 내부로 불러들여 런타임 데이터 영역에 적재시킵니다. 자바 소스 코드를 메모리에 로드시키는 것이죠.
로드가 완료되면 이제 실행 엔진(Execution Engine)이 런타임 데이터 영역에 적재된 바이트 코드를 실행시킵니다.
이때, 실행 엔진은 두 가지 방식으로 바이트 코드를 실행시킵니다.
- 인터프리터(Interpreter)를 통해 코드를 한 줄씩 기계어로 번역하고 실행시키기
- JIT Compiler(Just-In-Time Compiler)를 통해 바이트 코드 전체를 기계어로 번역하고 실행시키기
실행 엔진은 기본적으로 1번의 방법을 통해 바이트 코드를 실행시키다가, 특정 바이트 코드가 자주 실행되면 해당 바이트 코드를 JIT Compiler를 통해 실행시킵니다.
즉, 중복적으로 어떤 바이트 코드가 등장할 때, 인터프리터는 매번 해당 바이트 코드를 해석하고 실행하지만, JIT 컴파일러가 동작하면 한 번에 바이트 코드를 해석하고 실행시킵니다.
Stack과 Heap
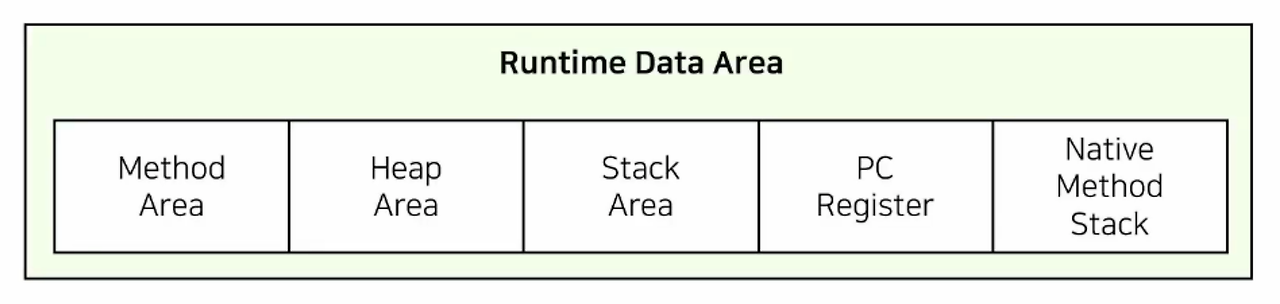
JVM에 Java 프로그램이 로드되어 실행될 때 특정 값 및 바이트코드, 객체, 변수 등과 같은 데이터들이 메모리에 저장되어야 합니다. 런타임 데이터 영역이 바로 이러한 정보를 담는 메모리 영역이며, 크게 5가지 영역으로 구분되어 있습니다.
이 가운데 우리는 두 가지 영역, Heap과 Stack만을 살펴보겠습니다. 나머지 부분들은 추후 공부해 보시기를 권해드립니다.
Stack 영역이란?
스택은 일종의 자료구조입니다. 자료구조는 프로그램이 데이터를 저장하는 방식을 의미합니다. “프로그램이 데이터를 저장하는 방식은 여러 가지가 있는데, 그 저장 방식 중의 하나가 스택이구나” 정도로 이해해 주세요.
이러한 스택은 흔히 LIFO라는 키워드로 설명됩니다. LIFO는 “Last In First Out”의 약자로, 직역하면 마지막에 들어간 데이터가 가장 먼저 나온다는 의미입니다. 아래 프링글스로 예를 들어 스택을 설명해 보겠습니다.

바로 프링글스의 포장 방식이 완벽한 스택의 형태를 취하고 있습니다. 여러분이 프링글스를 열고 감자칩을 꺼낼 때, 맨 아래에 있는 칩을 먼저 꺼낼 수 있나요? 밑면을 뜯지 않는 이상, 일반적인 방법으로는 불가능합니다.
