
평가 과제
💡 편의점 발주 프로그램 만들기 본 예제는 편의점, 음식점, 카페 등 저장 공간을 가지고 있는 곳이라면 자유롭게 사용할 수 있는 발주 프로그램을 제작하여 봅니다. 해당 프로그램은 물건을 등록하거나 빼는 등의 기본적인 기능만을 갖도록 합니다. (※ 반드시 객체 지향을 알아야만 JAVA로 프로그램을 짤 수 있는 것은 아닙니다. 기본 타입, 제어문, 함수, String을 활용해 작은 프로그램을 만들 수 있습니다. )
Ref
package com.ref; // 패키지 선언, 해당 클래스를 com.choongang 패키지에 속하게 합니다.
import java.util.Scanner;
public class MyStorageRef {
// 'EMPTY'는 빈 제품 위치를 나타내는 상수로, '등록 가능' 문자열을 저장하고 있습니다.
public final static String EMPTY = "등록 가능";
// product는 현재 등록된 제품을 저장하는 배열입니다.
static String[] products = new String[]{EMPTY,EMPTY,EMPTY,EMPTY,EMPTY};
// counts는 제품의 수량을 저장하는 배열입니다.
static int[] counts = new int[]{0, 0, 0, 0, 0};
/**
* 메뉴 옵션을 화면에 표시하는 메서드입니다.
* 반환 타입은 void로, 별도의 반환 값이 없습니다.
*/
public static void showMenu(){
System.out.println("1. 물건 정보(제품명) 등록하기");
System.out.println("2. 물건 정보(제품명) 등록 취소하기");
System.out.println("3. 물건 넣기 (제품 입고)");
System.out.println("4. 물건 빼기 (제품 출고)");
System.out.println("5. 재고 조회");
System.out.println("6. 프로그램 종료");
System.out.println("-".repeat(30)); // '-' 문자를 30번 반복하여 줄을 그어 메뉴 구분을 명확하게 합니다.
}
/**
* 사용자로부터 선택된 메뉴 번호를 입력 받아 반환하는 메서드입니다.
* @param s Scanner 객체, 사용자로부터 입력을 받기 위해 사용됩니다.
* @return int 메뉴 번호를 정수 형태로 반환합니다.
*/
public static int selectMenu(Scanner s){
System.out.print("[System] 원하는 기능의 번호를 입력하세요 : ");
int select = Integer.parseInt(s.nextLine()); // 사용자로부터 정수 입력을 받아 변수 select에 저장합니다.
return select; // 입력 받은 정수를 반환합니다.
}
/**
* 제품을 등록하는 메서드입니다.
* @param s Scanner 객체, 사용자로부터 제품명 입력을 받기 위해 사용됩니다.
* 반환 타입은 void로, 별도의 반환 값이 없습니다.
* 제품의 이름을 입력받아, products 배열에 할당합니다.
*/
static void prod_input(Scanner s){
// 제품 등록 로직을 구현합니다. 제품명을 입력받아 빈 배열 위치에 저장합니다.
// TODO:
// 입력 이전 메시지 출력
System.out.print("[시스템] 제품 등록을 원하는 제품명을 입력하세요 : ");
// 제품명 입력 받음
String input = s.nextLine();
int findEmptyIndex = -1;
boolean isExistProduct = false;
// 상품 배열을 순회하면서
for (int i = 0; i < products.length; i++) {
if (products[i].equals(EMPTY) && findEmptyIndex == -1) {
findEmptyIndex = i;
}
if (products[i].equals(input)) {
isExistProduct = true;
}
}
// 끝까지 순회했는데, 빈 공간을 만나지 못한다면 저장하지 않고 종료
if (findEmptyIndex == -1) {
System.out.println("[시스템] 저장 공간이 가득 찼습니다.\n 더 이상 등록이 불가능합니다.");
return;
}
// 동일한 제품이 이미 있을때
if (isExistProduct) {
System.out.println("[시스템] 동일한 제품이 이미 보관중입니다.");
return;
}
// 빈 공간을 민나면 해당 장소에 입력받은 상품 적재 (배열에 문자열 할당)
products[findEmptyIndex] = input;
counts[findEmptyIndex] = 0;
//등록이 완료되었다면 메시지 출력
System.out.println("[시스템] 등록이 완료되었습니다. \n [시스템] 현재 등록된 제품 목록");
for (String product : products) {
System.out.println("> " + product);
}
System.out.println("-".repeat(35));
}
/**
* 제품 등록을 취소하는 메서드입니다.
* @param s Scanner 객체, 사용자로부터 취소할 제품명 입력을 받기 위해 사용됩니다.
* 반환 타입은 void로, 별도의 반환 값이 없습니다.
* 제품의 이름을 입력받아, products의 배열에서 요소를 초기화합니다 ("등록 가능"으로 변경)
* 해당 제품의 수량도 0으로 변경해야 합니다. (counts 배열의 같은 index의 값을 0으로 변경합니다)
*/
static void prod_remove(Scanner s){
// 제품 등록 취소 로직을 구현합니다. 입력받은 제품명에 해당하는 배열 요소를 EMPTY로 설정합니다.
// TODO:
// 입력 받기 전 메시지를 출력
System.out.print("[시스템] 등록된 제품 중 취소를 원하는 제품명을 입력해 주세요 : ");
// 입력된 상품명을 저장 (변수에 할당)
// 제품명 입력 받음
String input = s.nextLine();
// 상품 배열을 순회하며 각 요소 중 입력된 상품명과 동일한 상품이 있는지 찾아야 합니다. (순회)
int findProductIndex = -1;
for (int i = 0; i < products.length; i++) {
// 같은 상품이 있다면
if(input.equals(products[i])) {
findProductIndex = i;
break;
}
}
// 모두 순회했는데 같은 상품이 없다면
if (findProductIndex == -1) {
// 상품을 찾을 수 없다는 메시지 출력
System.out.println("[시스템] 등록된 제품을 찾을 수 없습니다. \n제품명을 다시 확인해 주세요.");
// 아무것도 하지 않고 메서드 종료
return;
}
// 해당 상품 배열의 요소를 "등록 가능"으로 수정
String tempProduct = products[findProductIndex];
products[findProductIndex] = EMPTY;
counts[findProductIndex] = 0;
// 취소 성공 메시지 출력
System.out.printf("[시스템] %s 취소가 완료되었습니다.", input);
// 남은 상품 리스트 출력
for (String product : products) {
System.out.println("> " + product);
}
System.out.println("-".repeat(35));
}
/**
* 제품 수량을 증가시키는 메서드입니다.
* @param s Scanner 객체를 통해 사용자로부터 제품명과 수량 입력을 받습니다.
* products 배열에서 입력받은 요소를 찾아내어. counts 배열에서 해당 제품의 수량을 입력받은 수 만큼 증가시킵니다.
* 반환 타입은 void로, 별도의 반환 값이 없습니다.
*/
public static void prod_amount_add(Scanner s) {
System.out.println("[System] 물건의 수량을 추가합니다.(입고)");
System.out.print("[System] 수량을 추가할 제품명을 입력하세요 : ");
String input = s.nextLine(); // 제품명 입력 받기
int foundIdx = -1; // 찾은 인덱스 초기화
for (int i = 0; i < products.length; ++i){
if (input.equals(products[i])){ // 입력한 제품명과 일치하는 제품을 찾으면
foundIdx = i; // 인덱스 저장
break; // 반복 중단
}
}
if (foundIdx < 0){ // 제품을 찾지 못한 경우
System.out.println("[Warning] 입력한 제품명이 없습니다. 다시 확인하여 주세요.");
return;
}
System.out.print("[System] 추가할 수량을 입력해주세요 : ");
String addNum = s.nextLine();
// 숫자가 아닌 경우, 에러 메시지를 출력해야 합니다. (유효성 검증)
// TODO:
/**
* 아래는 예외처리 V1입니다. 메서드를 통해 예외처리를 위한 기능 구현 후 사용
*/
// String inputStr = s.nextLine();
// if (!isValidNumber(inputStr)) {
// System.out.println("[에러] 수량은 숫자로 입력해야 합니다.");
// return;
// }
//
// int cnt = Integer.parseInt(addNum); // 수량 입력 받기
/**
* 아래는 예외처리 V2입니다. try-catch를 활용한 예외처리, 예외 발생시 캐치하여 예외 메시지 출력 후, 종료
*/
try {
int cnt = Integer.parseInt(addNum); // 수량 입력 받기
counts[foundIdx] += cnt; // 제품의 수량을 증가
} catch (NumberFormatException e) {
System.out.println(e);
return;
}
System.out.println("[Clear] 정상적으로 제품의 수량 추가가 완료되었습니다.");
}
/**
* 제품 수량을 감소시키는 메서드입니다.
* @param s Scanner 객체를 통해 사용자로부터 제품명과 수량 입력을 받습니다.
* products 배열에서 입력받은 요소를 찾아내어.
* counts 배열에서 해당 제품의 수량을 입력받은 수 만큼 감소시킵니다.
* 반환 타입은 void로, 별도의 반환 값이 없습니다.
*/
public static void prod_amount_decrease(Scanner s) {
// 제품 수량 감축 로직을 구현합니다. 입력받은 수량만큼 해당 제품의 수량을 감소시킵니다.
// TODO:
// 출고를 위한 메시지 출력
System.out.println("[시스템] 제품의 출고를 진행합니다");
System.out.println("[시스템] 출고를 진행할 제품명을 입력해 주세요 : ");
// 출고할 상품명을 입력받음 (변수에 할당)
String input = s.nextLine();
int findProductIndex = -1;
// 출고할 상품이 존재하는 상품인지 확인하기 위해서 상품 배열을 순회
for (int i = 0; i < products.length; i++) {
// 찾았다면, 찾은 상품의 인덱스를 저장
if (products[i].equals(input)) {
findProductIndex = i;
break;
}
}