이처럼 맨 마지막에 들어온 데이터가 가장 먼저 나가는 자료 구조를 스택이라고 하며, LIFO는 이러한 스택의 데이터 입출력 순서를 나타내는 원칙입니다.
그렇다면 JVM안에서 Stack은 어떻게 작동할까요?
메서드가 호출되면 그 메서드를 위한 공간인 Method Frame이 생성됩니다. 메서드 내부에서 사용하는 다양한 값들이 있는데 참조변수, 매개변수, 지역변수, 리턴값 및 연산 시 일어나는 값들이 임시로 저장됩니다.
이런 Method Frame이 Stack에 호출되는 순서대로 쌓이게 되는데, Method의 동작이 완료되면 역순으로 제거됩니다.
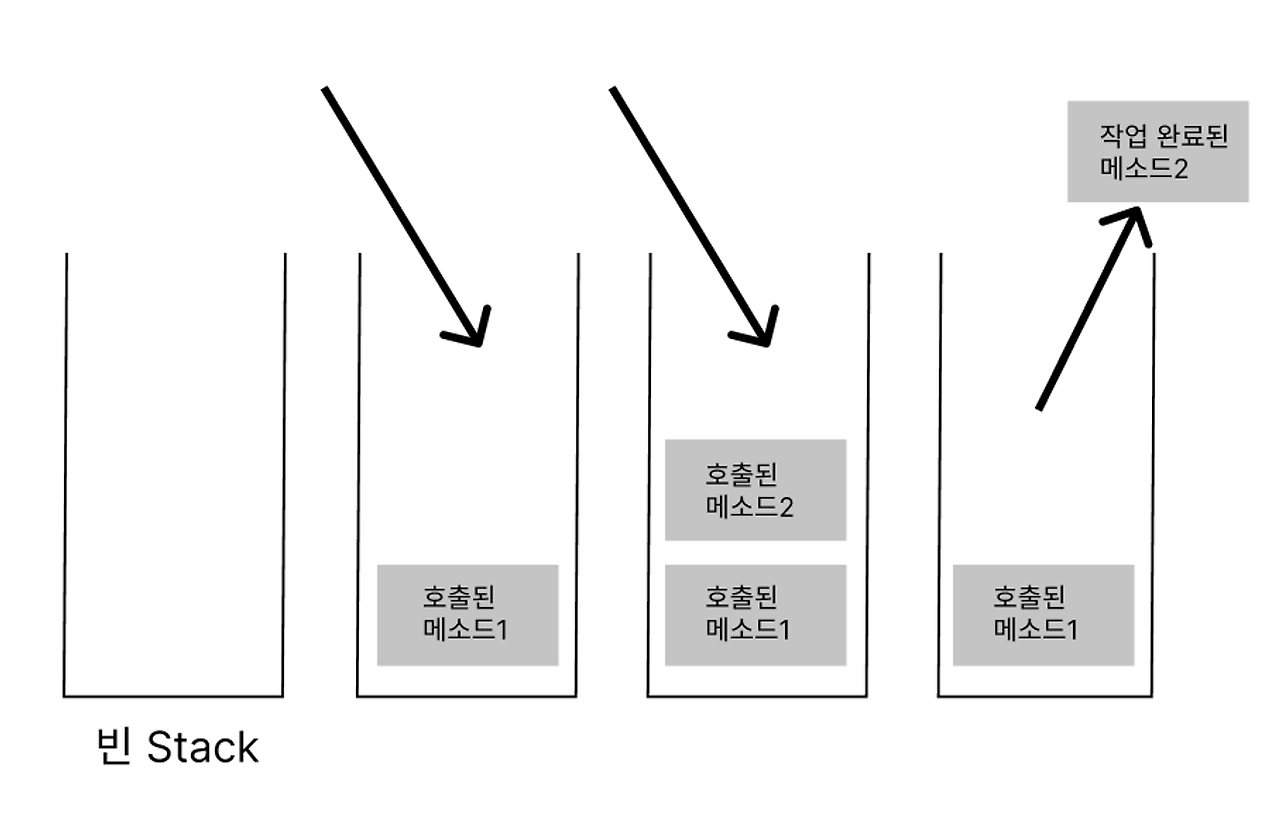
이 영역의 동작 원리를 더 자세히 이해하려면 Heap영역에 대해 이해해야 합니다.