// 반복문이 모두 끝날 때까지 상품을 찾지 못했다면, 존재하지 않는 것으로
// 상품이 존재하지 않았다는 메시지 출력 후 종료
if (findProductIndex == -1) {
System.out.println("[시스템] 해당 상품을 찾을 수 없습니다.");
return;
}
// 상품을 찾았으므로, 출고를 위한 메시지를 출력
System.out.println("[시스템] 출고할 수량을 입력해 주세요 : ");
// 출고에 필요한 수량을 입력받아야 함(변수에 저장)
String inputStr = s.nextLine();
// 예외 1-2 수량이 숫자가 아닌 경우
// 예외메시지 출력 후, 메서드 종료
if (!isValidNumber(inputStr)) {
System.out.println("[시스템] 수량을 숫자만 입력해야 합니다.");
return;
}
int count = Integer.parseInt(s.nextLine());
// 예외 1-1 수량이 현재 재고보다 많다면, 출고할 수 없음
// 예외 메시지 출력 후, 메서드 종료
if (counts[findProductIndex] < count) {
System.out.println("[시스템] 현재 재고보다 많은 수량을 출고할 수 없습니다.");
return;
}
// 나머지는 출고가 가능한 경우 뿐이므로
// 제품의 수량을 줄이고
counts[findProductIndex] -= count;
// 출고 성공 메시지 출력
System.out.println("[시스템] 출고가 완료되었습니다.");
System.out.println("[Clear] 정상적으로 제품의 수량 감소가 완료되었습니다.");
}
/**
* 등록된 모든 제품의 목록과 수량을 출력하는 메서드입니다.
* 반환 타입은 void로, 별도의 반환 값이 없습니다.
*/
static void prod_search(){
System.out.println("[System] 현재 등록된 물건 목록 ▼");
for (int i = 0; i < products.length; ++i){
System.out.println("> " + products[i] + " : " + counts[i] + "개");
}
}
/**
* 프로그램의 메인 메서드로, 프로그램의 실행 시작점입니다.
*/
public static void main(String[] args){
System.out.println("[Item_Storage]");
System.out.printf("[System] 점장님 어서오세요.\n[System] 해당 프로그램의 기능입니다.\n");
Scanner s = new Scanner(System.in);
while (true){
showMenu();
int menu = selectMenu(s); // 메뉴 선택을 받습니다.
if(menu == 6){ // '프로그램 종료' 선택 시
System.out.println("[System] 프로그램을 종료합니다.");
break; // 반복문을 종료하고 프로그램을 종료합니다.
}
// 선택된 메뉴에 따라 해당 기능을 실행합니다.
switch (menu){
case 1:
prod_input(s);
break;
case 2:
prod_remove(s);
break;
case 3:
prod_amount_add(s);
break;
case 4:
prod_amount_decrease(s);
break;
case 5:
prod_search();
break;
default:
System.out.println("[System] 시스템 번호를 다시 확인하여 주세요.");
}
}
s.close(); // Scanner 객체를 닫습니다.
}
private static boolean isValidNumber(String inputStr) {
if (inputStr.equals("")) {
return false;
}
String numbers = "0123456789";
char[] charArr = inputStr.toCharArray();
for (int i = 0; i < charArr.length; i++) {
if (numbers.indexOf(charArr[i]) == -1) {
return false;
}
}
return true;
}
}Database Management System
데이터베이스
1. 데이터베이스의 정의
데이터베이스는 다양한 데이터를 체계적으로 저장하고 관리할 수 있게 도와주는 컴퓨터 시스템입니다. 생활 속에서 정보를 쉽고 빠르게 찾아보고, 사용할 수 있도록 하는 도구라고 생각하면 됩니다.
예를 들어, 웹사이트, 온라인 쇼핑몰, 은행 시스템, 병원 등 다양한 곳에서 데이터베이스를 활용합니다.
데이터베이스의 주요 특징:
- 데이터 중복 방지: 같은 정보를 여러 번 저장하지 않고 한번만 저장하여 저장 공간을 절약하고, 데이터를 관리하기 쉽게 합니다.
- 데이터 무결성 유지: 정보의 정확성과 일관성을 유지해 신뢰할 수 있는 정보를 제공합니다. 예를 들어, 고객의 주소가 변경되면 모든 기록에서 주소를 일관되게 갱신해야 합니다.
- 데이터 검색 및 조작: 필요한 정보를 쉽고 빠르게 찾아볼 수 있고, 수정하거나 업데이트하는 등의 작업을 할 수 있습니다.
- 데이터 공유: 여러 사람이 동시에 같은 데이터를 볼 수 있고, 함께 사용할 수 있습니다.
2. 기존의 파일 시스템과 데이터베이스의 차이
파일 시스템은 데이터를 단순한 파일 형태로 저장하며, 이는 데이터를 찾거나 관리할 때 비효율적입니다. 데이터의 중복이 발생하기 쉽고, 데이터가 서로 일치하지 않는 문제가 자주 발생합니다.
반면, 데이터베이스는 데이터를 테이블 형식으로 저장하여 체계적인 관리가 가능하고, 데이터를 효율적으로 검색할 수 있습니다. 또한, 데이터의 정확성을 유지하기 위한 다양한 기술을 사용하여 데이터 무결성을 쉽게 유지할 수 있습니다.
구분 파일 시스템 데이터베이스