Heap 영역이란?
JVM에는 단 하나의 Heap 영역이 존재합니다. JVM이 작동되면 이 영역은 자동 생성됩니다. 그리고 이 영역 안에 객체나 인스턴스 변수, 배열이 저장됩니다.
우리는 앞서서 인스턴트를 생성하는 방법을 주제로 학습했습니다.
Person person = new Person();
위의 예시에서 new Person()이 실행되면 Heap 영역에 인스턴스가 생성되며, 인스턴스가 생성된 위치의 주소값을 person에게 할당해 주는데, 이 person은 Stack 영역에 선언된 변수입니다.
즉, 우리가 객체를 다룬다는 것은 Stack 영역에 저장되어 있는 참조 변수를 통해 Heap 영역에 존재하는 객체를 다룬다는 의미가 됩니다. 정리하자면, Heap 영역은 실제 객체의 값이 저장되는 공간입니다.

Garbage Collection
Garbage Collection이란?
자바에서는 가비지 컬렉션이라는 메모리를 자동으로 관리하는 프로세스가 포함되어 있습니다. 가비지 컬렉션은 프로그램에서 더 이상 사용하지 않는 객체를 찾아 삭제하거나 제거하여 메모리를 확보하는 것을 의미합니다.
아래 코드를 살펴봅시다.
Person person = new Person();
person.setName("김코딩");
person = null;
// 가비지 발생
person = new Person();
person.setName("박해커");
위의 예시 첫째 줄에서 참조 변수 person은 Person 클래스의 인스턴스의 주소값을 할당받고, 이어서 “김코딩”이라는 문자열이 person이 가리키는 인스턴스의 name이라는 속성에 할당됩니다.
그런데, 세 번째 줄에서 참조 변수 person에 null이 할당됨으로써, 기존에 person이 가리키던 인스턴스와 참조변수 person 간의 연결이 끊어졌습니다.
프로그램이 실행 중일 때 이처럼 아무도 인스턴스를 참조하고 있지 않다면, 더 이상 메모리에 person이 가리키던 인스턴스가 존재해야 할 이유가 없습니다.
가비지 컬렉터는 이렇게 아무한테도 참조되고 있지 않은 객체 및 변수들을 검색하여 메모리에서 점유를 해제하며, 그럼으로써 메모리 공간을 확보하여 효율적으로 메모리를 사용할 수 있게 해 줍니다.
동작 방식
가비지 컬렉션의 동작 방식을 이해하려면 앞서 배운 Heap 메모리 영역에 대한 이해가 필요합니다.
JVM의 Heap 영역은 객체는 대부분 일회성이며, 메모리에 남아 있는 기간이 대부분 짧다는 전제로 설계되어 있습니다.
그러므로 객체가 얼마나 살아있냐에 따라서 Heap 영역 안에서도 영역을 나누게 되는데 Young, Old영역 이렇게 2가지로 나뉩니다.

Young 영역에서는 새롭게 생성된 객체가 할당되는 곳이고 여기에는 많은 객체가 생성되었다 사라지는 것을 반복합니다.
이 영역에서 활동하는 가비지 컬렉터를 Minor GC라고 부릅니다.
Old 영역에서는 Young영역에서 상태를 유지하고 살아남은 객체들이 복사되는 곳으로 보통 Young 영역보다 크게 할당되고 크기가 큰 만큼 가비지는 적게 발생합니다.
이 영역에서 활동하는 가비지 컬렉터를 Major GC라고 부릅니다.