3. 데이터란?
데이터는 사실이나 수치와 같이 형태가 구체적으로 정의된 정보를 의미합니다. 데이터는 숫자, 문자, 이미지, 음성, 비디오 등 다양한 형태로 존재할 수 있습니다.
데이터의 예시:
- 숫자: 나이, 키, 몸무게, 온도, 가격 등
- 문자: 이름, 주소, 전화번호, 이메일 주소 등
- 이미지: 사진, 그림 등
- 음성: 음악, 음성 메시지 등
- 비디오: 영화, 드라마 등
데이터는 센서, 기기, 사람 등 다양한 방법으로 수집될 수 있으며, 의사 결정, 보고, 분석, 마케팅 등 여러 목적으로 활용될 수 있습니다.
4. 데이터베이스 매니지먼트 시스템(DBMS)
- 데이터베이스 매니지먼트 시스템(DBMS)은 데이터베이스를 만들고, 관리하며 사용할 수 있도록 도와주는 소프트웨어입니다. 이 시스템을 사용함으로써 데이터를 효과적으로 저장하고, 안전하게 보호하며, 필요할 때 쉽게 접근할 수 있습니다.
DBMS의 주요 기능:
- 데이터 저장 및 관리: 데이터를 안전하고 체계적으로 저장하고 관리합니다.
- 데이터 검색 및 조작: 사용자가 데이터를 쉽게 찾아서 필요한 작업을 수행할 수 있도록 도와줍니다.
- 데이터 보안: 무단 접근으로부터 데이터를 보호합니다.
- 데이터 백업 및 복구: 데이터가 손실되었을 때 복구할 수 있습니다.
- 데이터 동기화: 여러 사용자가 동시에 데이터를 사용하고 변경할 수 있도록 합니다.
대표적인 DBMS:
- MySQL: 웹 개발에 주로 사용되는 오픈 소스 데이터베이스입니다.
- Oracle: 기업 환경에서 선호되는 고성능 데이터베이스입니다.
- Microsoft SQL Server: 주로 윈도우 환경에서 사용되는 데이터베이스입니다.
- PostgreSQL: 객체 관계형 데이터 모델을 지원하는 고급 데이터베이스입니다.
5. 일상생활에서 접할 수 있는 데이터베이스
일상생활 속에서 데이터베이스는 가계부, 전화번호부, 주소록, 일정 관리, 음악 플레이어, 사진 앨범, 온라인 쇼핑몰, 은행, 병원 등 다양한 형태로 존재합니다. 이러한 도구들은 우리가 정보를 저장하고, 관리하며, 필요할 때 쉽게 찾을 수 있도록 도와줍니다.
데이터베이스의 특징
1. 통합 데이터 (Integrated Data)
데이터베이스는 관련 있는 정보를 모아 체계적으로 구성합니다. 예를 들어, 학교 데이터베이스에는 학생, 교수, 과목 등에 대한 데이터가 모두 포함되어 있어 서로 관련된 정보를 통합적으로 관리할 수 있습니다. 이를 통해 중복을 최소화하고 일관성을 유지할 수 있습니다.
2. 저장 데이터 (Stored Data)
데이터베이스는 데이터를 안전하게 저장하고 유지하는 데 사용됩니다. 이 데이터는 디지털 형태로 저장되며, 필요할 때 언제든지 접근할 수 있습니다. 저장된 데이터는 장기간 보존되며, 예를 들어 고객 정보나 거래 내역 같은 중요한 비즈니스 데이터가 이에 해당합니다.
3. 공유 데이터 (Shared Data)
데이터베이스의 데이터는 여러 사용자가 동시에 접근하고 사용할 수 있습니다. 예를 들어, 병원의 의료진은 같은 환자에 대한 정보를 공유하며, 다양한 부서에서 동시에 접근하여 환자 관리에 사용할 수 있습니다.
4. 운영 데이터 (Operational Data)
데이터베이스에 저장된 데이터는 조직의 일상적인 운영을 지원하는 데 필요한 현재의, 관련성 높은 데이터입니다. 이는 예를 들어, 일일 판매 데이터, 재고 상태, 현재 진행 중인 업무 등 실시간으로 업데이트되고 사용됩니다.
5. 실시간 접근 (Real-time Access)
데이터베이스는 실시간으로 데이터에 접근할 수 있는 기능을 제공합니다. 이는 사용자가 데이터를 요청할 때 지연 없이 즉시 정보를 검색하고 제공받을 수 있음을 의미합니다. 예를 들어, 은행에서 계좌 잔액을 확인할 때 실시간으로 업데이트된 정보를 볼 수 있습니다.
6. 계속 변화 (Continuous Change)
데이터베이스는 지속적으로 업데이트되고 수정됩니다. 데이터의 추가, 수정, 삭제 등이 지속적으로 이루어지며, 이는 데이터가 항상 최신 상태를 유지하고, 사용자의 요구사항에 신속하게 대응할 수 있도록 합니다.
7. 내용 기반 참조 (Content-based Reference)
데이터베이스에서는 데이터를 위치가 아닌 내용에 따라 참조할 수 있습니다. 즉, 특정 데이터의 물리적인 위치를 몰라도 그 내용을 기반으로 검색하고 접근할 수 있습니다. 예를 들어, '홍길동'이라는 이름을 가진 고객의 정보를 이름으로 검색하여 찾을 수 있습니다.
8. 계속 공유 (Continuous Sharing)
데이터베이스의 데이터는 여러 사용자와 어플리케이션 사이에서 동시에 공유되며, 이는 데이터의 일관성과 효율성을 유지하는 데 도움을 줍니다. 예를 들어, 같은 회사의 다른 부서에서 동일한 고객 데이터에 접근해 각각 다른 업무를 수행할 수 있습니다.
데이터 모델링의 이해
데이터 모델링이란
데이터 모델링은 데이터를 어떻게 저장, 관리, 조직할지를 정의하는 과정입니다. 이 과정을 통해 데이터와 그 데이터 간의 관계를 시각적인 모델로 표현하게 됩니다. 데이터 모델링의 목적은 데이터 구조를 체계적으로 설계하여, 데이터의 정확성, 접근성, 효율성을 극대화하는 데 있습니다.
데이터 모델링의 기본 개념을 학습하고, 이를 통해 데이터의 구조를 어떻게 설계하는지 이해합니다.
- 학습 목표:
- 데이터 모델링의 개념과 중요성을 이해합니다.
- 다양한 예제를 통해 실제 데이터 모델링 과정을 배웁니다.
데이터 모델링
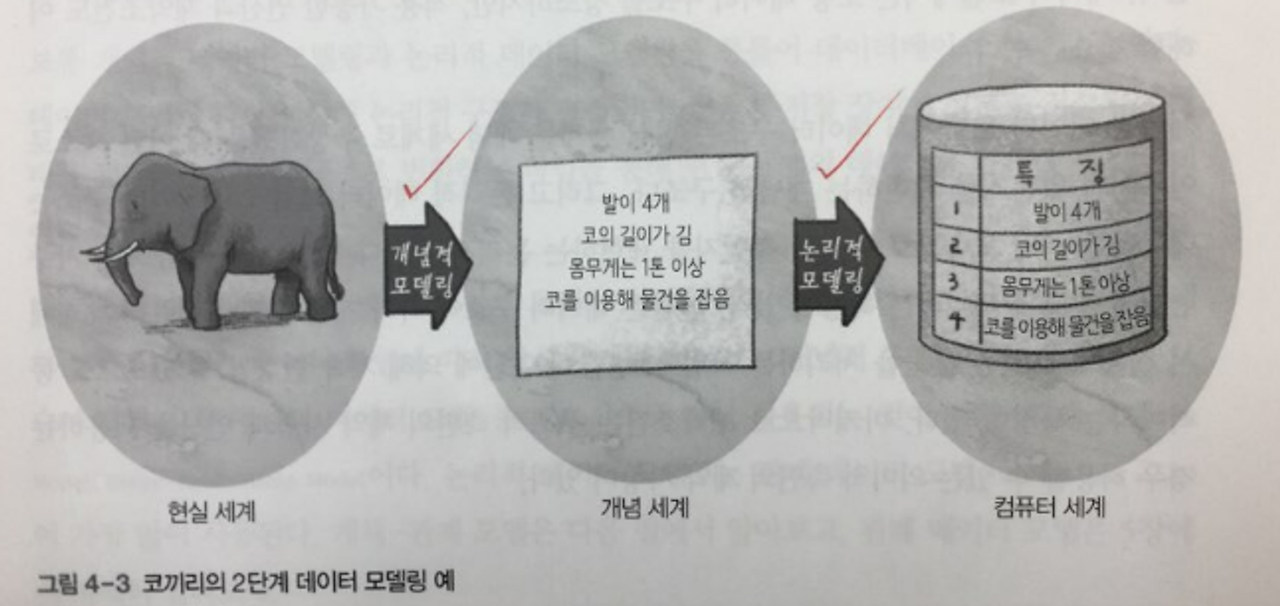
1. 데이터 모델링의 개념
- 정의: 데이터 모델링은 데이터를 시스템 내에서 어떻게 저장하고 조직할지에 대한 추상적 모형을 만드는 과정입니다.
- 구성 요소:
- 엔티티(Entity): 데이터베이스에 저장되는 주요 데이터 요소.
- 속성(Attribute): 엔티티를 설명하는 세부 사항.
- 관계(Relationship): 엔티티 간의 연결 또는 관계.
추상화, 단순화, 명확화
- 모델링이란 복잡한 현실 세계를 단순화시켜 표현하는 것
- 추상화는 현실 세계를 일정한 형식에 맞추어 표현을 한다는 의미
- 단순화는 복잡한 현실 세계를 약속된 규약에 의해 제한된 표기법이나 언어로 표현
- 명확화는 누구나 이해하기 쉽게 하기 위해 대상에 대한 애매모호함을 제거하고 정확하게 현상을 기술
데이터 모델링의 세 단계
- 학습 목표:
- 각 데이터 모델링 단계의 목적과 기능을 이해합니다.
- 실생활 및 실무 예제를 통해 각 단계의 적용을 학습합니다.