Young 영역과 Old 영역은 서로 다른 메모리 구조로 되어 있으므로, 세부적인 동작 방식은 다르지만, 기본적으로 가비지 컬렉션이 실행될 때는 다음의 2가지 단계를 따릅니다.
- Stop The World가비지 컬렉션이 실행될 때 가비지 컬렉션을 실행하는 스레드를 제외한 모든 스레드의 작업은 중단되고, 가비지 정리가 완료되면 재개됩니다.
- Stop The World는 가비지 컬렉션을 실행시키기 위해 JVM이 애플리케이션의 실행을 멈추는 작업입니다.
- Mark and Sweep
- Mark는 사용되는 메모리와 사용하지 않는 메모리를 식별하는 작업을 의미하며, Sweep은 Mark단계에서 사용되지 않음으로 식별된 메모리를 해제하는 작업을 의미합니다.
즉, Stop The World를 통해 모든 작업이 중단되면, 가비지 컬렉션이 모든 변수와 객체를 탐색해서 각각 어떤 객체를 참고하고 있는지 확인합니다.
이후, 사용되고 있는 메모리를 식별해서(Mark) 사용되지 않는 메모리는 제거(Sweep)하는 과정을 진행합니다.
심화 실습 - 치킨의 민족 프로그램(객체지향)
[실습] 개요
🐓 치킨의 민족 프로그램 만들기
COVID-19로 인해 대다수의 인구가 외부 활동을 멈췄으며, 이에 따라 외식산업은 배달과 포장이라는 개념으로 발전하기 시작했습니다. 더불어 소비자들도 리뷰와 별점을 기준으로 주문을 진행하는 빈도수 가 증가하였습니다. 이번 **예제**는 **가게 등록**과 메뉴 등록 그리고 소비자의 별점 등을 입력받는 프로그램을 제작해 보도록 하겠습니다.
(※ 본 프로그램은 다수의 파일 분할과 다수의 메서드 정의가 진행될 예정입니다.)
🖥 [치킨의 민족 프로그램] 출력 예시
🚨 해당 프로그램의 출력 예시 중 >>> 는 사용자가 입력한 값을 의미합니다.
[치킨의 민족 프로그램 V1]
-------------------------
1) [사장님 용] 음식점 등록하기
2) [고객님과 사장님 용] 음식점 별점 조회하기
3) [고객님 용] 음식 주문하기
4) [고객님 용] 별점 등록하기
5) 프로그램 종료하기
-------------------------
[시스템] 무엇을 도와드릴까요?
>>> 1
[안내] 반갑습니다. 가맹주님!
[안내] 음식점 상호는 무엇인가요?
>>> 노랑 통닭
[안내] 대표 메뉴 이름은 무엇인가요?
>>> 노랑 치킨
[안내] 해당 메뉴 가격은 얼마인가요?
>>> 15000
[안내] 노랑 통닭에 음식(노랑 치킨, 15000) 추가되었습니다.
[시스템] 가게 등록이 정상 처리되었습니다.
[치킨의 민족 프로그램 V1]
-------------------------
1) [사장님 용] 음식점 등록하기
2) [고객님과 사장님 용] 음식점 별점 조회하기
3) [고객님 용] 음식 주문하기
4) [고객님 용] 별점 등록하기
5) 프로그램 종료하기
-------------------------
[시스템] 무엇을 도와드릴까요?
>>> 3
[안내] 고객님! 메뉴 주문을 진행하겠습니다!
[안내] 주문자 이름을 알려주세요!
>>> 이재화
[안내] 주문할 음식점 상호는 무엇인가요?
>>> 노랑 통닭
[안내] 주문할 메뉴 이름을 알려주세요!
>>> 노랑 치킨
[안내] 이재화님!
[안내] 노랑 통닭 매장에 노랑 치킨 주문이 완료되었습니다.