1. 개념적 데이터 모델링
정의: 가장 높은 수준의 모델링 단계로, 비즈니스 요구사항을 중심으로 구성됩니다. 주요 엔티티와 그 관계를 식별하고, 시스템의 전반적인 구조를 이해하기 위한 추상적인 모델을 생성합니다.
- 추상화 수준이 높고 업무 중심적이며 포괄적인 수준의 모델링
- 전사적 데이터 모델
- 핵심 엔터티와 그들 간의 관계를 발견하고, 그것을 표현하기 위해서 엔터티-관계 다이어그램을 생성하는 것.
2. 논리적 데이터 모델링
정의: 개념적 모델을 바탕으로, 데이터 모델을 특정 데이터베이스 관리 시스템(DBMS)에 맞게 조정합니다. 엔티티, 속성, 관계, 데이터 타입 등을 포함한 구체적인 구조를 설계합니다.
- 시스템으로 구축하고자 하는 업무에 대해 key, 속성, 관계 등을 정확하게 표현
- 재사용성이 높음
- 이 단계에서 하는 중요한 활동은 정규화
3. 물리적 데이터 모델링
정의: 논리적 모델을 바탕으로 실제 데이터베이스 구현을 위한 모델을 생성합니다. 성능 최적화, 저장 구조, 액세스 경로 등의 물리적인 특성을 고려합니다.
- 실제 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 설계
- 이 단계에서 결정되는 것 : 테이블, 칼럼 등으로 표현되는 물리적인 저장구조와 사용될 저장 장치, 자료를 추출하기 위해 사용될 접근 방법 등.
데이터 모델링의 유의점과 주의사항
1. 중복, 비유연성, 비일관성의 문제점
중복의 문제점
- 정의: 동일한 데이터가 시스템 내 여러 위치에 저장되는 현상입니다.
- 문제: 저장 공간의 낭비가 발생하며, 데이터를 업데이트 할 때 오류의 가능성이 증가합니다.
- 실무 예제: 병원 시스템에서 환자의 연락처 정보가 여러 의료부서의 데이터베이스에 중복 저장되어 있습니다. 환자가 연락처를 변경할 경우, 모든 부서의 데이터베이스를 일일이 찾아서 갱신해야 하며, 일부를 놓칠 경우 정보의 불일치가 발생할 수 있습니다.
비유연성의 문제점
- 정의: 데이터 모델이 비즈니스 요구 사항의 변화에 적응하지 못하는 상태입니다.
- 문제: 시스템의 확장성과 유지보수성이 저하되어, 비즈니스의 성장을 방해할 수 있습니다.
- 실생활 예제: 소매점의 제품 데이터베이스에서, 새로운 제품 카테고리(예: 전자제품)를 추가할 경우, 기존의 데이터베이스 설계가 이를 지원하지 않아 전체 시스템의 구조를 변경해야 할 수 있습니다. 이는 시간과 비용을 많이 소모하는 작업입니다.
비일관성의 문제점
- 정의: 서로 다른 정보 소스 간에 데이터가 일치하지 않는 상태입니다.
- 문제: 데이터의 신뢰성이 저하되며, 잘못된 정보에 기반한 결정을 내릴 위험이 있습니다.
- 실무 예제: 회사에서 직원의 급여 정보가 인사 부서와 회계 부서에서 다르게 관리되고 있습니다. 인사 부서에서는 최근 인상된 급여 정보를 업데이트 했지만, 회계 부서는 이를 업데이트하지 않아 급여 지급에 오류가 발생할 수 있습니다.
2. 데이터 모델링의 파급효과
- 정의: 데이터 모델링은 시스템의 데이터 구조를 설계하는 과정입니다. 이 과정에서 발생하는 결정들이 시스템 전반에 미치는 부정적인 영향을 말합니다.
- 중요성: 초기 설계 오류는 나중에 수정하기 어렵고 비용이 많이 들기 때문에 데이터 모델은 매우 중요합니다.
- 실무 예제: 국제 택배 회사에서 패키지 추적 시스템을 구축할 때, 데이터 모델에 패키지 위치 업데이트 간격이 너무 길게 설정되어 실시간 위치 추적이 어렵습니다. 이로 인해 고객 서비스 향상에 제한을 받고, 수정에 많은 비용이 발생하게 됩니다.
3. 데이터 품질과의 관계
- 정의: 데이터 품질은 데이터의 정확성, 일관성, 시기적절성, 완전성을 포함하여 데이터가 얼마나 유용한지를 나타내는 특성입니다.
- 중요성: 높은 데이터 품질은 신뢰할 수 있는 의사결정과 효율적인 비즈니스 운영을 보장합니다.
- 실생활 예제: 고객 서비스 센터에서 최신의 정확한 고객 데이터를 유지하는 것이 중요합니다. 고객의 최근 문의 사항이나 불만 사항이 잘 기록되고 관리되어야, 상담 직원이 빠르고 정확하게 문제를 해결할 수 있습니다.
데이터베이스 3단계 구조


두 영역의 데이터 독립성

사상 (Mapping)

Entity
Entity의 개념
- Entity는 사람, 장소, 물건, 사건, 개념 등의 명사에 해당한다.
- Entity는 업무상 관리가 필요한 관심사에 해당한다.
- Entity는 저장이 되기 위한 어떤 것(Thing)이다.

적절한 Entity의 특징
업무에서 필요로 하는 정보여야 한다.
- Entity는 반드시 시스템을 구축하고자 하는 업무에서 필요로 하고 관리하고자 하는 정보여야만합니다. 예를 들어 환자라는 Entity는 병원에 있어 반드시 필요한 Entity이지만 일반 회사에서는 전혀 필요가 없는 Entity입니다.

Entity는 유일한 식별자가 있어야 한다.
- 어떤 Entity에 업무적으로 의미를 가지는 인스턴스가 식별자에 의해 한 개씩만 존재하는지 검증해 보아야 합니다. 일반적으로 회사의 직원들을 구분할 수 있는 방법은 이름이나 사원번호로 구분할 수 있습니다. 하지만 이름의 경우에는 동명이인이 될 수 있으므로 유일하게 식별될 수 없겠죠. 즉. 사원번호는 회사에 입사한 사람에게 고유하게 부여된 번호이므로 유일한 식별자가 될 수 있는 것입니다.
- 예) 회원 ID, 계좌번호

두 개 이상의 인스턴스의 집합이어야 한다.
- 영속적으로 존재하는 인스턴스의 집합이 되어야 합니다. 여기서 집합은 한 개가 아니라 반드시 두 개 이상일 때 집합이라고 합니다.
- 예) 고객정보는 2명 이상 있어야 한다.
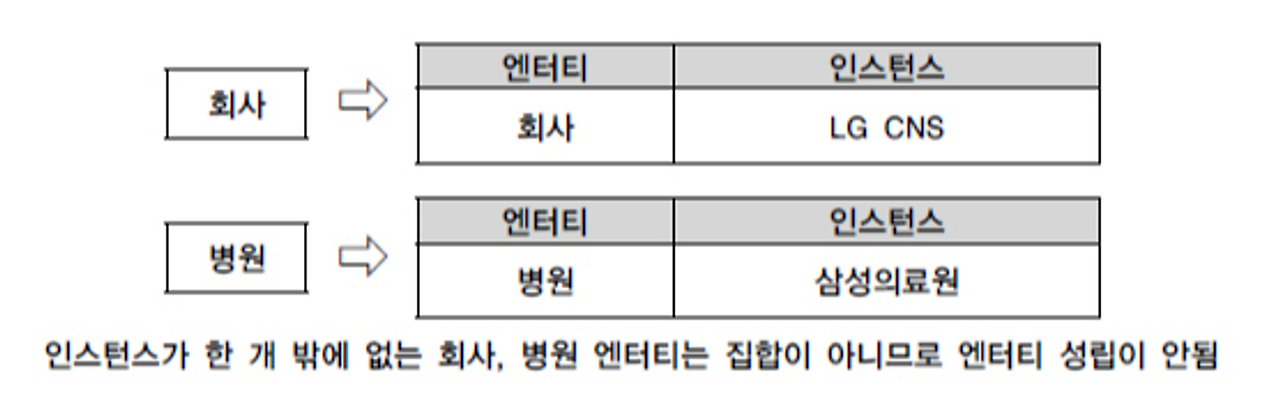
업무 프로세스에 의해 이용되어야 한다.
- 이 Entity가 필요하다고 생각하여 만들었는데 업무 프로세스에 의해 전혀 사용되지 않는다면 어떻게 해야 할까요? 이는 업무 분석, 업무 프로세스 도출이 적절히 이루어지지 않았음을 뜻합니다. 아래 그림과 같이 고립된 Entity의 경우는 Entity를 제거하거나 아니면 누락된 프로세스가 존재하는지 살펴보고 해당 프로세스를 추가해야 합니다.
- 예) 은행 시스템에는 고객, 계좌 Entity가 필요하고 학생이라는 Entity는 필요하지 않음

반드시 1개 이상의 속성을 포함해야 한다.
- 속성을 포함하지 않는 Entity는 있어도 의미가 없습니다. 이런 Entity는 관계가 생략되어 있거나 업무 분석이 미진하여 속성 정보가 누락되는 경우에 주로 발생합니다. 마찬가지로 주식별자만 존재하고 일반속성은 전혀 없는 경우도 마찬가지로 적절한 Entity라고 할 수 없습니다. 단, 예외적으로 관계 Entity(Associative Entity)의 경우에만 주식별자 속성만 가지고 있어도 엔터티로 인정할 수 있습니다.
- 예) 고객 Entity에는 회원 ID, 패스워드, 이름, 주소 전화번호의 속성이 존재한다.

다른 Entity와 관계를 가져야 한다.
- Entity는 다른 Entity와 최소 한 개 이상의 관계가 존재해야 합니다. 기본적으로 Entity가 도출되었다는 것은 해당 업무 내에서 업무적인 연관성(존재적 연관성, 행위적 연관성)을 가지고 다른 Entity와의 연관의 의미를 가지고 있음을 나타냅니다.
- 예) 고객은 계좌를 개설한다.

Entity의 분류

유무형에 따른 분류 - 물리적 형태가 존재하는가?

발생 시점에 따른 분류 - 언제 발생되는가?