[치킨의 민족 프로그램 V1]
-------------------------
1) [사장님 용] 음식점 등록하기
2) [고객님과 사장님 용] 음식점 별점 조회하기
3) [고객님 용] 음식 주문하기
4) [고객님 용] 별점 등록하기
5) 프로그램 종료하기
-------------------------
[시스템] 무엇을 도와드릴까요?
>>> 4
[안내] 고객님! 별점 등록을 진행합니다.
[안내] 주문자 이름은 무엇인가요?
>>> 이재화
[안내] 음식점 상호는 무엇인가요?
>>> 노랑 통닭
[안내] 주문하신 음식 이름은 무엇인가요?
>>> 노랑 치킨
[안내] 음식 맛은 어떠셨나요? (1점 ~ 5점)
>>> 5
[안내] 리뷰 등록이 완료되었습니다.
[치킨의 민족 프로그램 V1]
-------------------------
1) [사장님 용] 음식점 등록하기
2) [고객님과 사장님 용] 음식점 별점 조회하기
3) [고객님 용] 음식 주문하기
4) [고객님 용] 별점 등록하기
5) 프로그램 종료하기
-------------------------
[시스템] 무엇을 도와드릴까요?
>>> 2
이재화 [고객님]
-------------------------
주문 매장 : 노랑 통닭
주문 메뉴 : 노랑 치킨
별점 : ★★★★★
[치킨의 민족 프로그램 V1]
-------------------------
1) [사장님 용] 음식점 등록하기
2) [고객님과 사장님 용] 음식점 별점 조회하기
3) [고객님 용] 음식 주문하기
4) [고객님 용] 별점 등록하기
5) 프로그램 종료하기
-------------------------
[시스템] 무엇을 도와드릴까요?
>>> 4
[안내] 고객님! 별점 등록을 진행합니다.
[안내] 주문자 이름은 무엇인가요?
>>> 이재화
[안내] 음식점 상호는 무엇인가요?
>>> 빨간 통닭
[안내] 주문하신 음식 이름은 무엇인가요?
>>> 빨간 치킨
[안내] 음식 맛은 어떠셨나요? (1점 ~ 5점)
>>> 3
[안내] 리뷰 등록이 완료되었습니다.
[치킨의 민족 프로그램 V1]
-------------------------
1) [사장님 용] 음식점 등록하기
2) [고객님과 사장님 용] 음식점 별점 조회하기
3) [고객님 용] 음식 주문하기
4) [고객님 용] 별점 등록하기
5) 프로그램 종료하기
-------------------------
[시스템] 무엇을 도와드릴까요?
>>> 2
이재화 [고객님]
-------------------------
주문 매장 : 노랑 통닭
주문 메뉴 : 노랑 치킨
별점 : ★★★★★
이재화 [고객님]
-------------------------
주문 매장 : 빨간 통닭
주문 메뉴 : 빨간 치킨
별점 : ★★★
[치킨의 민족 프로그램 V1]
-------------------------
1) [사장님 용] 음식점 등록하기
2) [고객님과 사장님 용] 음식점 별점 조회하기
3) [고객님 용] 음식 주문하기
4) [고객님 용] 별점 등록하기
5) 프로그램 종료하기
-------------------------
[시스템] 무엇을 도와드릴까요?
>>> 5
[안내] 이용해주셔서 감사합니다.
💡 [치킨집 사장님]께서 보내주신 프로그래밍 요청서
✏️ [치킨집을 위한 프로그램 기능]본 프로그램은 아래와 같이 네 가지 기능을 추가해 주세요.
1. 매장명, 대표 메뉴, 해당 메뉴 가격 등록2. 매장 별점 조회3. 메뉴 주문4. 별점 등록
🛠 [김러키]에서 내려온 프로그래밍 참고 사항
⚙ 위 내용은 어떻게 코딩할 수 있을까요?
▼ [ 1단계 ] 프로그램에 필요한 기능들 생각해 보기
프로그램을 제작하기 전 **어떠한 기능**들이 있는지 생각해 봅니다. **기능 구현 난이도**를 생각하며 정렬해 봅시다.