Entity의 명명법
1. 가능하면 현업 업무에서 사용하는 용어를 사용한다.
2. 가능하면 약어를 사용하지 않는다.
3. 단수 명사를 사용한다.
4. 모든 Entity에서 유일한 이름을 부여해야 한다.
5. Entity 생성 의미에 맞는 이름을 부여해야 한다.
속성
속성의 개념
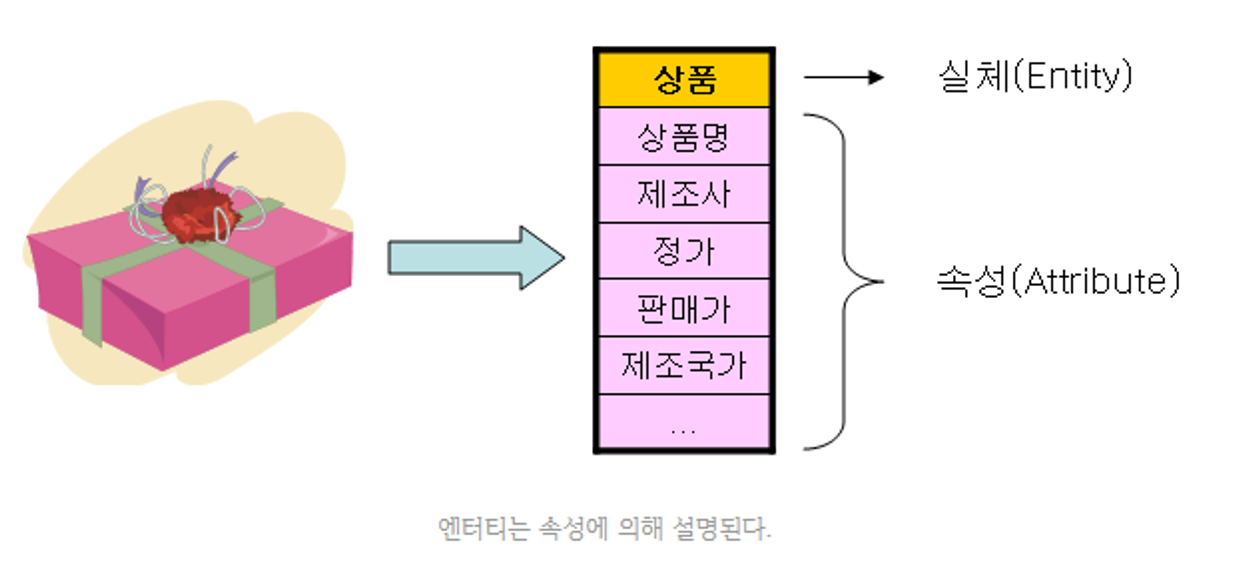
- 업무에서 필요로 한다.
- 의미상 더 이상 분리되지 않는다.
- 엔터티를 설명하고 인스턴스의 구성 요소가 된다.
엔터티, 인스턴스, 속성, 속성값의 관계
- 한 개의 엔터티는 두 개 이상의 인스턴스의 집합이어야 한다.
- 한 개의 엔터티는 두 개 이상의 속성을 갖는다.
- 한 개의 속성은 한 개의 속성값을 갖는다.
속성 설계시 고려사항
엔터티에 필요한 속성인가??

엔터티에 꼭 필요한 속성만을 구성하도록 합니다. 예를 들어 학생이라는 엔터티 안에 과목 번호라는 속성 값이 들어가 있으면 학생이라는 엔터티의 개념이 모호해집니다. 학생이라는 속성에는 과목 번호가 아닌 학번이라는 속성이 들어가야 합니다.
속성이 하나의 값만을 가지고 있는가?

- 엔티티 타입 내에서 하나의 속성은 한 시점에 한 개의 값만을 가져야 합니다. 하지만 위의 "방문 고객"이라는 테이블의 속성을 보시면 고객의 방문 횟수에 따라 방문시간, 방문 목적의 속성의 값에 여러 가지 값이 들어가고 있습니다. 이렇게 여러 개의 값이 들어가는 속성을 다중값 속성이라고 하며 이럴 경우에는 새로운 엔티티를 생성해서 다중 값을 없애야 합니다.
- 예) 한 고객이 여러 번 방문한 방문일, 방문 내용을 관리해야 합니다.
속성이 하나의 의미만 가지고 있는가?
- 속성은 단 하나의 독립적인 의미를 가지고 있어야 합니다. 여러 개의 속성을 통합하여 하나의 의미를 가지는 것을 지양해야 합니다.
- 예) 주민번호 = 주민번호 1 + 주민번호 2
- → 주민등록번호 전체만이 의미가 있으므로 분리해서는 안됩니다.
동일한 의미를 가지는 속성이 하나만 존재하는가?

속성의 분류
특성에 따른 분류
- 기본속성 : 업무분석을 통해 바로 정의한 속성
- 설계속성 : 원래 업무상 존재하지는 않지만 설계를 하면서 도출해내는 속석
- 파생속성 : 다른 속성으로부터 계산이나 변형이 되어 생성되는 속성

엔터티 구성방식에 따른 분류
- PK속성 : 엔터티를 식별할 수 있는 속성
- FK속성 : 다른 엔터티와의 관계에서 포함된 속성
- 일반속성 : PK, FK에 포함되지 않은 속성

도메인 (Domain)
- 각 속성은 가질 수 있는 값의 범위가 있는데 이를 그 속성의 도메인이라고 합니다.
- 학생이라는 엔터티가 있을 때 학점이라는 속성의 도메인은 0.0에서 4.5사이의 실수 값이며 주소라는 속성의 도메인은 길이가 20자리 이내인 문자열로 정의할 수 있습니다.
속성의 명명
- 해당 업무에서 사용하는 이름을 부여한다.
- 서술식 속성명은 가급적 사용하지 않는다.
- 약어 사용은 가급적 제한한다.
- 전체 데이터모델에서 유일성을 확보하는 것이 좋다.
이미지 출처 : https://coding-factory.tistory.com