#기능호출 #기능선택 #프로그램종료 #매장등록 #주문 #별점등록 #별점확인
▼ [ 2단계 ] 프로그램에 필요한 메서드 정의 및 기능에 따른 클래스 분할
- 1단계에서 정의한 기능들을 최대한 세분화하여 메서드를 정의하고 이를 클래스별로 묶어 볼 수 있습니다.
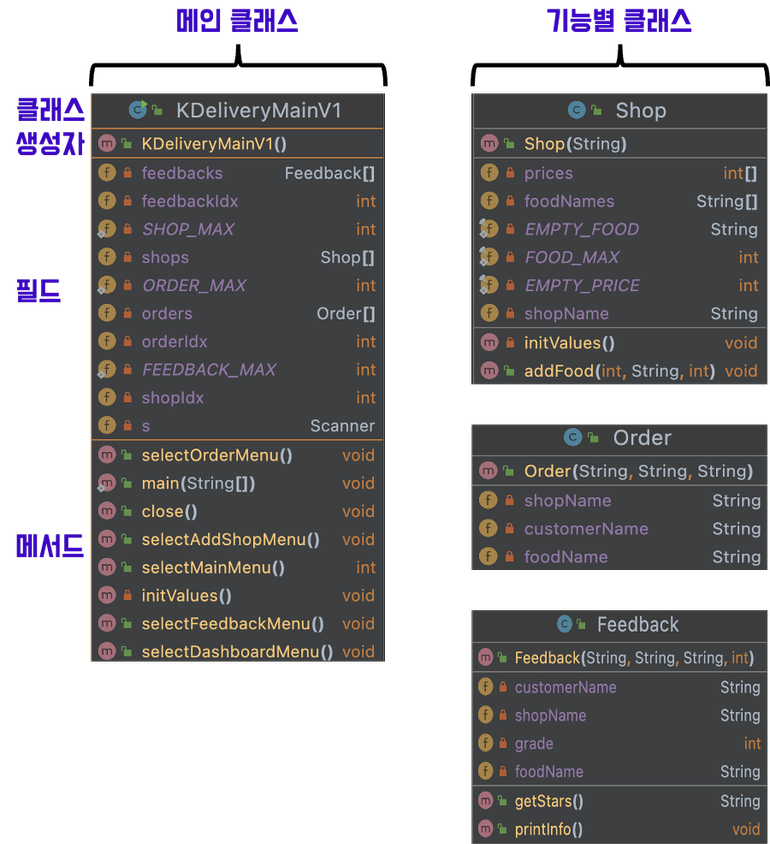
▼ [ 3단계 ] 프로그램의 진행 순서 생각해 보기

✏️ switch 코드의 가독성을 높여라
- 좋은 코드는 프로그래머의 실력을 의미하며 코드를 만드는 사람뿐만 아니라 코드를 읽는 사람에게도 좋은 영향을 줍니다. 코드의 내용을 읽기 쉽고 그 목적을 분명하게 파악할 수 있도록 합니다. switch 문은 if 문을 용도에 맞게 변형한 형태입니다. 특정한 상황에서 if 조건문을 좀 더 깔끔하게 만들 수 있습니다.
조건문의 다수 중첩 혹은 삼항 연산자 등 코드가 불필요하게 길어지는 경우 오히려 switch 문을 사용하는 것이 가독성과 이해의 측면에서 유리할 수 있습니다.
⚙ 기능별로 묶인 .java
- 순서도를 살펴보면 프로그램이 제시하는 기능별로 파일이 분할되어 있음을 알 수 있습니다. 이러한 경우 메인 파일에는 프로그램의 전체적인 진행과 종료를, 그 외의 파일에는 기능별 메서드를 정의할 수 있습니다.
- 프로그램의 진행도를 그리는 것이 귀찮더라도 꼭 자신의 손으로 프로그램의 진행 상황을 그려보는 것을 권해드립니다.